 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Robust Deep Joint Source-Channel Coding for Semantic Communications
Apr 06, 2026Semantic communications (SCs) aim to transmit only the essential information required to perform given tasks, thereby improving communication efficiency. Deep learning-based joint source-channel coding (deep JSCC) has emerged as a promising approach for SC systems; however, its performance often degrades when the deployment channels differ from the training channel conditions, making robustness a critical requirement. This paper presents a structured overview of recent methodologies for enhancing the robustness of deep JSCC. Specifically, existing approaches are categorized into two classes: robust training approaches and adaptive approaches, with the latter further divided into adaptive semantic feature selection, physical-layer adaptation, and semantic feature adaptation. Finally, we discuss promising directions, including multi-task generalization and explainability in robust SC systems.
Multipoint Code-Weight Sphere Decoding: Parallel Near-ML Decoding for Short-Blocklength Codes
Feb 09, 2026Ultra-reliable low-latency communications (URLLC) operate with short packets, where finite-blocklength effects make near-maximum-likelihood (near-ML) decoding desirable but often too costly. This paper proposes a two-stage near-ML decoding framework that applies to any linear block code. In the first stage, we run a low-complexity decoder to produce a candidate codeword and a cyclic redundancy check. When this stage succeeds, we terminate immediately. When it fails, we invoke a second-stage decoder, termed multipoint code-weight sphere decoding (MP-WSD). The central idea behind {MP-WSD} is to concentrate the ML search where it matters. We pre-compute a set of low-weight codewords and use them to generate structured local perturbations of the current estimate. Starting from the first-stage output, MP-WSD iteratively explores a small Euclidean sphere of candidate codewords formed by adding selected low-weight codewords, tightening the search region as better candidates are found. This design keeps the average complexity low: at high signal-to-noise ratio, the first stage succeeds with high probability and the second stage is rarely activated; when it is activated, the search remains localized. Simulation results show that the proposed decoder attains near-ML performance for short-blocklength, low-rate codes while maintaining low decoding latency.
Efficient Softmax Reformulation for Homomorphic Encryption via Moment Generating Function
Feb 02, 2026Homomorphic encryption (HE) is a prominent framework for privacy-preserving machine learning, enabling inference directly on encrypted data. However, evaluating softmax, a core component of transformer architectures, remains particularly challenging in HE due to its multivariate structure, the large dynamic range induced by exponential functions, and the need for accurate division during normalization. In this paper, we propose MGF-softmax, a novel softmax reformulation based on the moment generating function (MGF) that replaces the softmax denominator with its moment-based counterpart. This reformulation substantially reduces multiplicative depth while preserving key properties of softmax and asymptotically converging to the exact softmax as the number of input tokens increases. Extensive experiments on Vision Transformers and large language models show that MGF-softmax provides an efficient and accurate approximation of softmax in encrypted inference. In particular, it achieves inference accuracy close to that of high-depth exact methods, while requiring substantially lower computational cost through reduced multiplicative depth.
Collaborative Edge-to-Server Inference for Vision-Language Models
Dec 18, 2025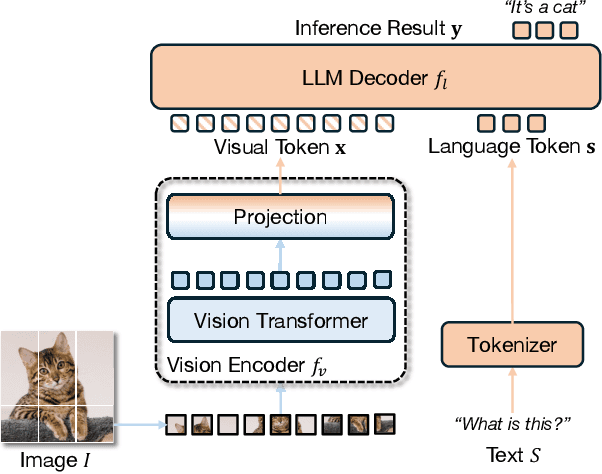


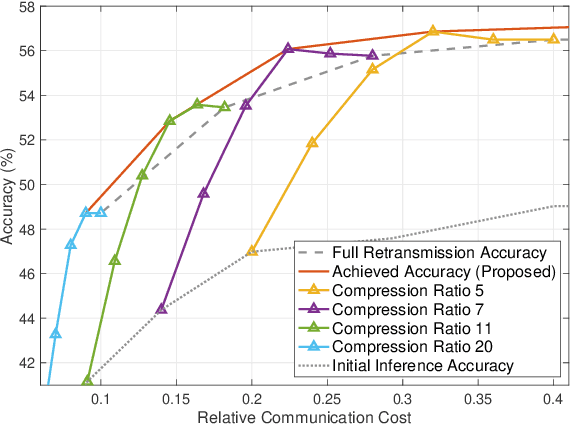
We propose a collaborative edge-to-server inference framework for vision-language models (VLMs) that reduces the communication cost while maintaining inference accuracy. In typical deployments, visual data captured at edge devices (clients) is transmitted to the server for VLM inference. However, resizing the original image (global image) to match the vision encoder's input resolution often discards fine-grained details, leading to accuracy degradation. To overcome this limitation, we design a two-stage framework. In the first stage, the server performs inference on the global image and identifies a region of interest (RoI) using the VLM's internal attention. The min-entropy of the output tokens is then computed as a confidence measure to determine whether retransmission is required. If the min-entropy exceeds a predefined threshold, the server requests the edge device to send a detail-preserved local image of the RoI. The server then refines its inference by jointly leveraging the global and local images. This selective retransmission strategy ensures that only essential visual content is transmitted. Experiments across multiple VLM architectures show that the proposed framework significantly reduces communication cost while maintaining inference accuracy.
Code-Weight Sphere Decoding
Aug 28, 2025Ultra-reliable low-latency communications (URLLC) demand high-performance error-correcting codes and decoders in the finite blocklength regime. This letter introduces a novel two-stage near-maximum likelihood (near-ML) decoding framework applicable to any linear block code. Our approach first employs a low-complexity initial decoder. If this initial stage fails a cyclic redundancy check, it triggers a second stage: the proposed code-weight sphere decoding (WSD). WSD iteratively refines the codeword estimate by exploring a localized sphere of candidates constructed from pre-computed low-weight codewords. This strategy adaptively minimizes computational overhead at high signal-to-noise ratios while achieving near-ML performance, especially for low-rate codes. Extensive simulations demonstrate that our two-stage decoder provides an excellent trade-off between decoding reliability and complexity, establishing it as a promising solution for next-generation URLLC systems.
Robust Deep Joint Source Channel Coding for Task-Oriented Semantic Communications
Mar 17, 2025Semantic communications based on deep joint source-channel coding (JSCC) aim to improve communication efficiency by transmitting only task-relevant information. However, ensuring robustness to the stochasticity of communication channels remains a key challenge in learning-based JSCC. In this paper, we propose a novel regularization technique for learning-based JSCC to enhance robustness against channel noise. The proposed method utilizes the Kullback-Leibler (KL) divergence as a regularizer term in the training loss, measuring the discrepancy between two posterior distributions: one under noisy channel conditions (noisy posterior) and one for a noise-free system (noise-free posterior). Reducing this KL divergence mitigates the impact of channel noise on task performance by keeping the noisy posterior close to the noise-free posterior. We further show that the expectation of the KL divergence given the encoded representation can be analytically approximated using the Fisher information matrix and the covariance matrix of the channel noise. Notably, the proposed regularization is architecture-agnostic, making it broadly applicable to general semantic communication systems over noisy channels. Our experimental results validate that the proposed regularization consistently improves task performance across diverse semantic communication systems and channel conditions.
Vision Transformer-based Semantic Communications With Importance-Aware Quantization
Dec 08, 2024Semantic communications provide significant performance gains over traditional communications by transmitting task-relevant semantic features through wireless channels. However, most existing studies rely on end-to-end (E2E) training of neural-type encoders and decoders to ensure effective transmission of these semantic features. To enable semantic communications without relying on E2E training, this paper presents a vision transformer (ViT)-based semantic communication system with importance-aware quantization (IAQ) for wireless image transmission. The core idea of the presented system is to leverage the attention scores of a pretrained ViT model to quantify the importance levels of image patches. Based on this idea, our IAQ framework assigns different quantization bits to image patches based on their importance levels. This is achieved by formulating a weighted quantization error minimization problem, where the weight is set to be an increasing function of the attention score. Then, an optimal incremental allocation method and a low-complexity water-filling method are devised to solve the formulated problem. Our framework is further extended for realistic digital communication systems by modifying the bit allocation problem and the corresponding allocation methods based on an equivalent binary symmetric channel (BSC) model. Simulations on single-view and multi-view image classification tasks show that our IAQ framework outperforms conventional image compression methods in both error-free and realistic communication scenarios.
Neural Window Decoder for SC-LDPC Codes
Nov 28, 2024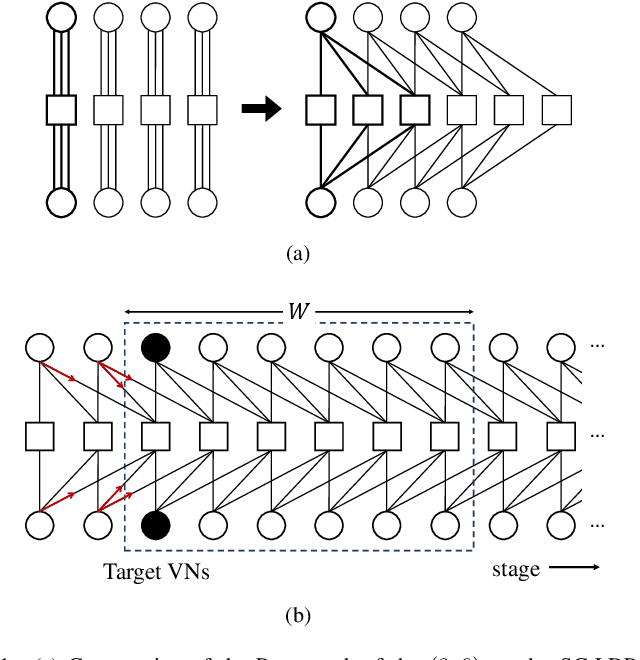
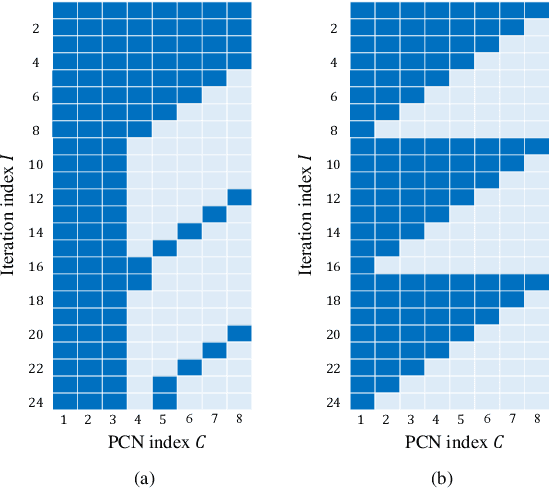
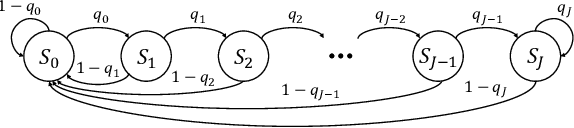
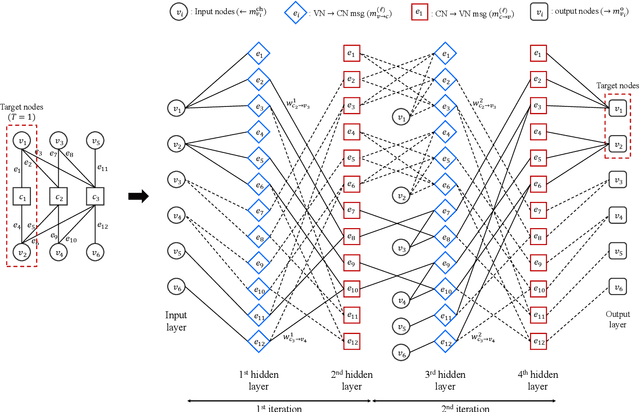
In this paper, we propose a neural window decoder (NWD) for spatially coupled low-density parity-check (SC-LDPC) codes. The proposed NWD retains the conventional window decoder (WD) process but incorporates trainable neural weights. To train the weights of NWD, we introduce two novel training strategies. First, we restrict the loss function to target variable nodes (VNs) of the window, which prunes the neural network and accordingly enhances training efficiency. Second, we employ the active learning technique with a normalized loss term to prevent the training process from biasing toward specific training regions. Next, we develop a systematic method to derive non-uniform schedules for the NWD based on the training results. We introduce trainable damping factors that reflect the relative importance of check node (CN) updates. By skipping updates with less importance, we can omit $\mathbf{41\%}$ of CN updates without performance degradation compared to the conventional WD. Lastly, we address the error propagation problem inherent in SC-LDPC codes by deploying a complementary weight set, which is activated when an error is detected in the previous window. This adaptive decoding strategy effectively mitigates error propagation without requiring modifications to the code and decoder structures.
Boosted Neural Decoders: Achieving Extreme Reliability of LDPC Codes for 6G Networks
May 22, 2024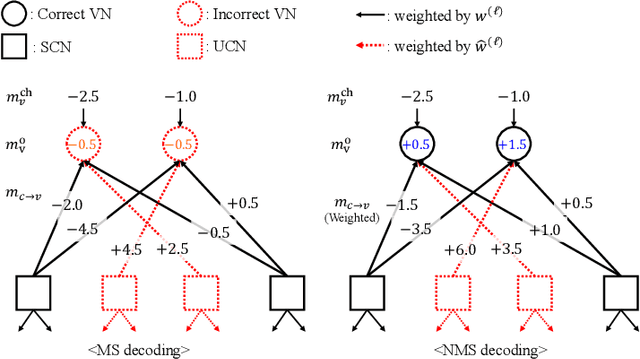
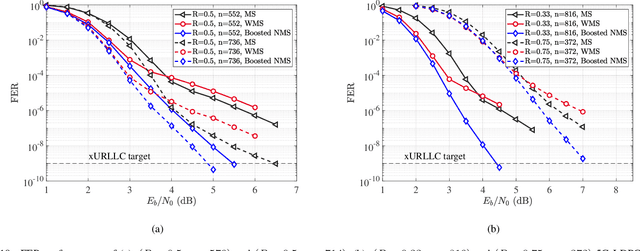
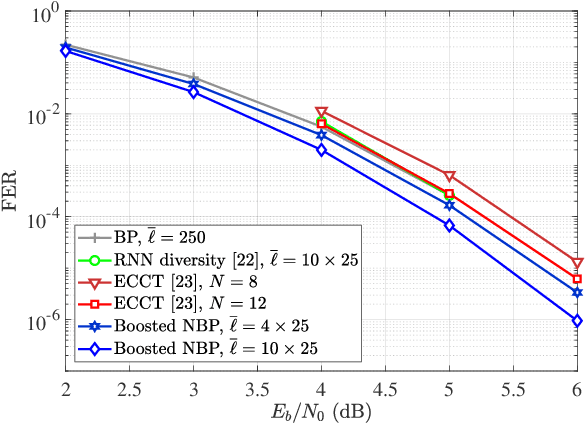
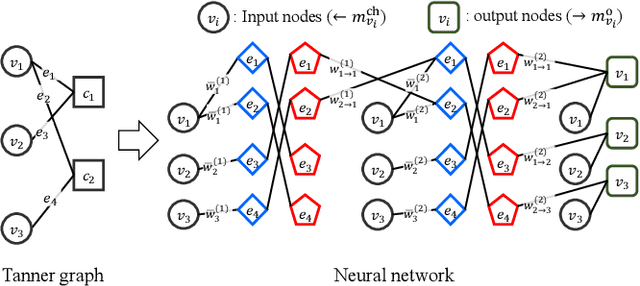
Ensuring extremely high reliability is essential for channel coding in 6G networks. The next-generation of ultra-reliable and low-latency communications (xURLLC) scenario within 6G networks requires a frame error rate (FER) below 10-9. However, low-density parity-check (LDPC) codes, the standard in 5G new radio (NR), encounter a challenge known as the error floor phenomenon, which hinders to achieve such low rates. To tackle this problem, we introduce an innovative solution: boosted neural min-sum (NMS) decoder. This decoder operates identically to conventional NMS decoders, but is trained by novel training methods including: i) boosting learning with uncorrected vectors, ii) block-wise training schedule to address the vanishing gradient issue, iii) dynamic weight sharing to minimize the number of trainable weights, iv) transfer learning to reduce the required sample count, and v) data augmentation to expedite the sampling process. Leveraging these training strategies, the boosted NMS decoder achieves the state-of-the art performance in reducing the error floor as well as superior waterfall performance. Remarkably, we fulfill the 6G xURLLC requirement for 5G LDPC codes without the severe error floor. Additionally, the boosted NMS decoder, once its weights are trained, can perform decoding without additional modules, making it highly practical for immediate application.
CrossMPT: Cross-attention Message-Passing Transformer for Error Correcting Codes
May 02, 2024



Error correcting codes~(ECCs) are indispensable for reliable transmission in communication systems. The recent advancements in deep learning have catalyzed the exploration of ECC decoders based on neural networks. Among these, transformer-based neural decoders have achieved state-of-the-art decoding performance. In this paper, we propose a novel Cross-attention Message-Passing Transformer~(CrossMPT). CrossMPT iteratively updates two types of input vectors (i.e., magnitude and syndrome vectors) using two masked cross-attention blocks. The mask matrices in these cross-attention blocks are determined by the code's parity-check matrix that delineates the relationship between magnitude and syndrome vectors. Our experimental results show that CrossMPT significantly outperforms existing neural network-based decoders, particularly in decoding low-density parity-check codes. Notably, CrossMPT also achieves a significant reduction in computational complexity, achieving over a 50\% decrease in its attention layers compared to the original transformer-based decoder, while retaining the computational complexity of the remaining layers.