 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Wireless Token Communication via Joint Token Masking and Detection
May 04, 2026The increasing use of token-based representations in language-driven applications has motivated wireless token communication, where tokens are treated as fundamental units for transmission. However, conventional communication systems overlook dependencies among tokens and allocate transmission resources uniformly, leading to inefficient use of limited wireless resources under channel impairments. In this paper, we propose a context-aware token communication framework that leverages a masked language model (MLM) as a shared contextual model between the transmitter (Tx) and receiver (Rx). At the Rx, we develop a context-aware token detection method that integrates channel likelihoods with MLM-based contextual priors under a Bayesian formulation, enabling robust token inference over noisy channels. At the Tx, we propose a context-aware token masking strategy that selectively omits tokens that can be reliably inferred at the Rx, allowing the available power budget to be concentrated on more informative tokens. These components are jointly designed through a shared MLM, establishing a unified Tx-Rx framework for efficient token transmission and detection. Simulation results demonstrate that the proposed framework significantly improves reconstruction performance compared to conventional and existing token communication schemes, achieving up to 1.77X and 1.63X performance gains on the Europarl corpus and WikiText-103 datasets, respectively.
Towards Optimal Semantic Communications: Reconsidering the Role of Semantic Feature Channels
Feb 09, 2026This paper investigates the optimization of transmitting the encoder outputs, termed semantic features (SFs), in semantic communication (SC). We begin by modeling the entire communication process from the encoder output to the decoder input, encompassing the physical channel and all transceiver operations, as the SF channel, thereby establishing an encoder-SF channel-decoder pipeline. In contrast to prior studies that assume a fixed SF channel, we note that the SF channel is configurable, as its characteristics are shaped by various transmission and reception strategies, such as power allocation. Based on this observation, we formulate the SF channel optimization problem under a mutual information constraint between the SFs and their reconstructions, and analytically derive the optimal SF channel under a linear encoder-decoder structure and Gaussian source assumption. Building upon this theoretical foundation, we propose a joint optimization framework for the encoder-decoder and SF channel, applicable to both analog and digital SCs. To realize the optimized SF channel, we also propose a physical-layer calibration strategy that enables real-time power control and adaptation to varying channel conditions. Simulation results demonstrate that the proposed SF channel optimization achieves superior task performance under various communication environments.
Importance-Aware Semantic Communication in MIMO-OFDM Systems Using Vision Transformer
Aug 11, 2025This paper presents a novel importance-aware quantization, subcarrier mapping, and power allocation (IA-QSMPA) framework for semantic communication in multiple-input multiple-output orthogonal frequency division multiplexing (MIMO-OFDM) systems, empowered by a pretrained Vision Transformer (ViT). The proposed framework exploits attention-based importance extracted from a pretrained ViT to jointly optimize quantization levels, subcarrier mapping, and power allocation. Specifically, IA-QSMPA maps semantically important features to high-quality subchannels and allocates resources in accordance with their contribution to task performance and communication latency. To efficiently solve the resulting nonconvex optimization problem, a block coordinate descent algorithm is employed. The framework is further extended to operate under finite blocklength transmission, where communication errors may occur. In this setting, a segment-wise linear approximation of the channel dispersion penalty is introduced to enable efficient joint optimization under practical constraints. Simulation results on a multi-view image classification task using the MVP-N dataset demonstrate that IA-QSMPA significantly outperforms conventional methods in both ideal and finite blocklength transmission scenarios, achieving superior task performance and communication efficiency.
ESC-MVQ: End-to-End Semantic Communication With Multi-Codebook Vector Quantization
Apr 16, 2025



This paper proposes a novel end-to-end digital semantic communication framework based on multi-codebook vector quantization (VQ), referred to as ESC-MVQ. Unlike prior approaches that rely on end-to-end training with a specific power or modulation scheme, often under a particular channel condition, ESC-MVQ models a channel transfer function as parallel binary symmetric channels (BSCs) with trainable bit-flip probabilities. Building on this model, ESC-MVQ jointly trains multiple VQ codebooks and their associated bit-flip probabilities with a single encoder-decoder pair. To maximize inference performance when deploying ESC-MVQ in digital communication systems, we devise an optimal communication strategy that jointly optimizes codebook assignment, adaptive modulation, and power allocation. To this end, we develop an iterative algorithm that selects the most suitable VQ codebook for semantic features and flexibly allocates power and modulation schemes across the transmitted symbols. Simulation results demonstrate that ESC-MVQ, using a single encoder-decoder pair, outperforms existing digital semantic communication methods in both performance and memory efficiency, offering a scalable and adaptive solution for realizing digital semantic communication in diverse channel conditions.
Digital Deep Joint Source-Channel Coding with Blind Training for Adaptive Modulation and Power Control
Jan 04, 2025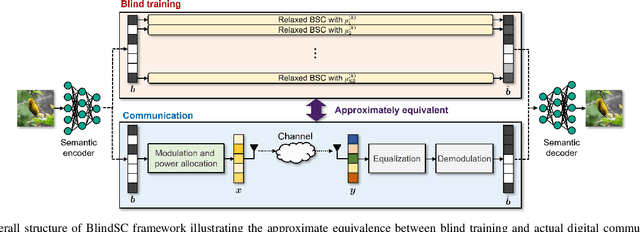
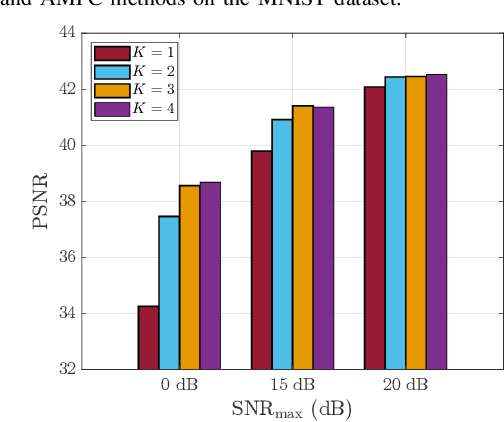
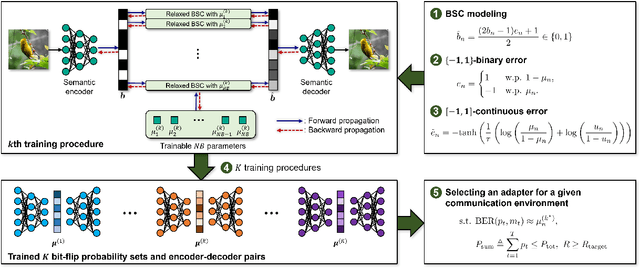
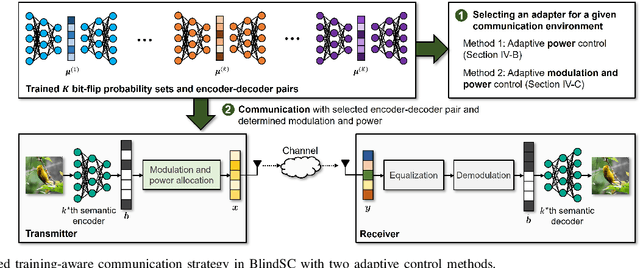
This paper proposes a novel digital deep joint source-channel coding (DeepJSCC) framework that achieves robust performance across diverse communication environments without requiring extensive retraining and prior knowledge of communication environments. Traditional digital DeepJSCC techniques often face challenges in adapting to various communication environments, as they require significant training overhead and large amounts of communication data to develop either multiple specialized models or a single generalized model, in pre-defined communication environments. To address this challenge, in our framework, an error-adaptive blind training strategy is devised, which eliminates the need for prior knowledge of communication environments. This is achieved by modeling the relationship between the encoder's output and the decoder's input using binary symmetric channels, and optimizing bit-flip probabilities by treating them as trainable parameters. In our framework, a training-aware communication strategy is also presented, which dynamically selects the optimal encoder-decoder pair and transmission parameters based on current channel conditions. In particular, in this strategy, an adaptive power and modulation control method is developed to minimize the total transmission power, while maintaining high task performance. Simulation results demonstrate that our framework outperforms existing DeepJSCC methods, achieving higher peak signal-to-noise ratio, lower power consumption, and requiring significantly fewer encoder-decoder pairs for adaptation.
Vision Transformer-based Semantic Communications With Importance-Aware Quantization
Dec 08, 2024Semantic communications provide significant performance gains over traditional communications by transmitting task-relevant semantic features through wireless channels. However, most existing studies rely on end-to-end (E2E) training of neural-type encoders and decoders to ensure effective transmission of these semantic features. To enable semantic communications without relying on E2E training, this paper presents a vision transformer (ViT)-based semantic communication system with importance-aware quantization (IAQ) for wireless image transmission. The core idea of the presented system is to leverage the attention scores of a pretrained ViT model to quantify the importance levels of image patches. Based on this idea, our IAQ framework assigns different quantization bits to image patches based on their importance levels. This is achieved by formulating a weighted quantization error minimization problem, where the weight is set to be an increasing function of the attention score. Then, an optimal incremental allocation method and a low-complexity water-filling method are devised to solve the formulated problem. Our framework is further extended for realistic digital communication systems by modifying the bit allocation problem and the corresponding allocation methods based on an equivalent binary symmetric channel (BSC) model. Simulations on single-view and multi-view image classification tasks show that our IAQ framework outperforms conventional image compression methods in both error-free and realistic communication scenarios.
Deep Learning-Assisted Parallel Interference Cancellation for Grant-Free NOMA in Machine-Type Communication
Mar 12, 2024
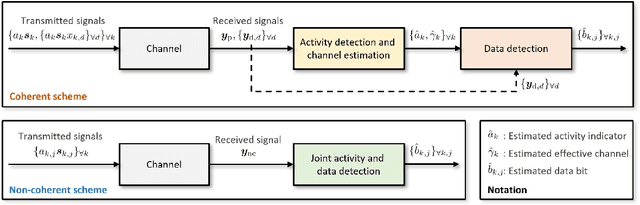
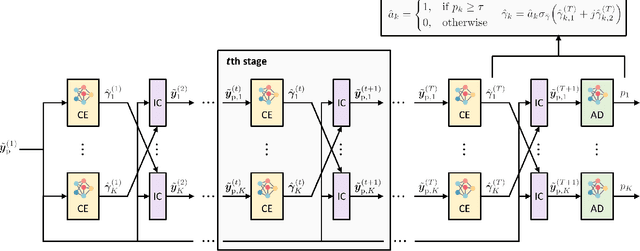
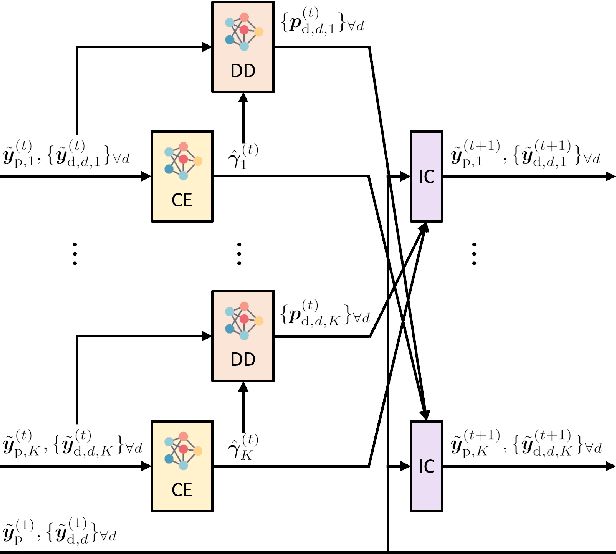
In this paper, we present a novel approach for joint activity detection (AD), channel estimation (CE), and data detection (DD) in uplink grant-free non-orthogonal multiple access (NOMA) systems. Our approach employs an iterative and parallel interference removal strategy inspired by parallel interference cancellation (PIC), enhanced with deep learning to jointly tackle the AD, CE, and DD problems. Based on this approach, we develop three PIC frameworks, each of which is designed for either coherent or non-coherence schemes. The first framework performs joint AD and CE using received pilot signals in the coherent scheme. Building upon this framework, the second framework utilizes both the received pilot and data signals for CE, further enhancing the performances of AD, CE, and DD in the coherent scheme. The third framework is designed to accommodate the non-coherent scheme involving a small number of data bits, which simultaneously performs AD and DD. Through joint loss functions and interference cancellation modules, our approach supports end-to-end training, contributing to enhanced performances of AD, CE, and DD for both coherent and non-coherent schemes. Simulation results demonstrate the superiority of our approach over traditional techniques, exhibiting enhanced performances of AD, CE, and DD while maintaining lower computational complexity.
Prior-Aware Robust Beam Alignment for Low-SNR Millimeter-Wave Communications
Dec 02, 2023This paper presents a robust beam alignment technique for millimeter-wave communications in low signal-to-noise ratio (SNR) environments. The core strategy of our technique is to repeatedly transmit the most probable beam candidates to reduce beam misalignment probability induced by noise. Specifically, for a given beam training overhead, both the selection of candidates and the number of repetitions for each beam candidate are optimized based on channel prior information. To achieve this, a deep neural network is employed to learn the prior probability of the optimal beam at each location. The beam misalignment probability is then analyzed based on the channel prior, forming the basis for an optimization problem aimed at minimizing the analyzed beam misalignment probability. A closed-form solution is derived for a special case with two beam candidates, and an efficient algorithm is developed for general cases with multiple beam candidates. Simulation results using the DeepMIMO dataset demonstrate the superior performance of our technique in dynamic low-SNR communication environments when compared to existing beam alignment techniques.
Joint Source-Channel Coding for Channel-Adaptive Digital Semantic Communications
Nov 14, 2023
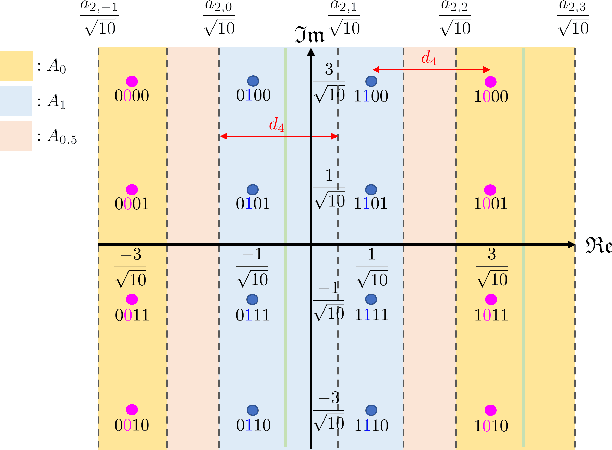
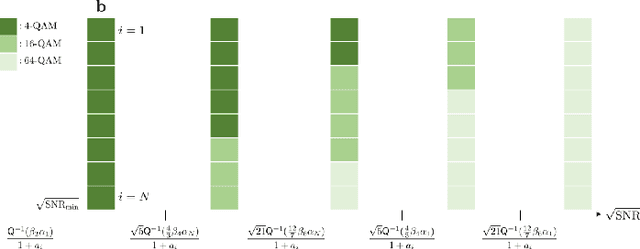
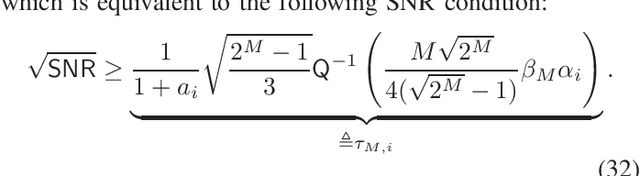
In this paper, we propose a novel joint source-channel coding (JSCC) approach for channel-adaptive digital semantic communications. In semantic communication systems with digital modulation and demodulation, end-to-end training and robust design of JSCC encoder and decoder becomes challenging due to the nonlinearity of modulation and demodulation processes, as well as diverse channel conditions and modulation orders. To address this challenge, we first develop a new demodulation method which assesses the uncertainty of the demodulation output to improve the robustness of the digital semantic communication system. We then devise a robust training strategy that facilitates end-to-end training of the JSCC encoder and decoder, while enhancing their robustness and flexibility. To this end, we model the relationship between the encoder's output and decoder's input using binary symmetric erasure channels and then sample the parameters of these channels from diverse distributions. We also develop a channel-adaptive modulation technique for an inference phase, in order to reduce the communication latency while maintaining task performance. In this technique, we adaptively determine modulation orders for the latent variables based on channel conditions. Using simulations, we demonstrate the superior performance of the proposed JSCC approach for both image classification and reconstruction tasks compared to existing JSCC approaches.
SplitMAC: Wireless Split Learning over Multiple Access Channels
Nov 04, 2023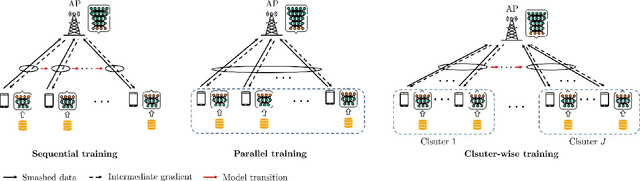
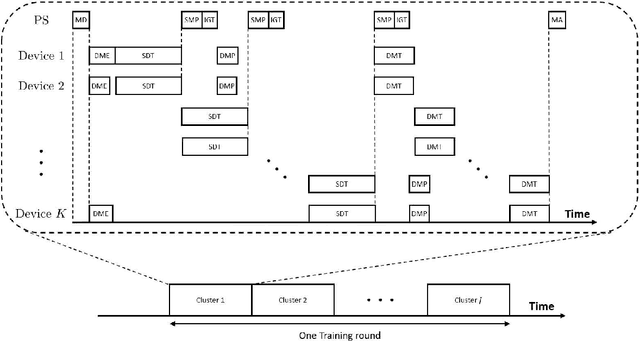
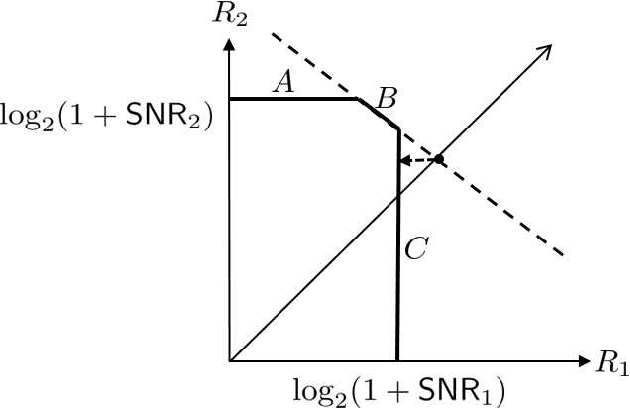
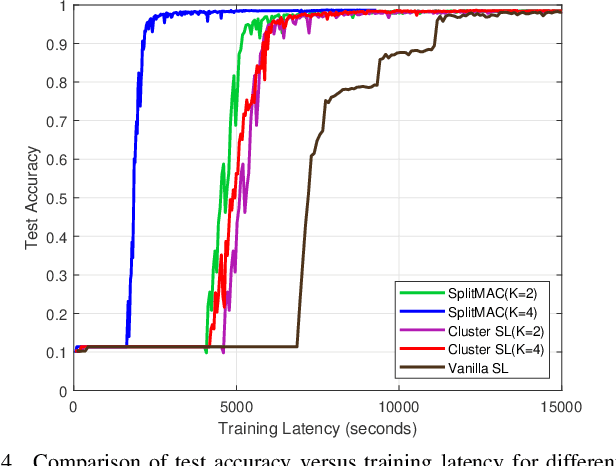
This paper presents a novel split learning (SL) framework, referred to as SplitMAC, which reduces the latency of SL by leveraging simultaneous uplink transmission over multiple access channels. The key strategy is to divide devices into multiple groups and allow the devices within the same group to simultaneously transmit their smashed data and device-side models over the multiple access channels. The optimization problem of device grouping to minimize SL latency is formulated, and the benefit of device grouping in reducing the uplink latency of SL is theoretically derived. By examining a two-device grouping case, two asymptotically-optimal algorithms are devised for device grouping in low and high signal-to-noise ratio (SNR) scenarios, respectively, while providing proofs of their optimality. By merging these algorithms, a near-optimal device grouping algorithm is proposed to cover a wide range of SNR. Simulation results demonstrate that our SL framework with the proposed device grouping algorithm is superior to existing SL frameworks in reducing SL latency.