 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Softmax Reformulation for Homomorphic Encryption via Moment Generating Function
Feb 02, 2026Homomorphic encryption (HE) is a prominent framework for privacy-preserving machine learning, enabling inference directly on encrypted data. However, evaluating softmax, a core component of transformer architectures, remains particularly challenging in HE due to its multivariate structure, the large dynamic range induced by exponential functions, and the need for accurate division during normalization. In this paper, we propose MGF-softmax, a novel softmax reformulation based on the moment generating function (MGF) that replaces the softmax denominator with its moment-based counterpart. This reformulation substantially reduces multiplicative depth while preserving key properties of softmax and asymptotically converging to the exact softmax as the number of input tokens increases. Extensive experiments on Vision Transformers and large language models show that MGF-softmax provides an efficient and accurate approximation of softmax in encrypted inference. In particular, it achieves inference accuracy close to that of high-depth exact methods, while requiring substantially lower computational cost through reduced multiplicative depth.
Optimizing Layerwise Polynomial Approximation for Efficient Private Inference on Fully Homomorphic Encryption: A Dynamic Programming Approach
Oct 16, 2023Recent research has explored the implementation of privacy-preserving deep neural networks solely using fully homomorphic encryption. However, its practicality has been limited because of prolonged inference times. When using a pre-trained model without retraining, a major factor contributing to these prolonged inference times is the high-degree polynomial approximation of activation functions such as the ReLU function. The high-degree approximation consumes a substantial amount of homomorphic computational resources, resulting in slower inference. Unlike the previous works approximating activation functions uniformly and conservatively, this paper presents a \emph{layerwise} degree optimization of activation functions to aggressively reduce the inference time while maintaining classification accuracy by taking into account the characteristics of each layer. Instead of the minimax approximation commonly used in state-of-the-art private inference models, we employ the weighted least squares approximation method with the input distributions of activation functions. Then, we obtain the layerwise optimized degrees for activation functions through the \emph{dynamic programming} algorithm, considering how each layer's approximation error affects the classification accuracy of the deep neural network. Furthermore, we propose modulating the ciphertext moduli-chain layerwise to reduce the inference time. By these proposed layerwise optimization methods, we can reduce inference times for the ResNet-20 model and the ResNet-32 model by 3.44 times and 3.16 times, respectively, in comparison to the prior implementations employing uniform degree polynomials and a consistent ciphertext modulus.
Adaptive Graph Convolution Module for Salient Object Detection
Mar 17, 2023Salient object detection (SOD) is a task that involves identifying and segmenting the most visually prominent object in an image. Existing solutions can accomplish this use a multi-scale feature fusion mechanism to detect the global context of an image. However, as there is no consideration of the structures in the image nor the relations between distant pixels, conventional methods cannot deal with complex scenes effectively. In this paper, we propose an adaptive graph convolution module (AGCM) to overcome these limitations. Prototype features are initially extracted from the input image using a learnable region generation layer that spatially groups features in the image. The prototype features are then refined by propagating information between them based on a graph architecture, where each feature is regarded as a node. Experimental results show that the proposed AGCM dramatically improves the SOD performance both quantitatively and quantitatively.
Privacy-Preserving Machine Learning with Fully Homomorphic Encryption for Deep Neural Network
Jun 14, 2021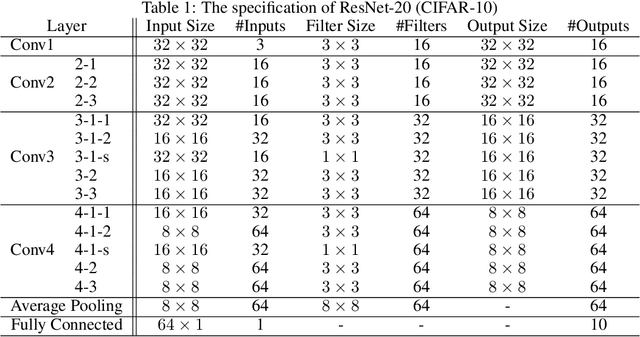
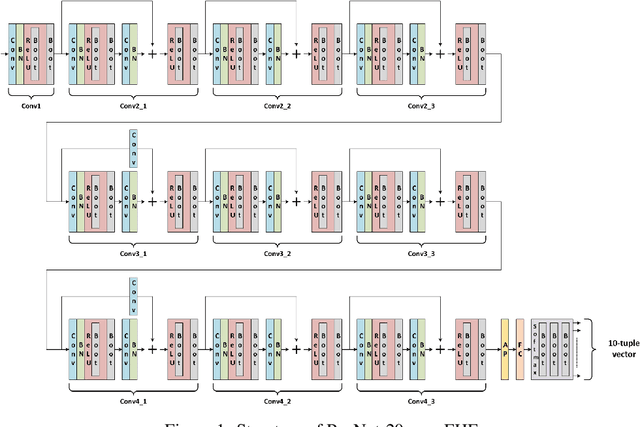


Fully homomorphic encryption (FHE) is one of the prospective tools for privacypreserving machine learning (PPML), and several PPML models have been proposed based on various FHE schemes and approaches. Although the FHE schemes are known as suitable tools to implement PPML models, previous PPML models on FHE encrypted data are limited to only simple and non-standard types of machine learning models. These non-standard machine learning models are not proven efficient and accurate with more practical and advanced datasets. Previous PPML schemes replace non-arithmetic activation functions with simple arithmetic functions instead of adopting approximation methods and do not use bootstrapping, which enables continuous homomorphic evaluations. Thus, they could not use standard activation functions and could not employ a large number of layers. The maximum classification accuracy of the existing PPML model with the FHE for the CIFAR-10 dataset was only 77% until now. In this work, we firstly implement the standard ResNet-20 model with the RNS-CKKS FHE with bootstrapping and verify the implemented model with the CIFAR-10 dataset and the plaintext model parameters. Instead of replacing the non-arithmetic functions with the simple arithmetic function, we use state-of-the-art approximation methods to evaluate these non-arithmetic functions, such as the ReLU, with sufficient precision [1]. Further, for the first time, we use the bootstrapping technique of the RNS-CKKS scheme in the proposed model, which enables us to evaluate a deep learning model on the encrypted data. We numerically verify that the proposed model with the CIFAR-10 dataset shows 98.67% identical results to the original ResNet-20 model with non-encrypted data. The classification accuracy of the proposed model is 90.67%, which is pretty close to that of the original ResNet-20 CNN model...
Iterative DNA Coding Scheme With GC Balance and Run-Length Constraints Using a Greedy Algorithm
Mar 30, 2021
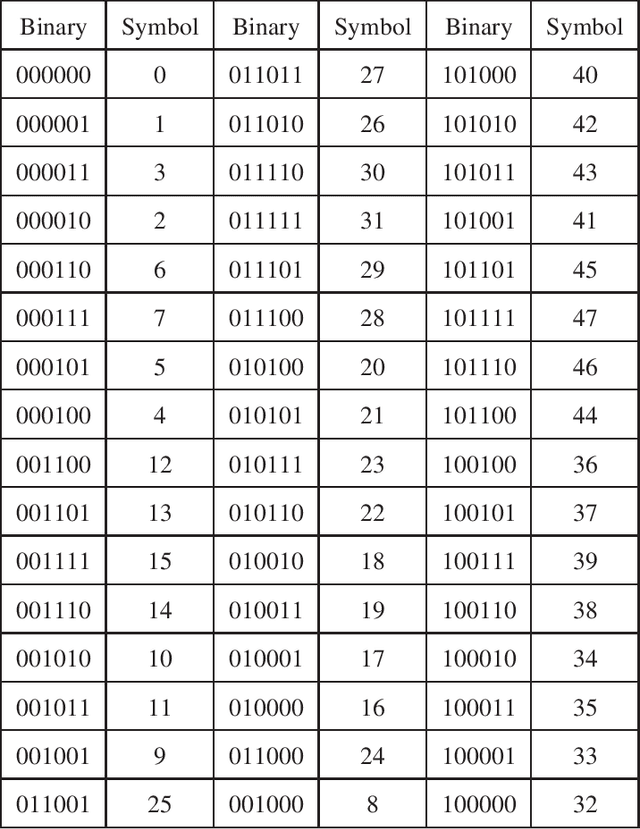
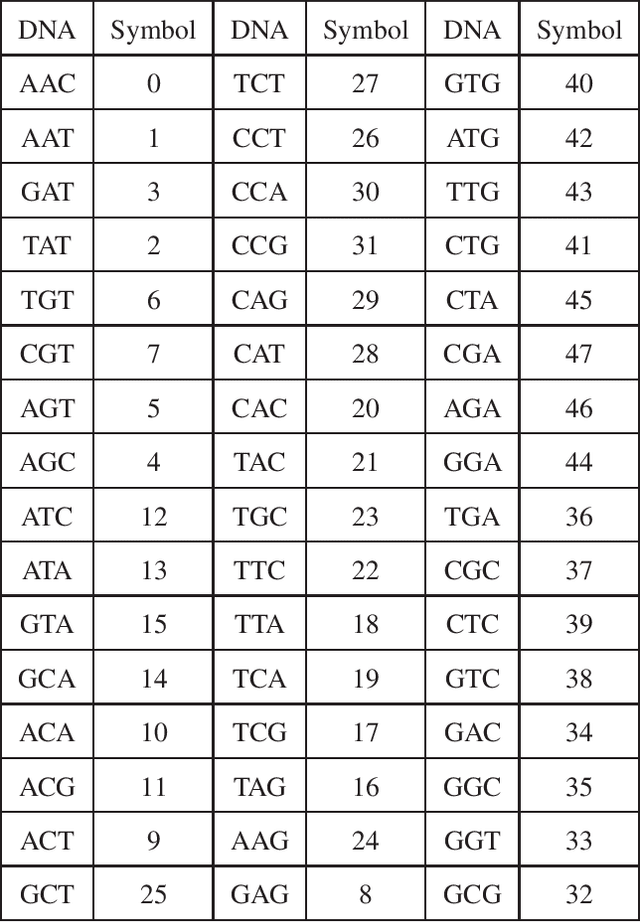
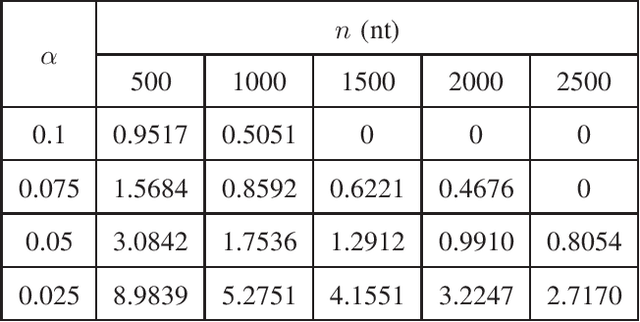
In this paper, we propose a novel iterative encoding algorithm for DNA storage to satisfy both the GC balance and run-length constraints using a greedy algorithm. DNA strands with run-length more than three and the GC balance ratio far from 50\% are known to be prone to errors. The proposed encoding algorithm stores data at high information density with high flexibility of run-length at most $m$ and GC balance between $0.5\pm\alpha$ for arbitrary $m$ and $\alpha$. More importantly, we propose a novel mapping method to reduce the average bit error compared to the randomly generated mapping method, using a greedy algorithm. The proposed algorithm is implemented through iterative encoding, consisting of three main steps: randomization, M-ary mapping, and verification. It has an information density of 1.8616 bits/nt in the case of $m=3$, which approaches the theoretical upper bound of 1.98 bits/nt, while satisfying two constraints. Also, the average bit error caused by the one nt error is 2.3455 bits, which is reduced by $20.5\%$, compared to the randomized mapping.