 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary BP+OSD Decoding for Low-Latency Quantum Error Correction
Dec 20, 2025We propose an evolutionary belief propagation (EBP) decoder for quantum error correction, which incorporates trainable weights into the BP algorithm and optimizes them via the differential evolution algorithm. This approach enables end-to-end optimization of the EBP combined with ordered statistics decoding (OSD). Experimental results on surface codes and quantum low-density parity-check codes show that EBP+OSD achieves better decoding performance and lower computational complexity than BP+OSD, particularly under strict low latency constraints (within 5 BP iterations).
CrossMPT: Cross-attention Message-Passing Transformer for Error Correcting Codes
May 02, 2024



Error correcting codes~(ECCs) are indispensable for reliable transmission in communication systems. The recent advancements in deep learning have catalyzed the exploration of ECC decoders based on neural networks. Among these, transformer-based neural decoders have achieved state-of-the-art decoding performance. In this paper, we propose a novel Cross-attention Message-Passing Transformer~(CrossMPT). CrossMPT iteratively updates two types of input vectors (i.e., magnitude and syndrome vectors) using two masked cross-attention blocks. The mask matrices in these cross-attention blocks are determined by the code's parity-check matrix that delineates the relationship between magnitude and syndrome vectors. Our experimental results show that CrossMPT significantly outperforms existing neural network-based decoders, particularly in decoding low-density parity-check codes. Notably, CrossMPT also achieves a significant reduction in computational complexity, achieving over a 50\% decrease in its attention layers compared to the original transformer-based decoder, while retaining the computational complexity of the remaining layers.
How to Mask in Error Correction Code Transformer: Systematic and Double Masking
Aug 25, 2023In communication and storage systems, error correction codes (ECCs) are pivotal in ensuring data reliability. As deep learning's applicability has broadened across diverse domains, there is a growing research focus on neural network-based decoders that outperform traditional decoding algorithms. Among these neural decoders, Error Correction Code Transformer (ECCT) has achieved the state-of-the-art performance, outperforming other methods by large margins. To further enhance the performance of ECCT, we propose two novel methods. First, leveraging the systematic encoding technique of ECCs, we introduce a new masking matrix for ECCT, aiming to improve the performance and reduce the computational complexity. Second, we propose a novel transformer architecture of ECCT called a double-masked ECCT. This architecture employs two different mask matrices in a parallel manner to learn more diverse features of the relationship between codeword bits in the masked self-attention blocks. Extensive simulation results show that the proposed double-masked ECCT outperforms the conventional ECCT, achieving the state-of-the-art decoding performance with significant margins.
Iterative DNA Coding Scheme With GC Balance and Run-Length Constraints Using a Greedy Algorithm
Mar 30, 2021
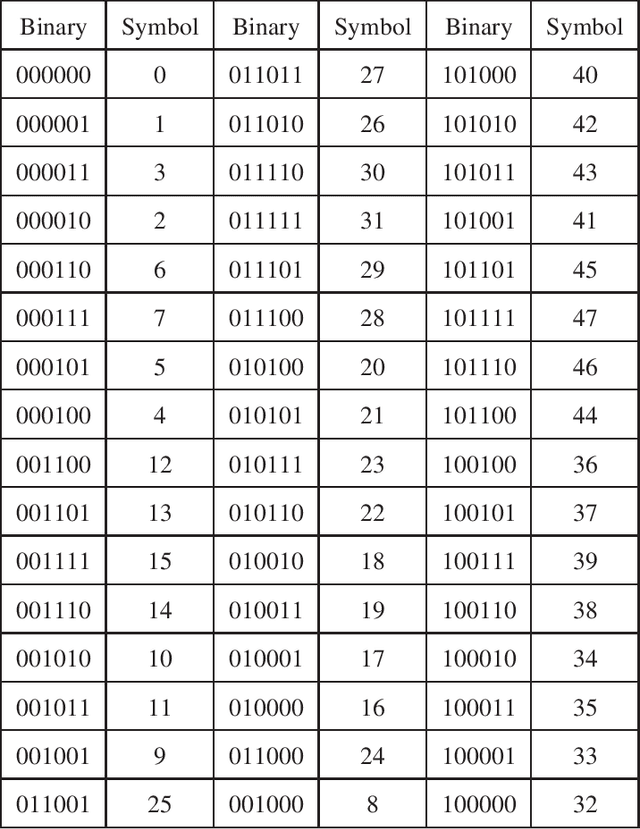
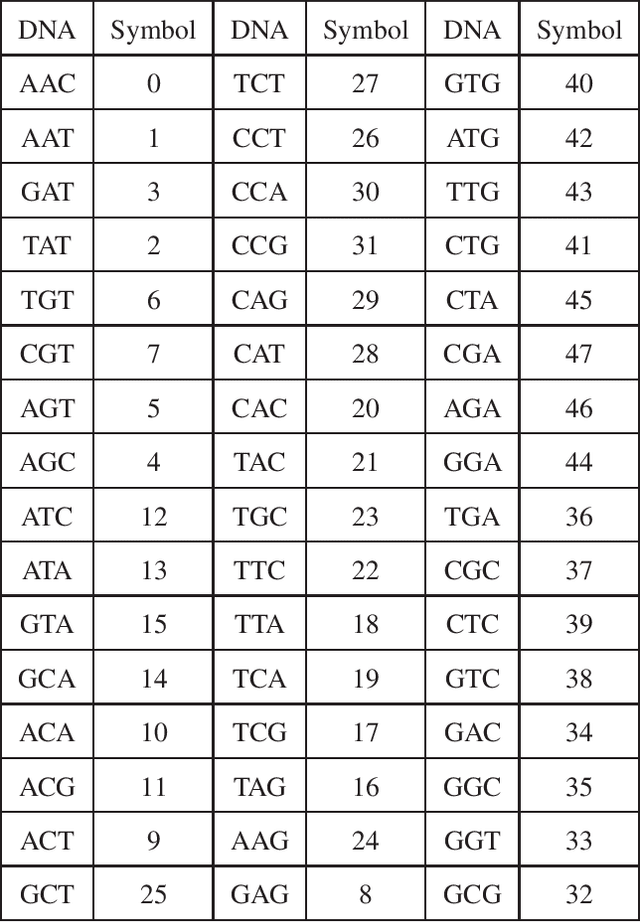
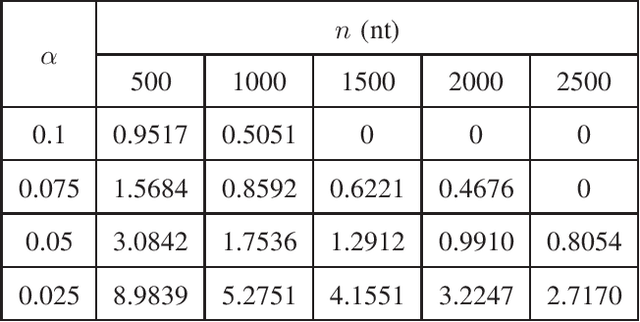
In this paper, we propose a novel iterative encoding algorithm for DNA storage to satisfy both the GC balance and run-length constraints using a greedy algorithm. DNA strands with run-length more than three and the GC balance ratio far from 50\% are known to be prone to errors. The proposed encoding algorithm stores data at high information density with high flexibility of run-length at most $m$ and GC balance between $0.5\pm\alpha$ for arbitrary $m$ and $\alpha$. More importantly, we propose a novel mapping method to reduce the average bit error compared to the randomly generated mapping method, using a greedy algorithm. The proposed algorithm is implemented through iterative encoding, consisting of three main steps: randomization, M-ary mapping, and verification. It has an information density of 1.8616 bits/nt in the case of $m=3$, which approaches the theoretical upper bound of 1.98 bits/nt, while satisfying two constraints. Also, the average bit error caused by the one nt error is 2.3455 bits, which is reduced by $20.5\%$, compared to the randomized mapping.