 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFibQuant: Universal Vector Quantization for Random-Access KV-Cache Compression
May 12, 2026Long-context inference is increasingly a memory-traffic problem. The culprit is the key--value (KV) cache: it grows with context length, batch size, layers, and heads, and it is read at every decoding step. Rotation-based scalar codecs meet this systems constraint by storing a norm, applying a shared random rotation, and quantizing one coordinate at a time. They are universal and random-access, but they discard the geometry created by the normalization step. After a Haar rotation, a block of $k$ consecutive coordinates is not a product source; it is a spherical-Beta source on the unit ball. We introduce \textsc{FibQuant}, a universal fixed-rate vector quantizer that keeps the same normalize--rotate--store interface while replacing scalar tables by a shared radial--angular codebook matched to this canonical source. The codebook combines Beta-quantile radii, Fibonacci\,/\,Roberts--Kronecker quasi-uniform directions, and multi-restart Lloyd--Max refinement. We prove that the resulting vector code strictly improves on its scalar product specialization at matched rate, with a high-rate gain that separates into a cell-shaping factor and a density-matching factor. The same construction gives a dense rate axis, including fractional-bit and sub-one-bit operating points, without calibration or variable-length addresses. On GPT-2 small KV caches, \textsc{FibQuant} traces a memory--fidelity frontier from $5\times$ compression at $0.99$ attention cosine similarity to $34\times$ at $0.95$. End-to-end on TinyLlama-1.1B, it is within $0.10$ perplexity of fp16 at $4\times$ compression and has $3.6\times$ lower perplexity than scalar \textsc{TurboQuant} at $b = 2$ ($8\times$ compression), where scalar random-access quantization begins to fail.
Near-field channel estimation via wavefront parameterization
May 05, 2026This paper deals with the estimation of multiantenna channels in the line-of-sight conditions that are prevalent in the near field. By expressing the curved wavefront as a polynomial via a power series expansion of a sphere, the estimation of the channel over the array can be formulated as a multidimensional polynomial phase estimation problem. The application of a newly developed polynomial phase estimator, able of handling arbitrary dimensions and polynomial degrees, yields a superior tradeoff between channel estimation accuracy and complexity.
CSI Feedback Under Basis Mismatch: Rate-Splitting Transform Coding for FDD Massive MIMO
Apr 22, 2026In frequency division duplex massive multiple-input multiple-output systems, downlink channel state information must be fed back within a limited uplink budget. While transform coding with Karhunen-Loeve transform and reverse water-filling is rate-distortion optimal for Gaussian channels, its performance is limited by basis mismatch between the user and base station. We analyze this mismatch and propose a practical architecture separating long-term basis feedback from short-term coefficient quantization. Using a random vector quantization, we derive a closed-form end-to-end mean square error expression. This allows us to characterize the optimal rate split and identify a phase transition threshold for basis updates. Simulations on correlated Gaussian and COST2100 channels demonstrate near-optimal performance, robustness to update overhead, and significant complexity reduction compared to deep-learning-based autoencoders.
Fundamental Limits of CSI Compression in FDD Massive MIMO
Mar 15, 2026Channel state information (CSI) feedback in frequency-division duplex (FDD) massive multiple-input multiple-output (MIMO) systems is fundamentally limited by the high dimensionality of wideband channels. In this paper, we model the stacked wideband CSI vector as a Gaussian-mixture source with a latent geometry state that represents different propagation environments. Each component corresponds to a locally stationary regime characterized by a correlated proper complex Gaussian distribution with its own covariance matrix. This representation captures the multimodal nature of practical CSI datasets while preserving the analytical tractability of Gaussian models. Motivated by this structure, we propose Gaussian-mixture transform coding (GMTC), a practical CSI feedback architecture that combines state inference with state-adaptive TC. The mixture parameters are learned offline from channel samples and stored as a shared statistical dictionary at both the user equipment (UE) and the base station. For each CSI realization, the UE identifies the most likely geometry state, encodes the corresponding label using a lossless source code, and compresses the CSI using the Karhunen-Loeve transform matched to that state. We further characterize the fundamental limits of CSI compression under this model by deriving analytical converse and achievability bounds on the rate-distortion (RD) function. A key structural result is that the optimal bit allocation across all mixture components is governed by a single global reverse-waterfilling level. Simulations on the COST2100 dataset show that GMTC significantly improves the RD tradeoff relative to neural transform coding approaches while requiring substantially smaller model memory and lower inference complexity. These results indicate that near-optimal CSI compression can be achieved through state-adaptive TC without relying on large neural encoders.
Scalable and Convergent Generalized Power Iteration Precoding for Massive MIMO Systems
Mar 04, 2026In massive multiple-input multiple-output (MIMO) systems, achieving high spectral efficiency (SE) often requires advanced precoding algorithms whose complexity scales rapidly with the number of antennas, limiting practical deployment. In this paper, we develop a scalable and computationally efficient generalized power iteration precoding (GPIP) framework for massive MIMO systems under both perfect and imperfect channel state information at the transmitter (CSIT). By exploiting the low-dimensional subspace property of optimal precoders, we reformulate the high-dimensional beamforming problem into a lower-dimensional weight optimization that scales with the number of users rather than antennas. We further extend this framework to the imperfect CSIT scenario by showing that stationary solutions reside in a combined subspace spanned by the estimated channel and error covariance matrices, enabling a robust design via low-rank approximation. To reduce computational cost, we leverage the Sherman-Morrison formula to simplify matrix inversions. Moreover, interpreting the GPIP update as a projected preconditioned gradient ascent method, we establish convergence guarantees and develop a stable and monotonic algorithm using a backtracking line search. Numerical results demonstrate that the proposed methods achieve the highest SE performance compared to state-of-the-art linear precoders with significantly reduced complexity and convergence, highlighting their suitability for large-scale MIMO systems.
Multipoint Code-Weight Sphere Decoding: Parallel Near-ML Decoding for Short-Blocklength Codes
Feb 09, 2026Ultra-reliable low-latency communications (URLLC) operate with short packets, where finite-blocklength effects make near-maximum-likelihood (near-ML) decoding desirable but often too costly. This paper proposes a two-stage near-ML decoding framework that applies to any linear block code. In the first stage, we run a low-complexity decoder to produce a candidate codeword and a cyclic redundancy check. When this stage succeeds, we terminate immediately. When it fails, we invoke a second-stage decoder, termed multipoint code-weight sphere decoding (MP-WSD). The central idea behind {MP-WSD} is to concentrate the ML search where it matters. We pre-compute a set of low-weight codewords and use them to generate structured local perturbations of the current estimate. Starting from the first-stage output, MP-WSD iteratively explores a small Euclidean sphere of candidate codewords formed by adding selected low-weight codewords, tightening the search region as better candidates are found. This design keeps the average complexity low: at high signal-to-noise ratio, the first stage succeeds with high probability and the second stage is rarely activated; when it is activated, the search remains localized. Simulation results show that the proposed decoder attains near-ML performance for short-blocklength, low-rate codes while maintaining low decoding latency.
Hierarchical Subcode Ensemble Decoding of Polar Codes
Feb 09, 2026Subcode-ensemble decoders improve iterative decoding by running multiple decoders in parallel over carefully chosen subcodes, increasing the likelihood that at least one decoder avoids the dominant trapping structures. Achieving strong diversity gains, however, requires constructing many subcodes that satisfy a linear covering property-yet existing approaches lack a systematic way to scale the ensemble size while preserving this property. This paper introduces hierarchical subcode ensemble decoding (HSCED), a new ensemble decoding framework that expands the number of constituent decoders while still guaranteeing linear covering. The key idea is to recursively generate subcode parity constraints in a hierarchical structure so that coverage is maintained at every level, enabling large ensembles with controlled complexity. To demonstrate its effectiveness, we apply HSCED to belief propagation (BP) decoding of polar codes, where dense parity-check matrices induce severe stopping-set effects that limit conventional BP. Simulations confirm that HSCED delivers significant block-error-rate improvements over standard BP and conventional subcode-ensemble decoding under the same decoding-latency constraint.
The MIMO-ME-MS Channel: Analysis and Algorithm for Secure MIMO Integrated Sensing and Communications
Dec 24, 2025This paper studies precoder design for secure MIMO integrated sensing and communications (ISAC) by introducing the MIMO-ME-MS channel, where a multi-antenna transmitter serves a legitimate multi-antenna receiver in the presence of a multi-antenna eavesdropper while simultaneously enabling sensing via a multi-antenna sensing receiver. Using sensing mutual information as the sensing metric, we formulate a nonconvex weighted objective that jointly captures secure communication (via secrecy rate) and sensing performance. A high-SNR analysis based on subspace decomposition characterizes the maximum achievable weighted degrees of freedom and reveals that a quasi-optimal precoder must span a "useful subspace," highlighting why straightforward extensions of classical wiretap/ISAC precoders can be suboptimal in this tripartite setting. Motivated by these insights, we develop a practical two-stage iterative algorithm that alternates between sequential basis construction and power allocation via a difference-of-convex program. Numerical results show that the proposed approach captures the desirable precoding structure predicted by the analysis and yields substantial gains in the MIMO-ME-MS channel.
Code-Weight Sphere Decoding
Aug 28, 2025Ultra-reliable low-latency communications (URLLC) demand high-performance error-correcting codes and decoders in the finite blocklength regime. This letter introduces a novel two-stage near-maximum likelihood (near-ML) decoding framework applicable to any linear block code. Our approach first employs a low-complexity initial decoder. If this initial stage fails a cyclic redundancy check, it triggers a second stage: the proposed code-weight sphere decoding (WSD). WSD iteratively refines the codeword estimate by exploring a localized sphere of candidates constructed from pre-computed low-weight codewords. This strategy adaptively minimizes computational overhead at high signal-to-noise ratios while achieving near-ML performance, especially for low-rate codes. Extensive simulations demonstrate that our two-stage decoder provides an excellent trade-off between decoding reliability and complexity, establishing it as a promising solution for next-generation URLLC systems.
Space-Time Beamforming for LEO Satellite Communications
May 12, 2025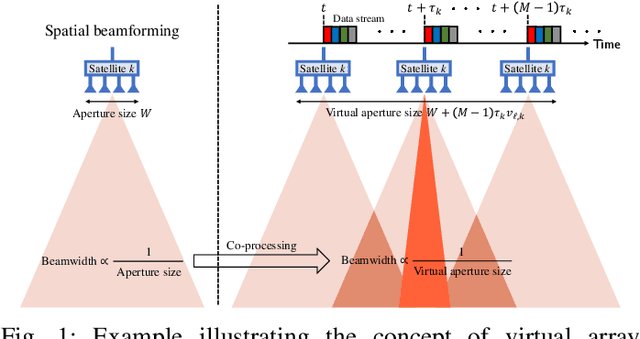
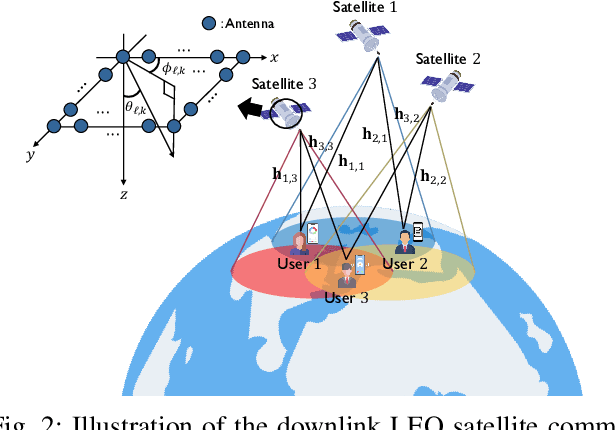
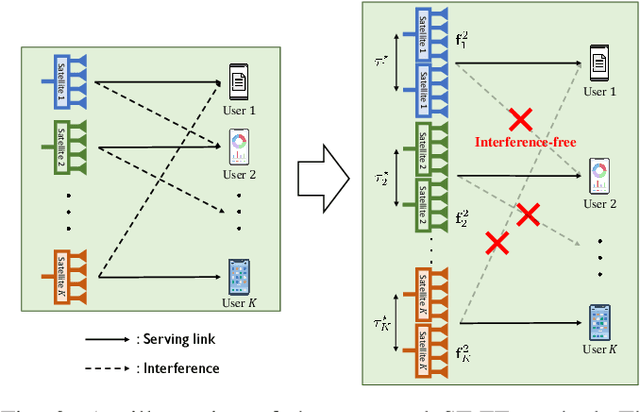
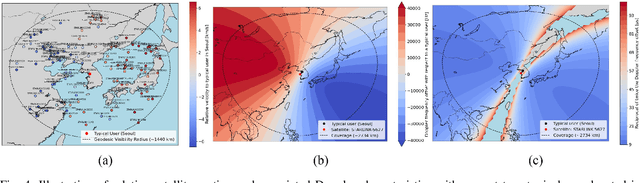
Inter-beam interference poses a significant challenge in low Earth orbit (LEO) satellite communications due to dense satellite constellations. To address this issue, we introduce spacetime beamforming, a novel paradigm that leverages the spacetime channel vector, uniquely determined by the angle of arrival (AoA) and relative Doppler shift, to optimize beamforming between a moving satellite transmitter and a ground station user. We propose two space-time beamforming techniques: spacetime zero-forcing (ST-ZF) and space-time signal-to-leakage-plus-noise ratio (ST-SLNR) maximization. In a partially connected interference channel, ST-ZF achieves a 3dB SNR gain over the conventional interference avoidance method using maximum ratio transmission beamforming. Moreover, in general interference networks, ST-SLNR beamforming significantly enhances sum spectral efficiency compared to conventional interference management approaches. These results demonstrate the effectiveness of space-time beamforming in improving spectral efficiency and interference mitigation for next-generation LEO satellite networks.