 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Visual Code Mobile World Models
Feb 02, 2026Mobile Graphical User Interface (GUI) World Models (WMs) offer a promising path for improving mobile GUI agent performance at train- and inference-time. However, current approaches face a critical trade-off: text-based WMs sacrifice visual fidelity, while the inability of visual WMs in precise text rendering led to their reliance on slow, complex pipelines dependent on numerous external models. We propose a novel paradigm: visual world modeling via renderable code generation, where a single Vision-Language Model (VLM) predicts the next GUI state as executable web code that renders to pixels, rather than generating pixels directly. This combines the strengths of both approaches: VLMs retain their linguistic priors for precise text rendering while their pre-training on structured web code enables high-fidelity visual generation. We introduce gWorld (8B, 32B), the first open-weight visual mobile GUI WMs built on this paradigm, along with a data generation framework (gWorld) that automatically synthesizes code-based training data. In extensive evaluation across 4 in- and 2 out-of-distribution benchmarks, gWorld sets a new pareto frontier in accuracy versus model size, outperforming 8 frontier open-weight models over 50.25x larger. Further analyses show that (1) scaling training data via gWorld yields meaningful gains, (2) each component of our pipeline improves data quality, and (3) stronger world modeling improves downstream mobile GUI policy performance.
AdaSTaR: Adaptive Data Sampling for Training Self-Taught Reasoners
May 22, 2025Self-Taught Reasoners (STaR), synonymously known as Rejection sampling Fine-Tuning (RFT), is an integral part of the training pipeline of self-improving reasoning Language Models (LMs). The self-improving mechanism often employs random observation (data) sampling. However, this results in trained observation imbalance; inefficiently over-training on solved examples while under-training on challenging ones. In response, we introduce Adaptive STaR (AdaSTaR), a novel algorithm that rectifies this by integrating two adaptive sampling principles: (1) Adaptive Sampling for Diversity: promoting balanced training across observations, and (2) Adaptive Sampling for Curriculum: dynamically adjusting data difficulty to match the model's evolving strength. Across six benchmarks, AdaSTaR achieves best test accuracy in all instances (6/6) and reduces training FLOPs by an average of 58.6% against an extensive list of baselines. These improvements in performance and efficiency generalize to different pre-trained LMs and larger models, paving the way for more efficient and effective self-improving LMs.
$C^2$: Scalable Auto-Feedback for LLM-based Chart Generation
Oct 24, 2024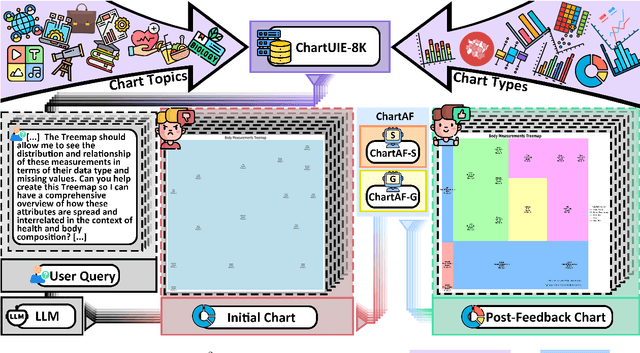

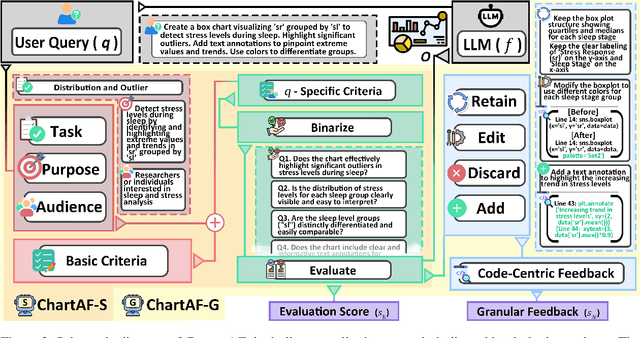

Generating high-quality charts with Large Language Models presents significant challenges due to limited data and the high cost of scaling through human curation. Instruction, data, and code triplets are scarce and expensive to manually curate as their creation demands technical expertise. To address this scalability issue, we introduce a reference-free automatic feedback generator, which eliminates the need for costly human intervention. Our novel framework, $C^2$, consists of (1) an automatic feedback provider (ChartAF) and (2) a diverse, reference-free dataset (ChartUIE-8K). Quantitative results are compelling: in our first experiment, 74% of respondents strongly preferred, and 10% preferred, the results after feedback. The second post-feedback experiment demonstrates that ChartAF outperforms nine baselines. Moreover, ChartUIE-8K significantly improves data diversity by increasing queries, datasets, and chart types by 5982%, 1936%, and 91%, respectively, over benchmarks. Finally, an LLM user study revealed that 94% of participants preferred ChartUIE-8K's queries, with 93% deeming them aligned with real-world use cases. Core contributions are available as open-source at an anonymized project site, with ample qualitative examples.
FlickerFusion: Intra-trajectory Domain Generalizing Multi-Agent RL
Oct 21, 2024



Multi-agent reinforcement learning has demonstrated significant potential in addressing complex cooperative tasks across various real-world applications. However, existing MARL approaches often rely on the restrictive assumption that the number of entities (e.g., agents, obstacles) remains constant between training and inference. This overlooks scenarios where entities are dynamically removed or added during the inference trajectory -- a common occurrence in real-world environments like search and rescue missions and dynamic combat situations. In this paper, we tackle the challenge of intra-trajectory dynamic entity composition under zero-shot out-of-domain (OOD) generalization, where such dynamic changes cannot be anticipated beforehand. Our empirical studies reveal that existing MARL methods suffer significant performance degradation and increased uncertainty in these scenarios. In response, we propose FlickerFusion, a novel OOD generalization method that acts as a universally applicable augmentation technique for MARL backbone methods. Our results show that FlickerFusion not only achieves superior inference rewards but also uniquely reduces uncertainty vis-\`a-vis the backbone, compared to existing methods. For standardized evaluation, we introduce MPEv2, an enhanced version of Multi Particle Environments (MPE), consisting of 12 benchmarks. Benchmarks, implementations, and trained models are organized and open-sourced at flickerfusion305.github.io, accompanied by ample demo video renderings.
Encoding Temporal Statistical-space Priors via Augmented Representation
Feb 03, 2024

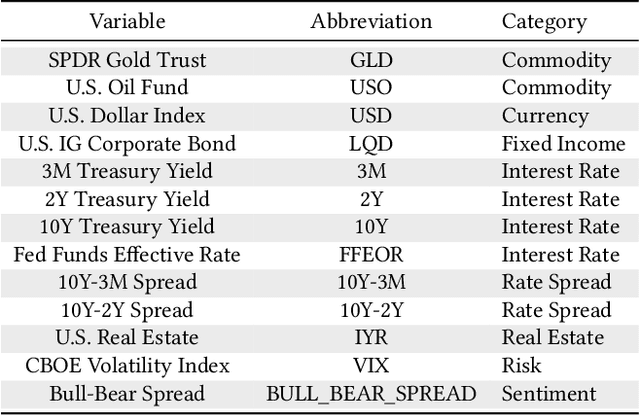

Modeling time series data remains a pervasive issue as the temporal dimension is inherent to numerous domains. Despite significant strides in time series forecasting, high noise-to-signal ratio, non-normality, non-stationarity, and lack of data continue challenging practitioners. In response, we leverage a simple representation augmentation technique to overcome these challenges. Our augmented representation acts as a statistical-space prior encoded at each time step. In response, we name our method Statistical-space Augmented Representation (SSAR). The underlying high-dimensional data-generating process inspires our representation augmentation. We rigorously examine the empirical generalization performance on two data sets with two downstream temporal learning algorithms. Our approach significantly beats all five up-to-date baselines. Moreover, the highly modular nature of our approach can easily be applied to various settings. Lastly, fully-fledged theoretical perspectives are available throughout the writing for a clear and rigorous understanding.
Curriculum Learning and Imitation Learning for Model-free Control on Financial Time-series
Nov 22, 2023

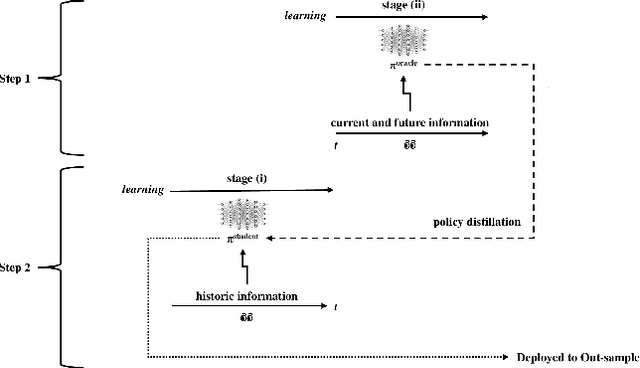
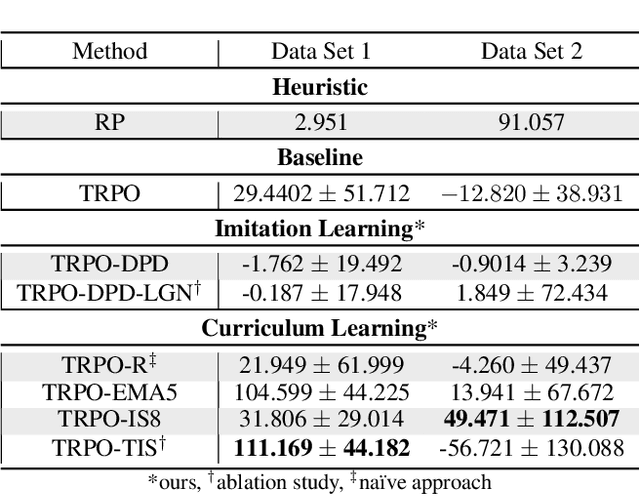
Curriculum learning and imitation learning have been leveraged extensively in the robotics domain. However, minimal research has been done on leveraging these ideas on control tasks over highly stochastic time-series data. Here, we theoretically and empirically explore these approaches in a representative control task over complex time-series data. We implement the fundamental ideas of curriculum learning via data augmentation, while imitation learning is implemented via policy distillation from an oracle. Our findings reveal that curriculum learning should be considered a novel direction in improving control-task performance over complex time-series. Our ample random-seed out-sample empirics and ablation studies are highly encouraging for curriculum learning for time-series control. These findings are especially encouraging as we tune all overlapping hyperparameters on the baseline -- giving an advantage to the baseline. On the other hand, we find that imitation learning should be used with caution.