 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey and Evaluation of Converging Architecture in LLMs based on Footsteps of Operations
Oct 15, 2024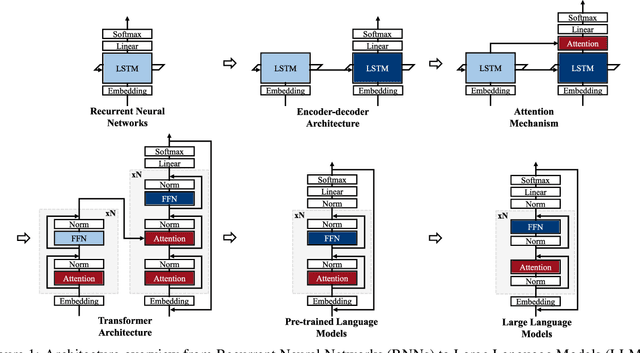
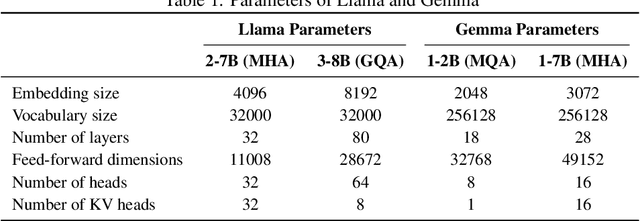
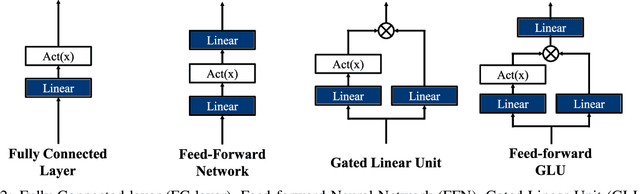
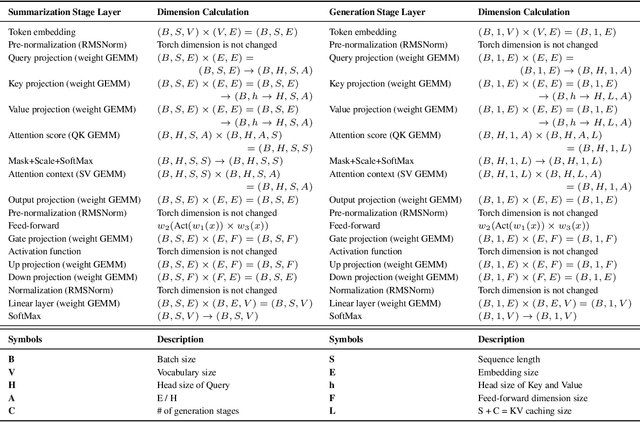
The advent of the Attention mechanism and Transformer architecture enables contextually natural text generation and compresses the burden of processing entire source information into singular vectors. Based on these two main ideas, model sizes gradually increases to accommodate more precise and comprehensive information, leading to the current state-of-the-art LLMs being very large, with parameters around 70 billion. As the model sizes are growing, the demand for substantial storage and computational capacity increases. This leads to the development of high-bandwidth memory and accelerators, as well as a variety of model architectures designed to meet these requirements. We note that LLM architectures have increasingly converged. This paper analyzes how these converged architectures perform in terms of layer configurations, operational mechanisms, and model sizes, considering various hyperparameter settings. In this paper, we conduct a concise survey of the history of LLMs by tracing the evolution of their operational improvements. Furthermore, we summarize the performance trends of LLMs under various hyperparameter settings using the RTX 6000, which features the state-of-the-art Ada Lovelace architecture. We conclude that even the same model can exhibit different behaviors depending on the hyperparameters or whether it is deployed in server or edge environments.
Encoding Temporal Statistical-space Priors via Augmented Representation
Feb 03, 2024

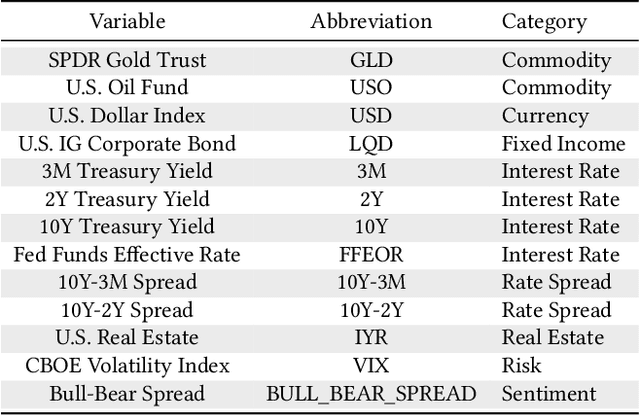

Modeling time series data remains a pervasive issue as the temporal dimension is inherent to numerous domains. Despite significant strides in time series forecasting, high noise-to-signal ratio, non-normality, non-stationarity, and lack of data continue challenging practitioners. In response, we leverage a simple representation augmentation technique to overcome these challenges. Our augmented representation acts as a statistical-space prior encoded at each time step. In response, we name our method Statistical-space Augmented Representation (SSAR). The underlying high-dimensional data-generating process inspires our representation augmentation. We rigorously examine the empirical generalization performance on two data sets with two downstream temporal learning algorithms. Our approach significantly beats all five up-to-date baselines. Moreover, the highly modular nature of our approach can easily be applied to various settings. Lastly, fully-fledged theoretical perspectives are available throughout the writing for a clear and rigorous understanding.
Curriculum Learning and Imitation Learning for Model-free Control on Financial Time-series
Nov 22, 2023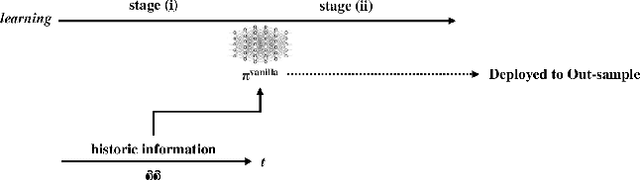

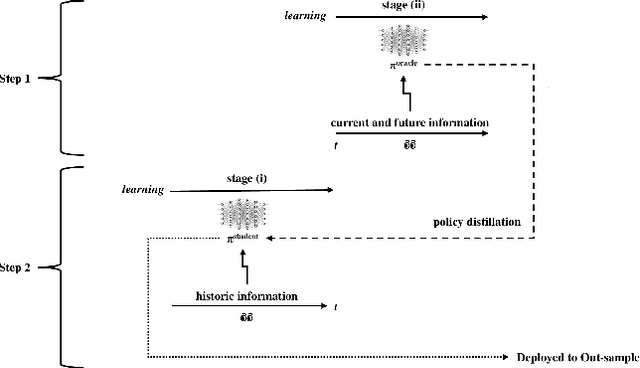
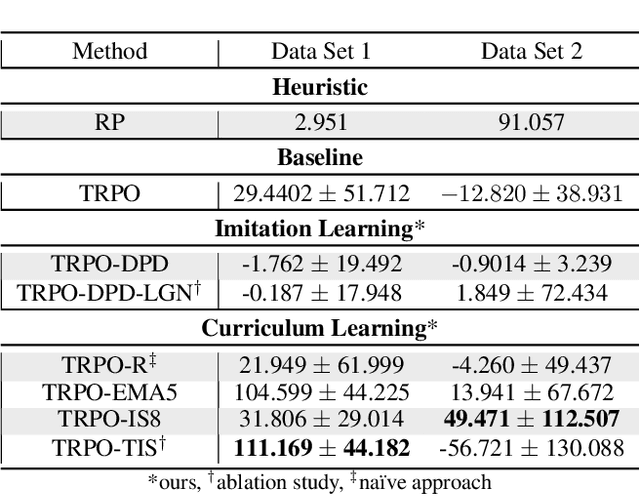
Curriculum learning and imitation learning have been leveraged extensively in the robotics domain. However, minimal research has been done on leveraging these ideas on control tasks over highly stochastic time-series data. Here, we theoretically and empirically explore these approaches in a representative control task over complex time-series data. We implement the fundamental ideas of curriculum learning via data augmentation, while imitation learning is implemented via policy distillation from an oracle. Our findings reveal that curriculum learning should be considered a novel direction in improving control-task performance over complex time-series. Our ample random-seed out-sample empirics and ablation studies are highly encouraging for curriculum learning for time-series control. These findings are especially encouraging as we tune all overlapping hyperparameters on the baseline -- giving an advantage to the baseline. On the other hand, we find that imitation learning should be used with caution.