 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey and Evaluation of Converging Architecture in LLMs based on Footsteps of Operations
Oct 15, 2024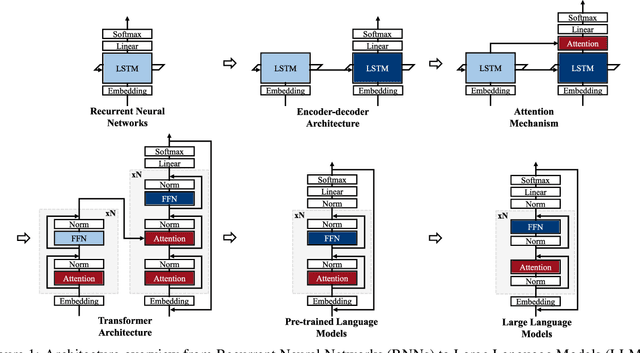
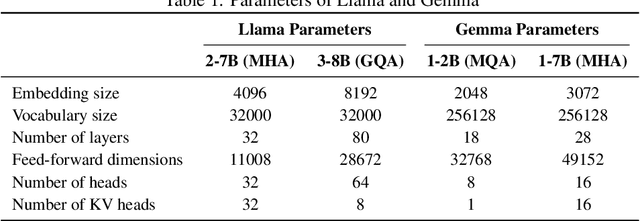
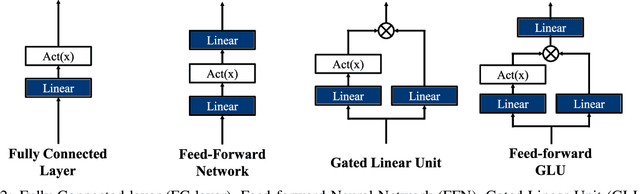
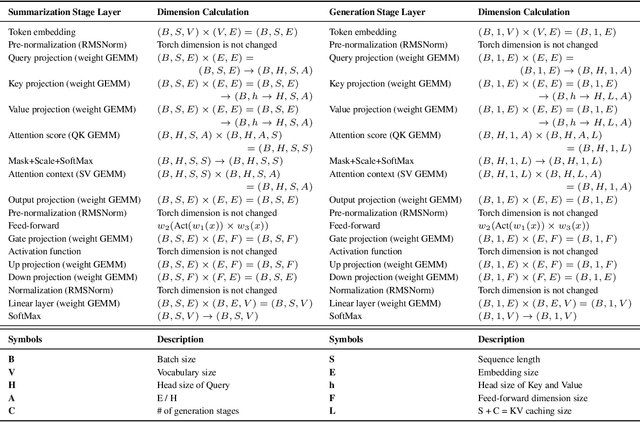
The advent of the Attention mechanism and Transformer architecture enables contextually natural text generation and compresses the burden of processing entire source information into singular vectors. Based on these two main ideas, model sizes gradually increases to accommodate more precise and comprehensive information, leading to the current state-of-the-art LLMs being very large, with parameters around 70 billion. As the model sizes are growing, the demand for substantial storage and computational capacity increases. This leads to the development of high-bandwidth memory and accelerators, as well as a variety of model architectures designed to meet these requirements. We note that LLM architectures have increasingly converged. This paper analyzes how these converged architectures perform in terms of layer configurations, operational mechanisms, and model sizes, considering various hyperparameter settings. In this paper, we conduct a concise survey of the history of LLMs by tracing the evolution of their operational improvements. Furthermore, we summarize the performance trends of LLMs under various hyperparameter settings using the RTX 6000, which features the state-of-the-art Ada Lovelace architecture. We conclude that even the same model can exhibit different behaviors depending on the hyperparameters or whether it is deployed in server or edge environments.
Boosting Semi-Supervised Learning by bridging high and low-confidence predictions
Aug 15, 2023Pseudo-labeling is a crucial technique in semi-supervised learning (SSL), where artificial labels are generated for unlabeled data by a trained model, allowing for the simultaneous training of labeled and unlabeled data in a supervised setting. However, several studies have identified three main issues with pseudo-labeling-based approaches. Firstly, these methods heavily rely on predictions from the trained model, which may not always be accurate, leading to a confirmation bias problem. Secondly, the trained model may be overfitted to easy-to-learn examples, ignoring hard-to-learn ones, resulting in the \textit{"Matthew effect"} where the already strong become stronger and the weak weaker. Thirdly, most of the low-confidence predictions of unlabeled data are discarded due to the use of a high threshold, leading to an underutilization of unlabeled data during training. To address these issues, we propose a new method called ReFixMatch, which aims to utilize all of the unlabeled data during training, thus improving the generalizability of the model and performance on SSL benchmarks. Notably, ReFixMatch achieves 41.05\% top-1 accuracy with 100k labeled examples on ImageNet, outperforming the baseline FixMatch and current state-of-the-art methods.
CRAFT: Criticality-Aware Fault-Tolerance Enhancement Techniques for Emerging Memories-Based Deep Neural Networks
Feb 08, 2023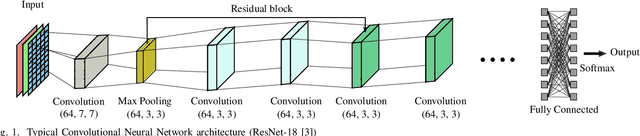
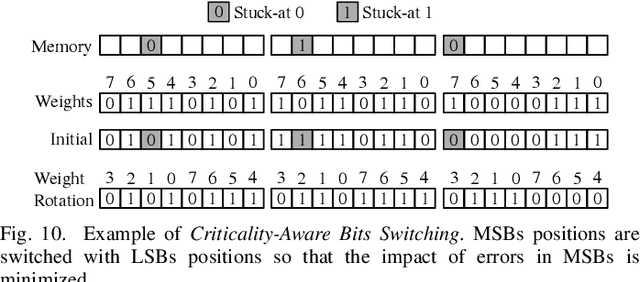
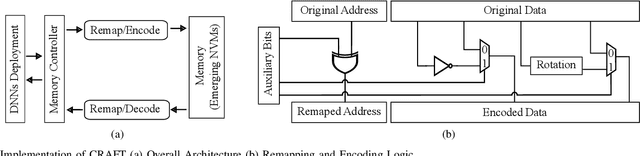
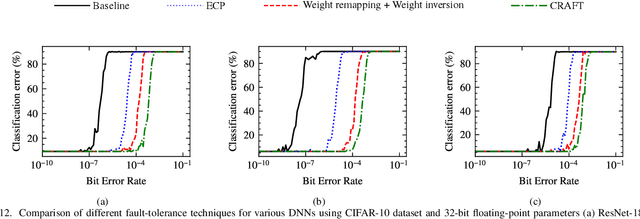
Deep Neural Networks (DNNs) have emerged as the most effective programming paradigm for computer vision and natural language processing applications. With the rapid development of DNNs, efficient hardware architectures for deploying DNN-based applications on edge devices have been extensively studied. Emerging Non-Volatile Memories (NVMs), with their better scalability, non-volatility and good read performance, are found to be promising candidates for deploying DNNs. However, despite the promise, emerging NVMs often suffer from reliability issues such as stuck-at faults, which decrease the chip yield/memory lifetime and severely impact the accuracy of DNNs. A stuck-at cell can be read but not reprogrammed, thus, stuck-at faults in NVMs may or may not result in errors depending on the data to be stored. By reducing the number of errors caused by stuck-at faults, the reliability of a DNN-based system can be enhanced. This paper proposes CRAFT, i.e., Criticality-Aware Fault-Tolerance Enhancement Techniques to enhance the reliability of NVM-based DNNs in the presence of stuck-at faults. A data block remapping technique is used to reduce the impact of stuck-at faults on DNNs accuracy. Additionally, by performing bit-level criticality analysis on various DNNs, the critical-bit positions in network parameters that can significantly impact the accuracy are identified. Based on this analysis, we propose an encoding method which effectively swaps the critical bit positions with that of non-critical bits when more errors (due to stuck-at faults) are present in the critical bits.