 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttn-Adapter: Attention Is All You Need for Online Few-shot Learner of Vision-Language Model
Sep 04, 2025Contrastive vision-language models excel in zero-shot image recognition but face challenges in few-shot scenarios due to computationally intensive offline fine-tuning using prompt learning, which risks overfitting. To overcome these limitations, we propose Attn-Adapter, a novel online few-shot learning framework that enhances CLIP's adaptability via a dual attention mechanism. Our design incorporates dataset-specific information through two components: the Memory Attn-Adapter, which refines category embeddings using support examples, and the Local-Global Attn-Adapter, which enriches image embeddings by integrating local and global features. This architecture enables dynamic adaptation from a few labeled samples without retraining the base model. Attn-Adapter outperforms state-of-the-art methods in cross-category and cross-dataset generalization, maintaining efficient inference and scaling across CLIP backbones.
Adaptive Cache Enhancement for Test-Time Adaptation of Vision-Language Models
Aug 11, 2025Vision-language models (VLMs) exhibit remarkable zero-shot generalization but suffer performance degradation under distribution shifts in downstream tasks, particularly in the absence of labeled data. Test-Time Adaptation (TTA) addresses this challenge by enabling online optimization of VLMs during inference, eliminating the need for annotated data. Cache-based TTA methods exploit historical knowledge by maintaining a dynamic memory cache of low-entropy or high-confidence samples, promoting efficient adaptation to out-of-distribution data. Nevertheless, these methods face two critical challenges: (1) unreliable confidence metrics under significant distribution shifts, resulting in error accumulation within the cache and degraded adaptation performance; and (2) rigid decision boundaries that fail to accommodate substantial distributional variations, leading to suboptimal predictions. To overcome these limitations, we introduce the Adaptive Cache Enhancement (ACE) framework, which constructs a robust cache by selectively storing high-confidence or low-entropy image embeddings per class, guided by dynamic, class-specific thresholds initialized from zero-shot statistics and iteratively refined using an exponential moving average and exploration-augmented updates. This approach enables adaptive, class-wise decision boundaries, ensuring robust and accurate predictions across diverse visual distributions. Extensive experiments on 15 diverse benchmark datasets demonstrate that ACE achieves state-of-the-art performance, delivering superior robustness and generalization compared to existing TTA methods in challenging out-of-distribution scenarios.
Accelerating Conditional Prompt Learning via Masked Image Modeling for Vision-Language Models
Aug 07, 2025Vision-language models (VLMs) like CLIP excel in zero-shot learning but often require resource-intensive training to adapt to new tasks. Prompt learning techniques, such as CoOp and CoCoOp, offer efficient adaptation but tend to overfit to known classes, limiting generalization to unseen categories. We introduce ProMIM, a plug-and-play framework that enhances conditional prompt learning by integrating masked image modeling (MIM) into existing VLM pipelines. ProMIM leverages a simple yet effective masking strategy to generate robust, instance-conditioned prompts, seamlessly augmenting methods like CoOp and CoCoOp without altering their core architectures. By masking only visible image patches and using these representations to guide prompt generation, ProMIM improves feature robustness and mitigates overfitting, all while introducing negligible additional computational cost. Extensive experiments across zero-shot and few-shot classification tasks demonstrate that ProMIM consistently boosts generalization performance when plugged into existing approaches, providing a practical, lightweight solution for real-world vision-language applications.
Symmetric masking strategy enhances the performance of Masked Image Modeling
Aug 23, 2024Masked Image Modeling (MIM) is a technique in self-supervised learning that focuses on acquiring detailed visual representations from unlabeled images by estimating the missing pixels in randomly masked sections. It has proven to be a powerful tool for the preliminary training of Vision Transformers (ViTs), yielding impressive results across various tasks. Nevertheless, most MIM methods heavily depend on the random masking strategy to formulate the pretext task. This strategy necessitates numerous trials to ascertain the optimal dropping ratio, which can be resource-intensive, requiring the model to be pre-trained for anywhere between 800 to 1600 epochs. Furthermore, this approach may not be suitable for all datasets. In this work, we propose a new masking strategy that effectively helps the model capture global and local features. Based on this masking strategy, SymMIM, our proposed training pipeline for MIM is introduced. SymMIM achieves a new SOTA accuracy of 85.9\% on ImageNet using ViT-Large and surpasses previous SOTA across downstream tasks such as image classification, semantic segmentation, object detection, instance segmentation tasks, and so on.
SAVE: Segment Audio-Visual Easy way using Segment Anything Model
Jul 02, 2024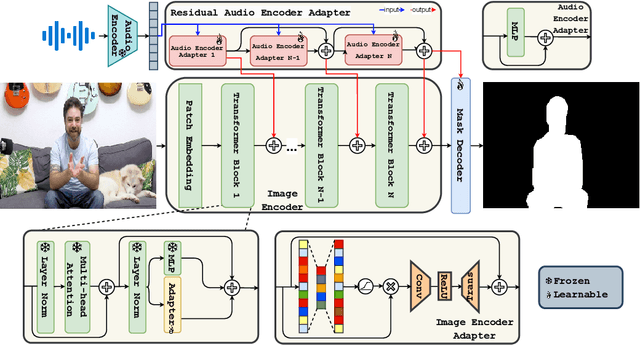
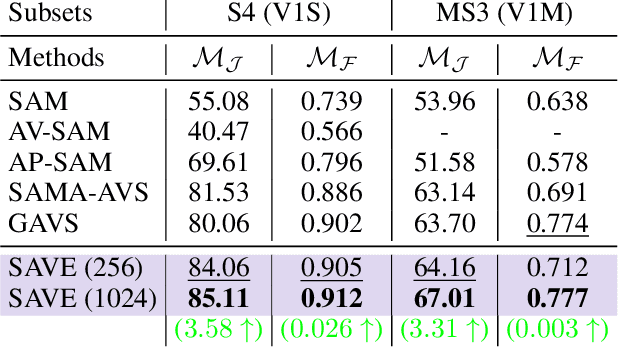
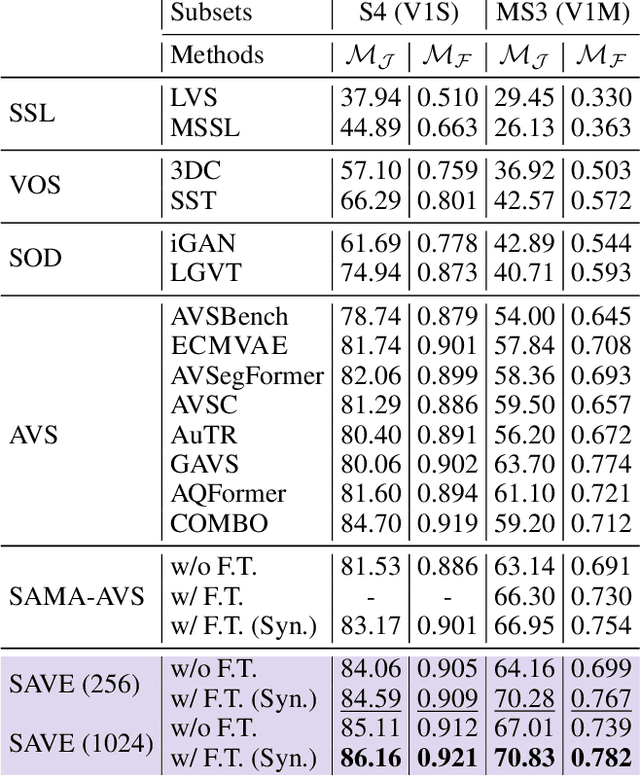

The primary aim of Audio-Visual Segmentation (AVS) is to precisely identify and locate auditory elements within visual scenes by accurately predicting segmentation masks at the pixel level. Achieving this involves comprehensively considering data and model aspects to address this task effectively. This study presents a lightweight approach, SAVE, which efficiently adapts the pre-trained segment anything model (SAM) to the AVS task. By incorporating an image encoder adapter into the transformer blocks to better capture the distinct dataset information and proposing a residual audio encoder adapter to encode the audio features as a sparse prompt, our proposed model achieves effective audio-visual fusion and interaction during the encoding stage. Our proposed method accelerates the training and inference speed by reducing the input resolution from 1024 to 256 pixels while achieving higher performance compared with the previous SOTA. Extensive experimentation validates our approach, demonstrating that our proposed model outperforms other SOTA methods significantly. Moreover, leveraging the pre-trained model on synthetic data enhances performance on real AVSBench data, achieving 84.59 mIoU on the S4 (V1S) subset and 70.28 mIoU on the MS3 (V1M) set with only 256 pixels for input images. This increases up to 86.16 mIoU on the S4 (V1S) and 70.83 mIoU on the MS3 (V1M) with inputs of 1024 pixels.
Retro: Reusing teacher projection head for efficient embedding distillation on Lightweight Models via Self-supervised Learning
May 27, 2024Self-supervised learning (SSL) is gaining attention for its ability to learn effective representations with large amounts of unlabeled data. Lightweight models can be distilled from larger self-supervised pre-trained models using contrastive and consistency constraints. Still, the different sizes of the projection heads make it challenging for students to mimic the teacher's embedding accurately. We propose \textsc{Retro}, which reuses the teacher's projection head for students, and our experimental results demonstrate significant improvements over the state-of-the-art on all lightweight models. For instance, when training EfficientNet-B0 using ResNet-50/101/152 as teachers, our approach improves the linear result on ImageNet to $66.9\%$, $69.3\%$, and $69.8\%$, respectively, with significantly fewer parameters.
SequenceMatch: Revisiting the design of weak-strong augmentations for Semi-supervised learning
Oct 24, 2023



Semi-supervised learning (SSL) has become popular in recent years because it allows the training of a model using a large amount of unlabeled data. However, one issue that many SSL methods face is the confirmation bias, which occurs when the model is overfitted to the small labeled training dataset and produces overconfident, incorrect predictions. To address this issue, we propose SequenceMatch, an efficient SSL method that utilizes multiple data augmentations. The key element of SequenceMatch is the inclusion of a medium augmentation for unlabeled data. By taking advantage of different augmentations and the consistency constraints between each pair of augmented examples, SequenceMatch helps reduce the divergence between the prediction distribution of the model for weakly and strongly augmented examples. In addition, SequenceMatch defines two different consistency constraints for high and low-confidence predictions. As a result, SequenceMatch is more data-efficient than ReMixMatch, and more time-efficient than both ReMixMatch ($\times4$) and CoMatch ($\times2$) while having higher accuracy. Despite its simplicity, SequenceMatch consistently outperforms prior methods on standard benchmarks, such as CIFAR-10/100, SVHN, and STL-10. It also surpasses prior state-of-the-art methods by a large margin on large-scale datasets such as ImageNet, with a 38.46\% error rate. Code is available at https://github.com/beandkay/SequenceMatch.
Debiasing, calibrating, and improving Semi-supervised Learning performance via simple Ensemble Projector
Oct 24, 2023Recent studies on semi-supervised learning (SSL) have achieved great success. Despite their promising performance, current state-of-the-art methods tend toward increasingly complex designs at the cost of introducing more network components and additional training procedures. In this paper, we propose a simple method named Ensemble Projectors Aided for Semi-supervised Learning (EPASS), which focuses mainly on improving the learned embeddings to boost the performance of the existing contrastive joint-training semi-supervised learning frameworks. Unlike standard methods, where the learned embeddings from one projector are stored in memory banks to be used with contrastive learning, EPASS stores the ensemble embeddings from multiple projectors in memory banks. As a result, EPASS improves generalization, strengthens feature representation, and boosts performance. For instance, EPASS improves strong baselines for semi-supervised learning by 39.47\%/31.39\%/24.70\% top-1 error rate, while using only 100k/1\%/10\% of labeled data for SimMatch, and achieves 40.24\%/32.64\%/25.90\% top-1 error rate for CoMatch on the ImageNet dataset. These improvements are consistent across methods, network architectures, and datasets, proving the general effectiveness of the proposed methods. Code is available at https://github.com/beandkay/EPASS.
Boosting Semi-Supervised Learning by bridging high and low-confidence predictions
Aug 15, 2023Pseudo-labeling is a crucial technique in semi-supervised learning (SSL), where artificial labels are generated for unlabeled data by a trained model, allowing for the simultaneous training of labeled and unlabeled data in a supervised setting. However, several studies have identified three main issues with pseudo-labeling-based approaches. Firstly, these methods heavily rely on predictions from the trained model, which may not always be accurate, leading to a confirmation bias problem. Secondly, the trained model may be overfitted to easy-to-learn examples, ignoring hard-to-learn ones, resulting in the \textit{"Matthew effect"} where the already strong become stronger and the weak weaker. Thirdly, most of the low-confidence predictions of unlabeled data are discarded due to the use of a high threshold, leading to an underutilization of unlabeled data during training. To address these issues, we propose a new method called ReFixMatch, which aims to utilize all of the unlabeled data during training, thus improving the generalizability of the model and performance on SSL benchmarks. Notably, ReFixMatch achieves 41.05\% top-1 accuracy with 100k labeled examples on ImageNet, outperforming the baseline FixMatch and current state-of-the-art methods.