 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetro: Reusing teacher projection head for efficient embedding distillation on Lightweight Models via Self-supervised Learning
Paper and Code
May 27, 2024

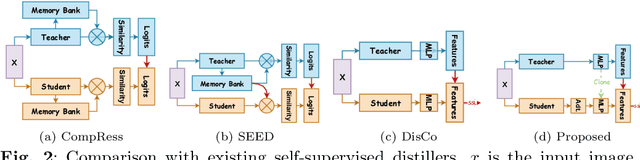

Self-supervised learning (SSL) is gaining attention for its ability to learn effective representations with large amounts of unlabeled data. Lightweight models can be distilled from larger self-supervised pre-trained models using contrastive and consistency constraints. Still, the different sizes of the projection heads make it challenging for students to mimic the teacher's embedding accurately. We propose \textsc{Retro}, which reuses the teacher's projection head for students, and our experimental results demonstrate significant improvements over the state-of-the-art on all lightweight models. For instance, when training EfficientNet-B0 using ResNet-50/101/152 as teachers, our approach improves the linear result on ImageNet to $66.9\%$, $69.3\%$, and $69.8\%$, respectively, with significantly fewer parameters.