 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey and Evaluation of Converging Architecture in LLMs based on Footsteps of Operations
Paper and Code
Oct 15, 2024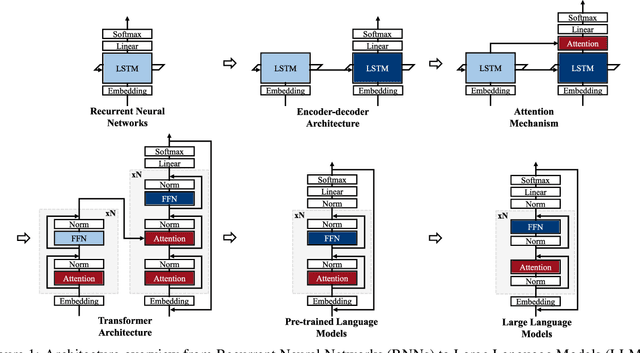
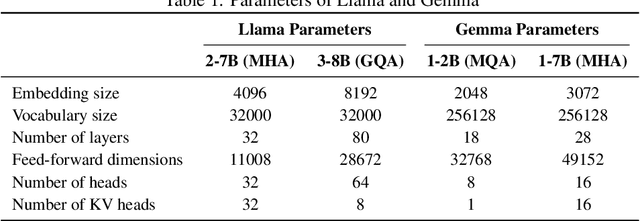
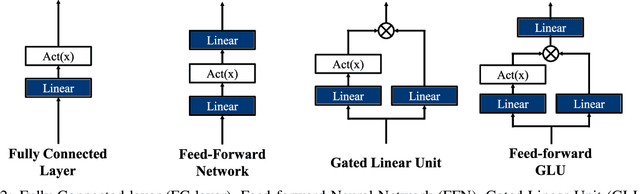
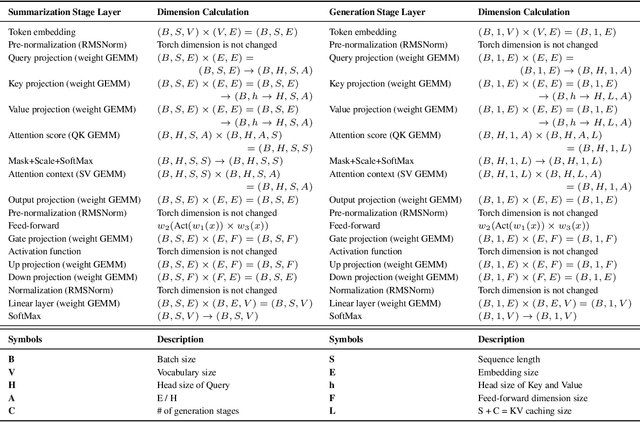
The advent of the Attention mechanism and Transformer architecture enables contextually natural text generation and compresses the burden of processing entire source information into singular vectors. Based on these two main ideas, model sizes gradually increases to accommodate more precise and comprehensive information, leading to the current state-of-the-art LLMs being very large, with parameters around 70 billion. As the model sizes are growing, the demand for substantial storage and computational capacity increases. This leads to the development of high-bandwidth memory and accelerators, as well as a variety of model architectures designed to meet these requirements. We note that LLM architectures have increasingly converged. This paper analyzes how these converged architectures perform in terms of layer configurations, operational mechanisms, and model sizes, considering various hyperparameter settings. In this paper, we conduct a concise survey of the history of LLMs by tracing the evolution of their operational improvements. Furthermore, we summarize the performance trends of LLMs under various hyperparameter settings using the RTX 6000, which features the state-of-the-art Ada Lovelace architecture. We conclude that even the same model can exhibit different behaviors depending on the hyperparameters or whether it is deployed in server or edge environments.