 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum Learning and Imitation Learning for Model-free Control on Financial Time-series
Paper and Code
Nov 22, 2023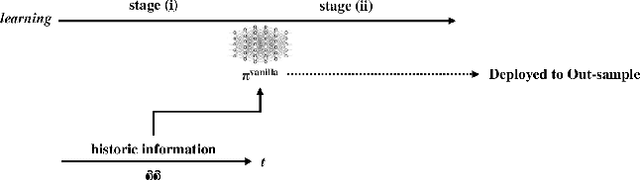

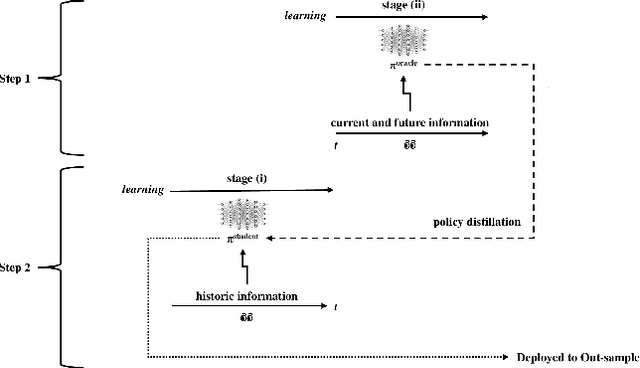
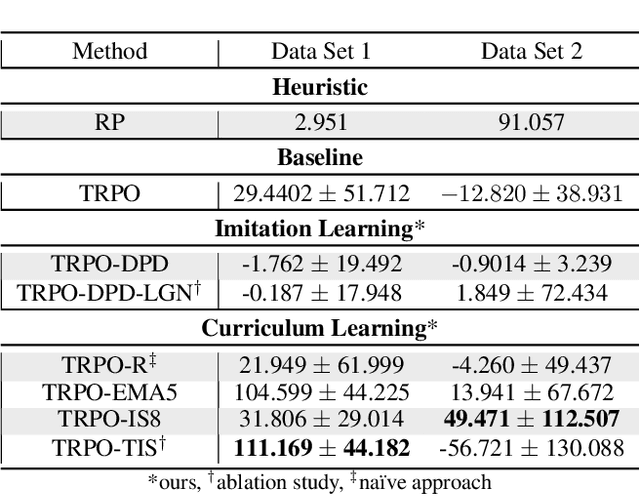
Curriculum learning and imitation learning have been leveraged extensively in the robotics domain. However, minimal research has been done on leveraging these ideas on control tasks over highly stochastic time-series data. Here, we theoretically and empirically explore these approaches in a representative control task over complex time-series data. We implement the fundamental ideas of curriculum learning via data augmentation, while imitation learning is implemented via policy distillation from an oracle. Our findings reveal that curriculum learning should be considered a novel direction in improving control-task performance over complex time-series. Our ample random-seed out-sample empirics and ablation studies are highly encouraging for curriculum learning for time-series control. These findings are especially encouraging as we tune all overlapping hyperparameters on the baseline -- giving an advantage to the baseline. On the other hand, we find that imitation learning should be used with caution.