 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSkill: Imitating Human Videos via Cross-Embodiment Skill Representations
May 15, 2025Mimicry is a fundamental learning mechanism in humans, enabling individuals to learn new tasks by observing and imitating experts. However, applying this ability to robots presents significant challenges due to the inherent differences between human and robot embodiments in both their visual appearance and physical capabilities. While previous methods bridge this gap using cross-embodiment datasets with shared scenes and tasks, collecting such aligned data between humans and robots at scale is not trivial. In this paper, we propose UniSkill, a novel framework that learns embodiment-agnostic skill representations from large-scale cross-embodiment video data without any labels, enabling skills extracted from human video prompts to effectively transfer to robot policies trained only on robot data. Our experiments in both simulation and real-world environments show that our cross-embodiment skills successfully guide robots in selecting appropriate actions, even with unseen video prompts. The project website can be found at: https://kimhanjung.github.io/UniSkill.
$C^2$: Scalable Auto-Feedback for LLM-based Chart Generation
Oct 24, 2024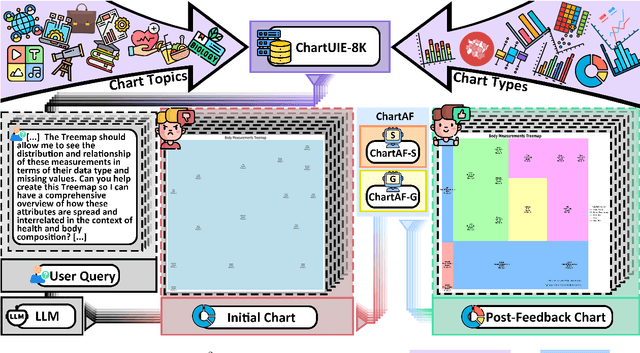

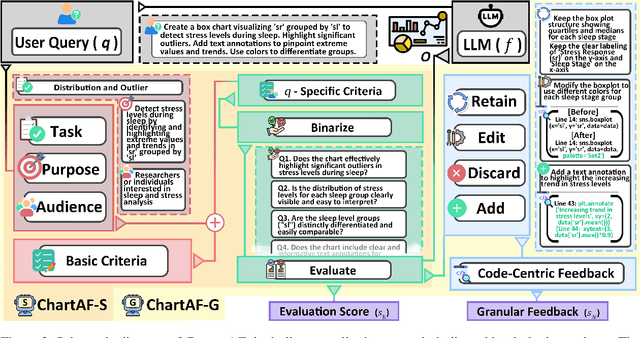

Generating high-quality charts with Large Language Models presents significant challenges due to limited data and the high cost of scaling through human curation. Instruction, data, and code triplets are scarce and expensive to manually curate as their creation demands technical expertise. To address this scalability issue, we introduce a reference-free automatic feedback generator, which eliminates the need for costly human intervention. Our novel framework, $C^2$, consists of (1) an automatic feedback provider (ChartAF) and (2) a diverse, reference-free dataset (ChartUIE-8K). Quantitative results are compelling: in our first experiment, 74% of respondents strongly preferred, and 10% preferred, the results after feedback. The second post-feedback experiment demonstrates that ChartAF outperforms nine baselines. Moreover, ChartUIE-8K significantly improves data diversity by increasing queries, datasets, and chart types by 5982%, 1936%, and 91%, respectively, over benchmarks. Finally, an LLM user study revealed that 94% of participants preferred ChartUIE-8K's queries, with 93% deeming them aligned with real-world use cases. Core contributions are available as open-source at an anonymized project site, with ample qualitative examples.
VISAGE: Video Instance Segmentation with Appearance-Guided Enhancement
Dec 08, 2023In recent years, online Video Instance Segmentation (VIS) methods have shown remarkable advancement with their powerful query-based detectors. Utilizing the output queries of the detector at the frame level, these methods achieve high accuracy on challenging benchmarks. However, we observe the heavy reliance of these methods on the location information that leads to incorrect matching when positional cues are insufficient for resolving ambiguities. Addressing this issue, we present VISAGE that enhances instance association by explicitly leveraging appearance information. Our method involves a generation of queries that embed appearances from backbone feature maps, which in turn get used in our suggested simple tracker for robust associations. Finally, enabling accurate matching in complex scenarios by resolving the issue of over-reliance on location information, we achieve competitive performance on multiple VIS benchmarks. For instance, on YTVIS19 and YTVIS21, our method achieves 54.5 AP and 50.8 AP. Furthermore, to highlight appearance-awareness not fully addressed by existing benchmarks, we generate a synthetic dataset where our method outperforms others significantly by leveraging the appearance cue. Code will be made available at https://github.com/KimHanjung/VISAGE.
Towards Interpretable Controllability in Object-Centric Learning
Oct 16, 2023The binding problem in artificial neural networks is actively explored with the goal of achieving human-level recognition skills through the comprehension of the world in terms of symbol-like entities. Especially in the field of computer vision, object-centric learning (OCL) is extensively researched to better understand complex scenes by acquiring object representations or slots. While recent studies in OCL have made strides with complex images or videos, the interpretability and interactivity over object representation remain largely uncharted, still holding promise in the field of OCL. In this paper, we introduce a novel method, Slot Attention with Image Augmentation (SlotAug), to explore the possibility of learning interpretable controllability over slots in a self-supervised manner by utilizing an image augmentation strategy. We also devise the concept of sustainability in controllable slots by introducing iterative and reversible controls over slots with two proposed submethods: Auxiliary Identity Manipulation and Slot Consistency Loss. Extensive empirical studies and theoretical validation confirm the effectiveness of our approach, offering a novel capability for interpretable and sustainable control of object representations. Code will be available soon.