Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Catapults in Momentum Gradient Descent with Warmup: An Empirical Study
Paper and Code
Nov 25, 2023
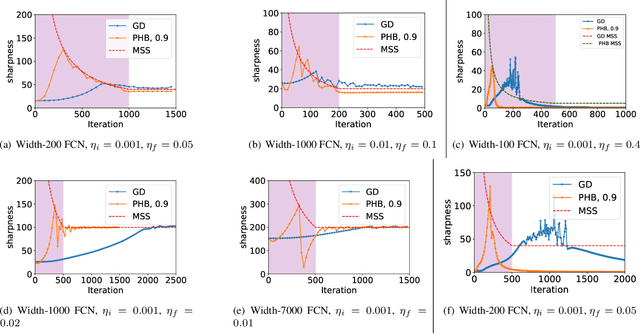
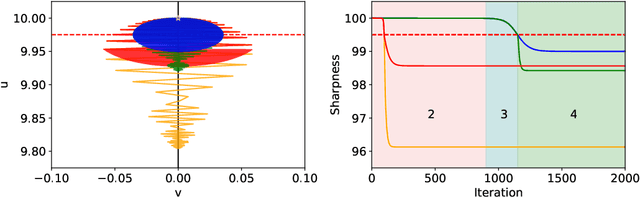

Although gradient descent with momentum is widely used in modern deep learning, a concrete understanding of its effects on the training trajectory still remains elusive. In this work, we empirically show that momentum gradient descent with a large learning rate and learning rate warmup displays large catapults, driving the iterates towards flatter minima than those found by gradient descent. We then provide empirical evidence and theoretical intuition that the large catapult is caused by momentum "amplifying" the self-stabilization effect (Damian et al., 2023).
* 19 pages, 14 figures. Accepted to the NeurIPS 2023 M3L Workshop
(oral). The first two authors contributed equally
View paper on