 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetroReasoner: A Reasoning LLM for Strategic Retrosynthesis Prediction
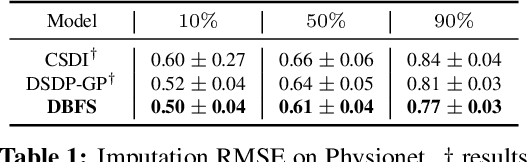
Mar 13, 2026Retrosynthesis prediction is a core task in organic synthesis that aims to predict reactants for a given product molecule. Traditionally, chemists select a plausible bond disconnection and derive corresponding reactants, which is time-consuming and requires substantial expertise. While recent advancements in molecular large language models (LLMs) have made progress, many methods either predict reactants without strategic reasoning or conduct only a generic product analysis, rather than reason explicitly about bond-disconnection strategies that logically lead to the choice of specific reactants. To overcome these limitations, we propose RetroReasoner, a retrosynthetic reasoning model that leverages chemists' strategic thinking. RetroReasoner is trained using both supervised fine-tuning (SFT) and reinforcement learning (RL). For SFT, we introduce SyntheticRetro, a framework that generates structured disconnection rationales alongside reactant predictions. In the case of RL, we apply a round-trip accuracy as reward, where predicted reactants are passed through a forward synthesis model, and predictions are rewarded when the forward-predicted product matches the original input product. Experimental results show that RetroReasoner not only outperforms prior baselines but also generates a broader range of feasible reactant proposals, particularly in handling more challenging reaction instances.
Score-informed Neural Operator for Enhancing Ordering-based Causal Discovery
Aug 18, 2025Ordering-based approaches to causal discovery identify topological orders of causal graphs, providing scalable alternatives to combinatorial search methods. Under the Additive Noise Model (ANM) assumption, recent causal ordering methods based on score matching require an accurate estimation of the Hessian diagonal of the log-densities. However, previous approaches mainly use Stein gradient estimators, which are computationally expensive and memory-intensive. Although DiffAN addresses these limitations by substituting kernel-based estimates with diffusion models, it remains numerically unstable due to the second-order derivatives of score models. To alleviate these problems, we propose Score-informed Neural Operator (SciNO), a probabilistic generative model in smooth function spaces designed to stably approximate the Hessian diagonal and to preserve structural information during the score modeling. Empirical results show that SciNO reduces order divergence by 42.7% on synthetic graphs and by 31.5% on real-world datasets on average compared to DiffAN, while maintaining memory efficiency and scalability. Furthermore, we propose a probabilistic control algorithm for causal reasoning with autoregressive models that integrates SciNO's probability estimates with autoregressive model priors, enabling reliable data-driven causal ordering informed by semantic information. Consequently, the proposed method enhances causal reasoning abilities of LLMs without additional fine-tuning or prompt engineering.
Probability-Flow ODE in Infinite-Dimensional Function Spaces
Mar 13, 2025Recent advances in infinite-dimensional diffusion models have demonstrated their effectiveness and scalability in function generation tasks where the underlying structure is inherently infinite-dimensional. To accelerate inference in such models, we derive, for the first time, an analog of the probability-flow ODE (PF-ODE) in infinite-dimensional function spaces. Leveraging this newly formulated PF-ODE, we reduce the number of function evaluations while maintaining sample quality in function generation tasks, including applications to PDEs.
Mol-LLM: Generalist Molecular LLM with Improved Graph Utilization
Feb 05, 2025



Recent advances in Large Language Models (LLMs) have motivated the development of general LLMs for molecular tasks. While several studies have demonstrated that fine-tuned LLMs can achieve impressive benchmark performances, they are far from genuine generalist molecular LLMs due to a lack of fundamental understanding of molecular structure. Specifically, when given molecular task instructions, LLMs trained with naive next-token prediction training assign similar likelihood scores to both original and negatively corrupted molecules, revealing their lack of molecular structure understanding that is crucial for reliable and general molecular LLMs. To overcome this limitation and obtain a true generalist molecular LLM, we introduce a novel multi-modal training method based on a thorough multi-modal instruction tuning as well as a molecular structure preference optimization between chosen and rejected graphs. On various molecular benchmarks, the proposed generalist molecular LLM, called Mol-LLM, achieves state-of-the-art performances among generalist LLMs on most tasks, at the same time, surpassing or comparable to state-of-the-art specialist LLMs. Moreover, Mol-LLM also shows superior generalization performances in reaction prediction tasks, demonstrating the effect of the molecular structure understanding for generalization perspective.
Scalable Multi-Task Transfer Learning for Molecular Property Prediction
Oct 01, 2024



Molecules have a number of distinct properties whose importance and application vary. Often, in reality, labels for some properties are hard to achieve despite their practical importance. A common solution to such data scarcity is to use models of good generalization with transfer learning. This involves domain experts for designing source and target tasks whose features are shared. However, this approach has limitations: i). Difficulty in accurate design of source-target task pairs due to the large number of tasks, and ii). corresponding computational burden verifying many trials and errors of transfer learning design, thereby iii). constraining the potential of foundation modeling of multi-task molecular property prediction. We address the limitations of the manual design of transfer learning via data-driven bi-level optimization. The proposed method enables scalable multi-task transfer learning for molecular property prediction by automatically obtaining the optimal transfer ratios. Empirically, the proposed method improved the prediction performance of 40 molecular properties and accelerated training convergence.
Stochastic Optimal Control for Diffusion Bridges in Function Spaces
Jun 03, 2024
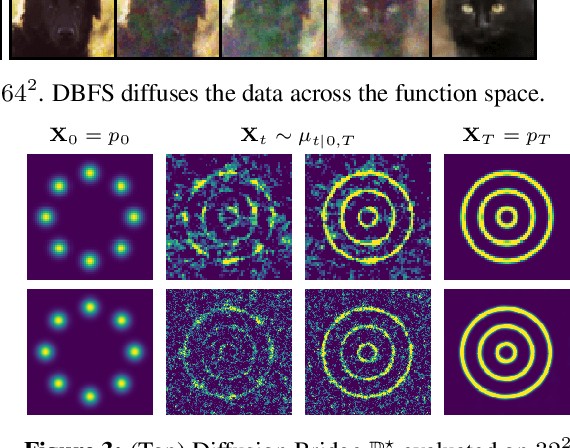
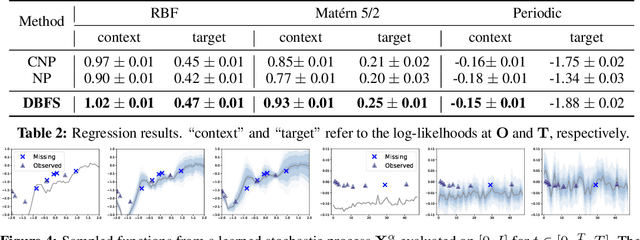
Recent advancements in diffusion models and diffusion bridges primarily focus on finite-dimensional spaces, yet many real-world problems necessitate operations in infinite-dimensional function spaces for more natural and interpretable formulations. In this paper, we present a theory of stochastic optimal control (SOC) tailored to infinite-dimensional spaces, aiming to extend diffusion-based algorithms to function spaces. Specifically, we demonstrate how Doob's $h$-transform, the fundamental tool for constructing diffusion bridges, can be derived from the SOC perspective and expanded to infinite dimensions. This expansion presents a challenge, as infinite-dimensional spaces typically lack closed-form densities. Leveraging our theory, we establish that solving the optimal control problem with a specific objective function choice is equivalent to learning diffusion-based generative models. We propose two applications: (1) learning bridges between two infinite-dimensional distributions and (2) generative models for sampling from an infinite-dimensional distribution. Our approach proves effective for diverse problems involving continuous function space representations, such as resolution-free images, time-series data, and probability density functions.
Can We Utilize Pre-trained Language Models within Causal Discovery Algorithms?
Nov 19, 2023Scaling laws have allowed Pre-trained Language Models (PLMs) into the field of causal reasoning. Causal reasoning of PLM relies solely on text-based descriptions, in contrast to causal discovery which aims to determine the causal relationships between variables utilizing data. Recently, there has been current research regarding a method that mimics causal discovery by aggregating the outcomes of repetitive causal reasoning, achieved through specifically designed prompts. It highlights the usefulness of PLMs in discovering cause and effect, which is often limited by a lack of data, especially when dealing with multiple variables. Conversely, the characteristics of PLMs which are that PLMs do not analyze data and they are highly dependent on prompt design leads to a crucial limitation for directly using PLMs in causal discovery. Accordingly, PLM-based causal reasoning deeply depends on the prompt design and carries out the risk of overconfidence and false predictions in determining causal relationships. In this paper, we empirically demonstrate the aforementioned limitations of PLM-based causal reasoning through experiments on physics-inspired synthetic data. Then, we propose a new framework that integrates prior knowledge obtained from PLM with a causal discovery algorithm. This is accomplished by initializing an adjacency matrix for causal discovery and incorporating regularization using prior knowledge. Our proposed framework not only demonstrates improved performance through the integration of PLM and causal discovery but also suggests how to leverage PLM-extracted prior knowledge with existing causal discovery algorithms.
Threshold-aware Learning to Generate Feasible Solutions for Mixed Integer Programs
Aug 01, 2023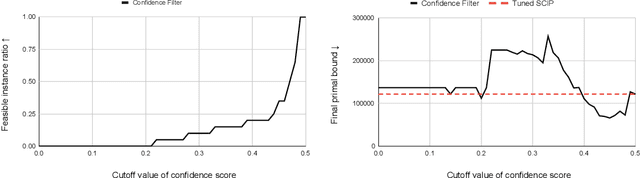

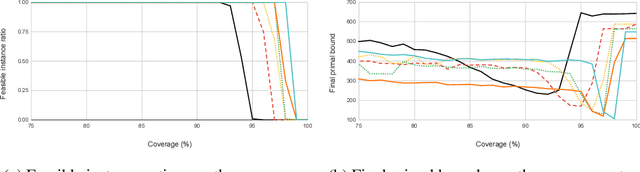
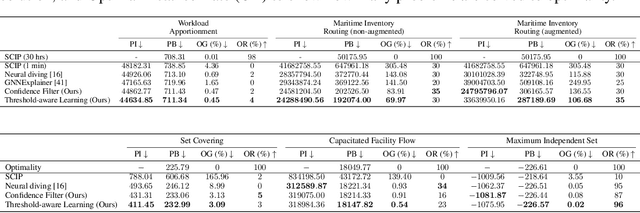
Finding a high-quality feasible solution to a combinatorial optimization (CO) problem in a limited time is challenging due to its discrete nature. Recently, there has been an increasing number of machine learning (ML) methods for addressing CO problems. Neural diving (ND) is one of the learning-based approaches to generating partial discrete variable assignments in Mixed Integer Programs (MIP), a framework for modeling CO problems. However, a major drawback of ND is a large discrepancy between the ML and MIP objectives, i.e., variable value classification accuracy over primal bound. Our study investigates that a specific range of variable assignment rates (coverage) yields high-quality feasible solutions, where we suggest optimizing the coverage bridges the gap between the learning and MIP objectives. Consequently, we introduce a post-hoc method and a learning-based approach for optimizing the coverage. A key idea of our approach is to jointly learn to restrict the coverage search space and to predict the coverage in the learned search space. Experimental results demonstrate that learning a deep neural network to estimate the coverage for finding high-quality feasible solutions achieves state-of-the-art performance in NeurIPS ML4CO datasets. In particular, our method shows outstanding performance in the workload apportionment dataset, achieving the optimality gap of 0.45%, a ten-fold improvement over SCIP within the one-minute time limit.
Bag of Tricks for In-Distribution Calibration of Pretrained Transformers
Feb 13, 2023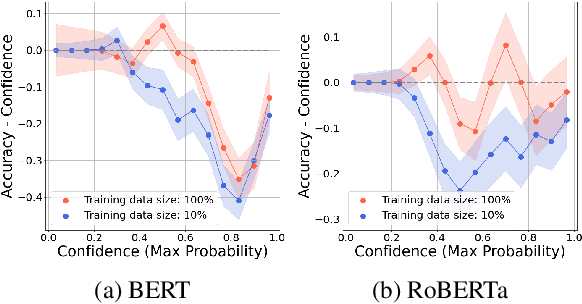
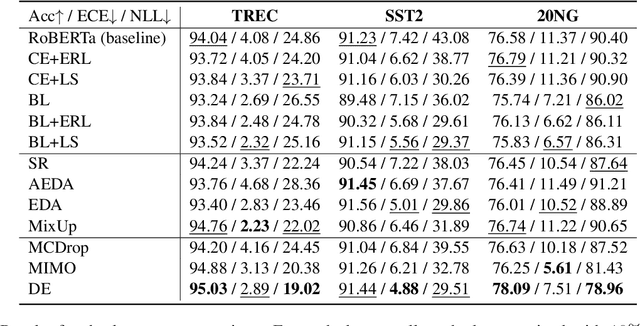
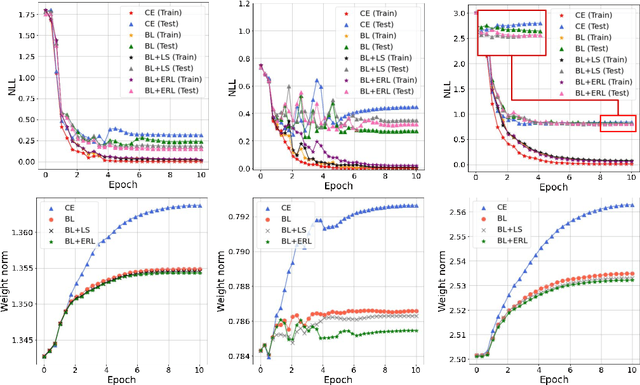
While pre-trained language models (PLMs) have become a de-facto standard promoting the accuracy of text classification tasks, recent studies find that PLMs often predict over-confidently. Although various calibration methods have been proposed, such as ensemble learning and data augmentation, most of the methods have been verified in computer vision benchmarks rather than in PLM-based text classification tasks. In this paper, we present an empirical study on confidence calibration for PLMs, addressing three categories, including confidence penalty losses, data augmentations, and ensemble methods. We find that the ensemble model overfitted to the training set shows sub-par calibration performance and also observe that PLMs trained with confidence penalty loss have a trade-off between calibration and accuracy. Building on these observations, we propose the Calibrated PLM (CALL), a combination of calibration techniques. The CALL complements the drawbacks that may occur when utilizing a calibration method individually and boosts both classification and calibration accuracy. Design choices in CALL's training procedures are extensively studied, and we provide a detailed analysis of how calibration techniques affect the calibration performance of PLMs.
A Deep Reinforcement Learning Approach for Solving the Traveling Salesman Problem with Drone
Dec 31, 2021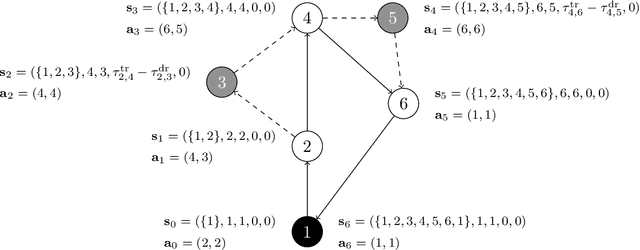
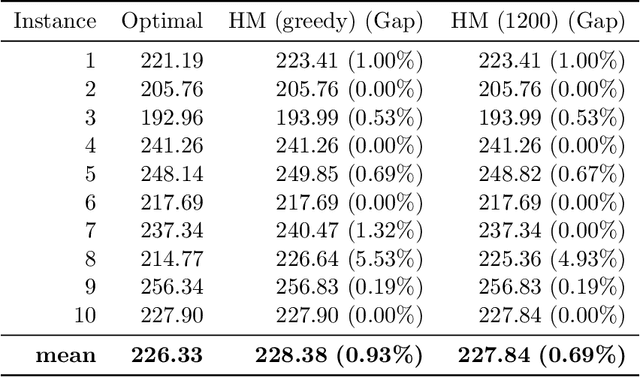
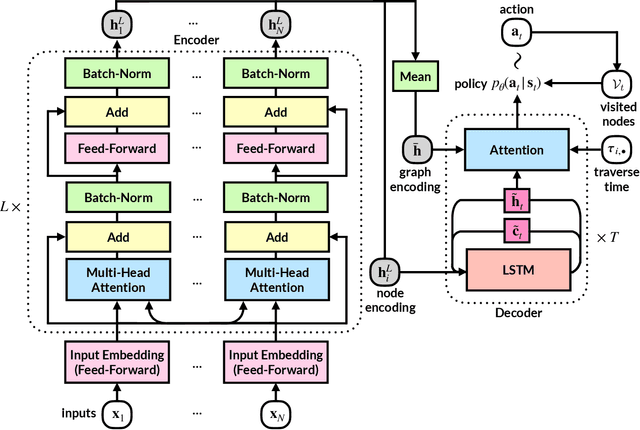
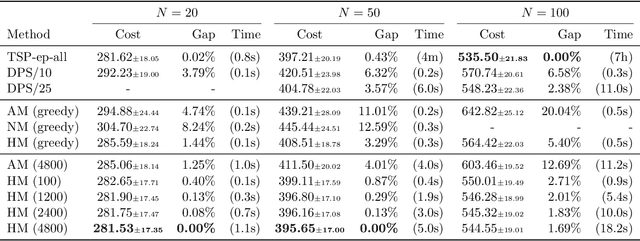
Reinforcement learning has recently shown promise in learning quality solutions in many combinatorial optimization problems. In particular, the attention-based encoder-decoder models show high effectiveness on various routing problems, including the Traveling Salesman Problem (TSP). Unfortunately, they perform poorly for the TSP with Drone (TSP-D), requiring routing a heterogeneous fleet of vehicles in coordination -- a truck and a drone. In TSP-D, the two vehicles are moving in tandem and may need to wait at a node for the other vehicle to join. State-less attention-based decoder fails to make such coordination between vehicles. We propose an attention encoder-LSTM decoder hybrid model, in which the decoder's hidden state can represent the sequence of actions made. We empirically demonstrate that such a hybrid model improves upon a purely attention-based model for both solution quality and computational efficiency. Our experiments on the min-max Capacitated Vehicle Routing Problem (mmCVRP) also confirm that the hybrid model is more suitable for coordinated routing of multiple vehicles than the attention-based model.