 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePILOT-Bench: A Benchmark for Legal Reasoning in the Patent Domain with IRAC-Aligned Classification Tasks
Jan 08, 2026The Patent Trial and Appeal Board (PTAB) of the USPTO adjudicates thousands of ex parte appeals each year, requiring the integration of technical understanding and legal reasoning. While large language models (LLMs) are increasingly applied in patent and legal practice, their use has remained limited to lightweight tasks, with no established means of systematically evaluating their capacity for structured legal reasoning in the patent domain. In this work, we introduce PILOT-Bench, the first PTAB-centric benchmark that aligns PTAB decisions with USPTO patent data at the case-level and formalizes three IRAC-aligned classification tasks: Issue Type, Board Authorities, and Subdecision. We evaluate a diverse set of closed-source (commercial) and open-source LLMs and conduct analyses across multiple perspectives, including input-variation settings, model families, and error tendencies. Notably, on the Issue Type task, closed-source models consistently exceed 0.75 in Micro-F1 score, whereas the strongest open-source model (Qwen-8B) achieves performance around 0.56, highlighting a substantial gap in reasoning capabilities. PILOT-Bench establishes a foundation for the systematic evaluation of patent-domain legal reasoning and points toward future directions for improving LLMs through dataset design and model alignment. All data, code, and benchmark resources are available at https://github.com/TeamLab/pilot-bench.
Soft Filtering: Guiding Zero-shot Composed Image Retrieval with Prescriptive and Proscriptive Constraints
Dec 23, 2025Composed Image Retrieval (CIR) aims to find a target image that aligns with user intent, expressed through a reference image and a modification text. While Zero-shot CIR (ZS-CIR) methods sidestep the need for labeled training data by leveraging pretrained vision-language models, they often rely on a single fused query that merges all descriptive cues of what the user wants, tending to dilute key information and failing to account for what they wish to avoid. Moreover, current CIR benchmarks assume a single correct target per query, overlooking the ambiguity in modification texts. To address these challenges, we propose Soft Filtering with Textual constraints (SoFT), a training-free, plug-and-play filtering module for ZS-CIR. SoFT leverages multimodal large language models (LLMs) to extract two complementary constraints from the reference-modification pair: prescriptive (must-have) and proscriptive (must-avoid) constraints. These serve as semantic filters that reward or penalize candidate images to re-rank results, without modifying the base retrieval model or adding supervision. In addition, we construct a two-stage dataset pipeline that refines CIR benchmarks. We first identify multiple plausible targets per query to construct multi-target triplets, capturing the open-ended nature of user intent. Then guide multimodal LLMs to rewrite the modification text to focus on one target, while referencing contrastive distractors to ensure precision. This enables more comprehensive and reliable evaluation under varying ambiguity levels. Applied on top of CIReVL, a ZS-CIR retriever, SoFT raises R@5 to 65.25 on CIRR (+12.94), mAP@50 to 27.93 on CIRCO (+6.13), and R@50 to 58.44 on FashionIQ (+4.59), demonstrating broad effectiveness.
STELLAR: Scene Text Editor for Low-Resource Languages and Real-World Data
Nov 14, 2025Scene Text Editing (STE) is the task of modifying text content in an image while preserving its visual style, such as font, color, and background. While recent diffusion-based approaches have shown improvements in visual quality, key limitations remain: lack of support for low-resource languages, domain gap between synthetic and real data, and the absence of appropriate metrics for evaluating text style preservation. To address these challenges, we propose STELLAR (Scene Text Editor for Low-resource LAnguages and Real-world data). STELLAR enables reliable multilingual editing through a language-adaptive glyph encoder and a multi-stage training strategy that first pre-trains on synthetic data and then fine-tunes on real images. We also construct a new dataset, STIPLAR(Scene Text Image Pairs of Low-resource lAnguages and Real-world data), for training and evaluation. Furthermore, we propose Text Appearance Similarity (TAS), a novel metric that assesses style preservation by independently measuring font, color, and background similarity, enabling robust evaluation even without ground truth. Experimental results demonstrate that STELLAR outperforms state-of-the-art models in visual consistency and recognition accuracy, achieving an average TAS improvement of 2.2% across languages over the baselines.
Multi-LLM Collaborative Caption Generation in Scientific Documents
Jan 05, 2025



Scientific figure captioning is a complex task that requires generating contextually appropriate descriptions of visual content. However, existing methods often fall short by utilizing incomplete information, treating the task solely as either an image-to-text or text summarization problem. This limitation hinders the generation of high-quality captions that fully capture the necessary details. Moreover, existing data sourced from arXiv papers contain low-quality captions, posing significant challenges for training large language models (LLMs). In this paper, we introduce a framework called Multi-LLM Collaborative Figure Caption Generation (MLBCAP) to address these challenges by leveraging specialized LLMs for distinct sub-tasks. Our approach unfolds in three key modules: (Quality Assessment) We utilize multimodal LLMs to assess the quality of training data, enabling the filtration of low-quality captions. (Diverse Caption Generation) We then employ a strategy of fine-tuning/prompting multiple LLMs on the captioning task to generate candidate captions. (Judgment) Lastly, we prompt a prominent LLM to select the highest quality caption from the candidates, followed by refining any remaining inaccuracies. Human evaluations demonstrate that informative captions produced by our approach rank better than human-written captions, highlighting its effectiveness. Our code is available at https://github.com/teamreboott/MLBCAP
DALDA: Data Augmentation Leveraging Diffusion Model and LLM with Adaptive Guidance Scaling
Sep 25, 2024



In this paper, we present an effective data augmentation framework leveraging the Large Language Model (LLM) and Diffusion Model (DM) to tackle the challenges inherent in data-scarce scenarios. Recently, DMs have opened up the possibility of generating synthetic images to complement a few training images. However, increasing the diversity of synthetic images also raises the risk of generating samples outside the target distribution. Our approach addresses this issue by embedding novel semantic information into text prompts via LLM and utilizing real images as visual prompts, thus generating semantically rich images. To ensure that the generated images remain within the target distribution, we dynamically adjust the guidance weight based on each image's CLIPScore to control the diversity. Experimental results show that our method produces synthetic images with enhanced diversity while maintaining adherence to the target distribution. Consequently, our approach proves to be more efficient in the few-shot setting on several benchmarks. Our code is available at https://github.com/kkyuhun94/dalda .
Pseudo Outlier Exposure for Out-of-Distribution Detection using Pretrained Transformers
Jul 19, 2023For real-world language applications, detecting an out-of-distribution (OOD) sample is helpful to alert users or reject such unreliable samples. However, modern over-parameterized language models often produce overconfident predictions for both in-distribution (ID) and OOD samples. In particular, language models suffer from OOD samples with a similar semantic representation to ID samples since these OOD samples lie near the ID manifold. A rejection network can be trained with ID and diverse outlier samples to detect test OOD samples, but explicitly collecting auxiliary OOD datasets brings an additional burden for data collection. In this paper, we propose a simple but effective method called Pseudo Outlier Exposure (POE) that constructs a surrogate OOD dataset by sequentially masking tokens related to ID classes. The surrogate OOD sample introduced by POE shows a similar representation to ID data, which is most effective in training a rejection network. Our method does not require any external OOD data and can be easily implemented within off-the-shelf Transformers. A comprehensive comparison with state-of-the-art algorithms demonstrates POE's competitiveness on several text classification benchmarks.
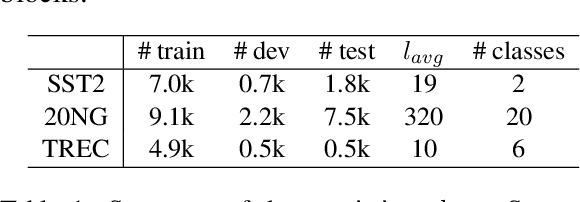
* 12 pages, 2 figures
Bag of Tricks for In-Distribution Calibration of Pretrained Transformers
Feb 13, 2023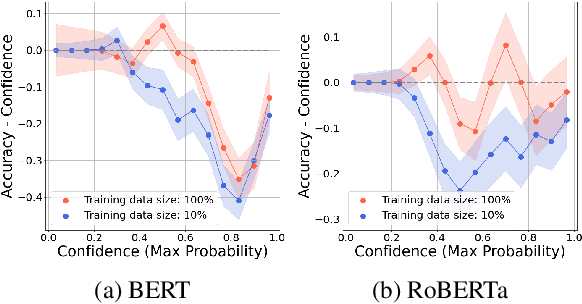
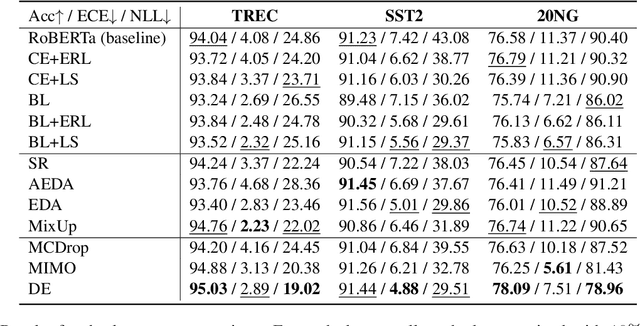
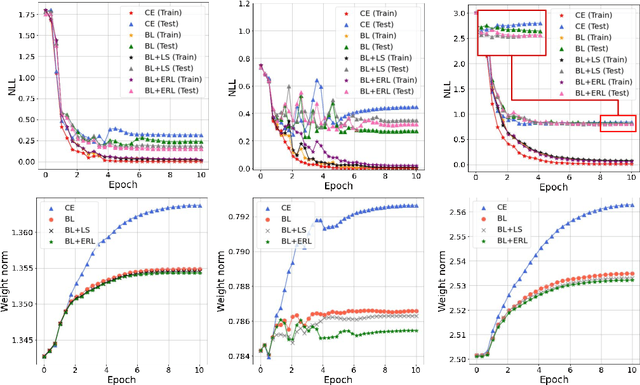
While pre-trained language models (PLMs) have become a de-facto standard promoting the accuracy of text classification tasks, recent studies find that PLMs often predict over-confidently. Although various calibration methods have been proposed, such as ensemble learning and data augmentation, most of the methods have been verified in computer vision benchmarks rather than in PLM-based text classification tasks. In this paper, we present an empirical study on confidence calibration for PLMs, addressing three categories, including confidence penalty losses, data augmentations, and ensemble methods. We find that the ensemble model overfitted to the training set shows sub-par calibration performance and also observe that PLMs trained with confidence penalty loss have a trade-off between calibration and accuracy. Building on these observations, we propose the Calibrated PLM (CALL), a combination of calibration techniques. The CALL complements the drawbacks that may occur when utilizing a calibration method individually and boosts both classification and calibration accuracy. Design choices in CALL's training procedures are extensively studied, and we provide a detailed analysis of how calibration techniques affect the calibration performance of PLMs.
Deep learning-based citation recommendation system for patents
Oct 21, 2020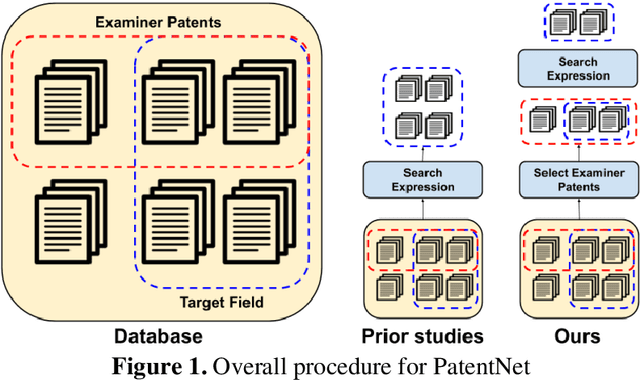
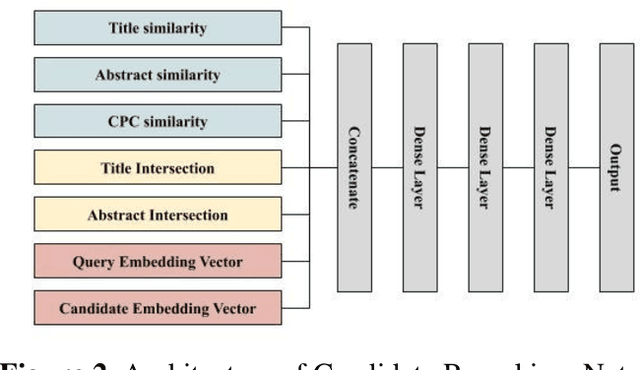

In this study, we address the challenges in developing a deep learning-based automatic patent citation recommendation system. Although deep learning-based recommendation systems have exhibited outstanding performance in various domains (such as movies, products, and paper citations), their validity in patent citations has not been investigated, owing to the lack of a freely available high-quality dataset and relevant benchmark model. To solve these problems, we present a novel dataset called PatentNet that includes textual information and metadata for approximately 110,000 patents from the Google Big Query service. Further, we propose strong benchmark models considering the similarity of textual information and metadata (such as cooperative patent classification code). Compared with existing recommendation methods, the proposed benchmark method achieved a mean reciprocal rank of 0.2377 on the test set, whereas the existing state-of-the-art recommendation method achieved 0.2073.
Machine-Learning Approach to Analyze the Status of Forklift Vehicles with Irregular Movement in a Shipyard
Oct 12, 2020

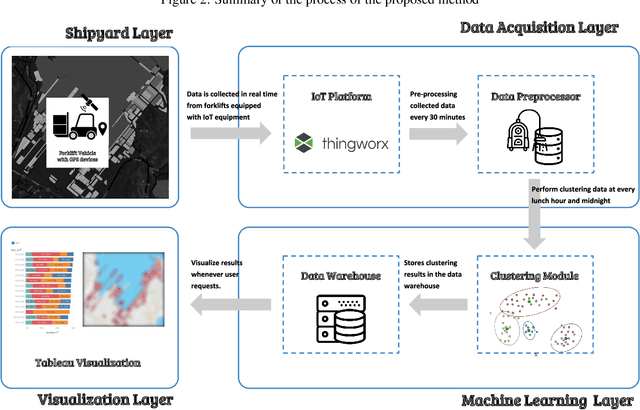

In large shipyards, the management of equipment, which are used for building a variety of ships, is critical. Because orders vary year to year, shipyard managers are required to determine methods to make the most of their limited resources. A particular difficulty that arises because of the nature and size of shipyards is the management of moving vehicles. In recent years, shipbuilding companies have attempted to manage and track the locations and movements of vehicles using Global Positioning System (GPS) modules. However, because certain vehicles, such as forklifts, roam irregularly around a yard, identifying their working status without being onsite is difficult. Location information alone is not sufficient to determine whether a vehicle is working, moving, waiting, or resting. This study proposes an approach based on machine learning to identify the work status of each forklift. We use the DBSCAN and k-means algorithms to identify the area in which a particular forklift is operating and the type of work it is performing. We developed a business intelligence system to collect information from forklifts equipped with GPS and Internet of Things (IoT) devices. The system provides visual information on the status of individual forklifts and helps in the efficient management of their movements within large shipyards.
A Context-Aware Citation Recommendation Model with BERT and Graph Convolutional Networks
Mar 15, 2019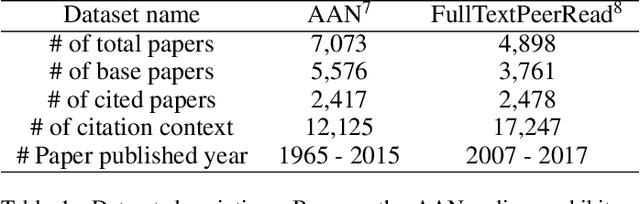

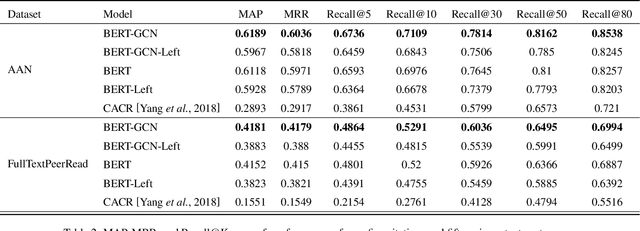
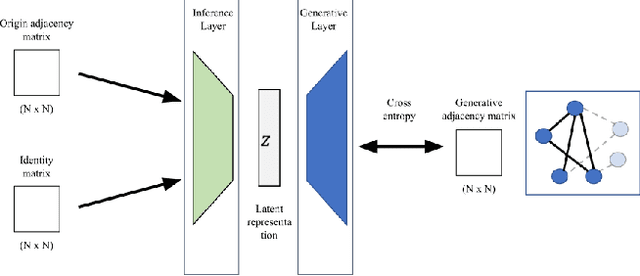
With the tremendous growth in the number of scientific papers being published, searching for references while writing a scientific paper is a time-consuming process. A technique that could add a reference citation at the appropriate place in a sentence will be beneficial. In this perspective, context-aware citation recommendation has been researched upon for around two decades. Many researchers have utilized the text data called the context sentence, which surrounds the citation tag, and the metadata of the target paper to find the appropriate cited research. However, the lack of well-organized benchmarking datasets and no model that can attain high performance has made the research difficult. In this paper, we propose a deep learning based model and well-organized dataset for context-aware paper citation recommendation. Our model comprises a document encoder and a context encoder, which uses Graph Convolutional Networks (GCN) layer and Bidirectional Encoder Representations from Transformers (BERT), which is a pre-trained model of textual data. By modifying the related PeerRead dataset, we propose a new dataset called FullTextPeerRead containing context sentences to cited references and paper metadata. To the best of our knowledge, This dataset is the first well-organized dataset for context-aware paper recommendation. The results indicate that the proposed model with the proposed datasets can attain state-of-the-art performance and achieve a more than 28% improvement in mean average precision (MAP) and recall@k.