 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Machine Learning Approach to Popularity Prediction of Newly Released Contents for Online Video Streaming Service
Jan 28, 2019
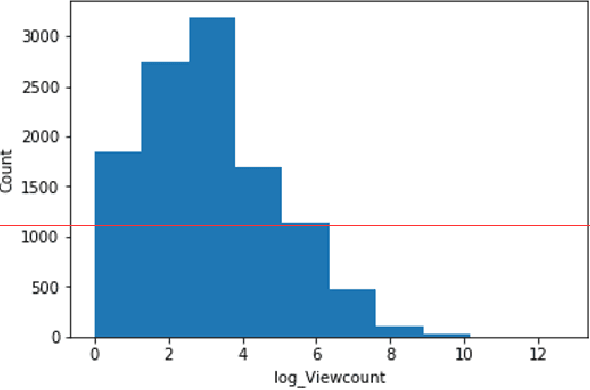
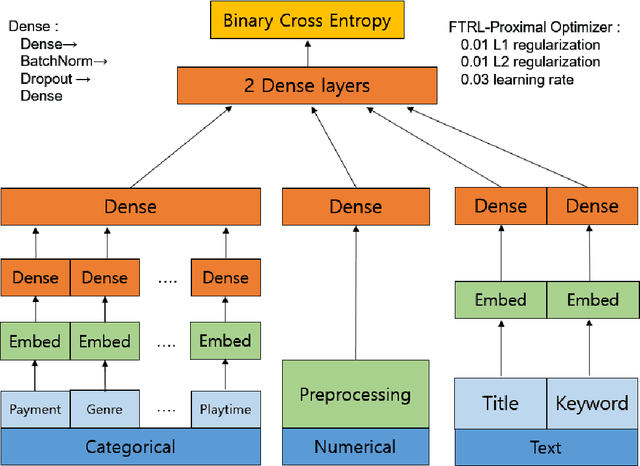
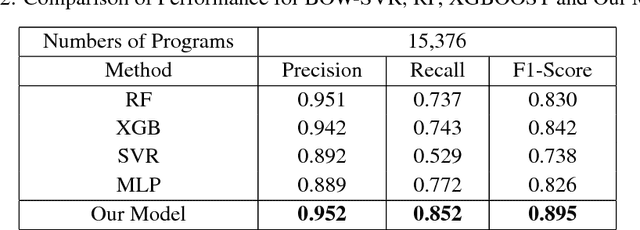
In the industry of video content providers such as VOD and IPTV, predicting the popularity of video contents in advance is critical not only from a marketing perspective but also from a network optimization perspective. By predicting whether the content will be successful or not in advance, the content file, which is large, is efficiently deployed in the proper service providing server, leading to network cost optimization. Many previous studies have done view count prediction research to do this. However, the studies have been making predictions based on historical view count data from users. In this case, the contents had been published to the users and already deployed on a service server. These approaches make possible to efficiently deploy a content already published but are impossible to use for a content that is not be published. To address the problems, this research proposes a hybrid machine learning approach to the classification model for the popularity prediction of newly video contents which is not published. In this paper, we create a new variable based on the related content of the specific content and divide entire dataset by the characteristics of the contents. Next, the prediction is performed using XGBoosting and deep neural net based model according to the data characteristics of the cluster. Our model uses metadata for contents for prediction, so we use categorical embedding techniques to solve the sparsity of categorical variables and make them learn efficiently for the deep neural net model. As well, we use the FTRL-proximal algorithm to solve the problem of the view-count volatility of video content. We achieve overall better performance than the previous standalone method with a dataset from one of the top streaming service company.