 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBag of Tricks for In-Distribution Calibration of Pretrained Transformers
Paper and Code
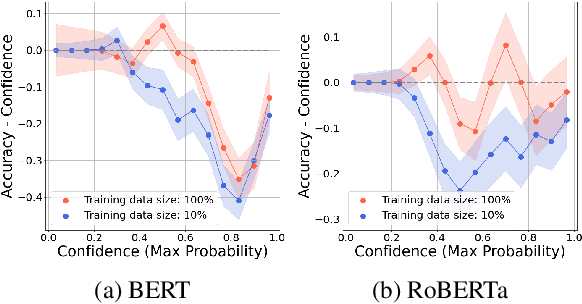
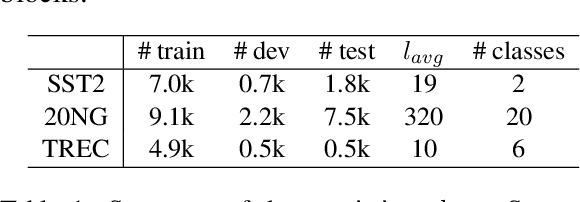
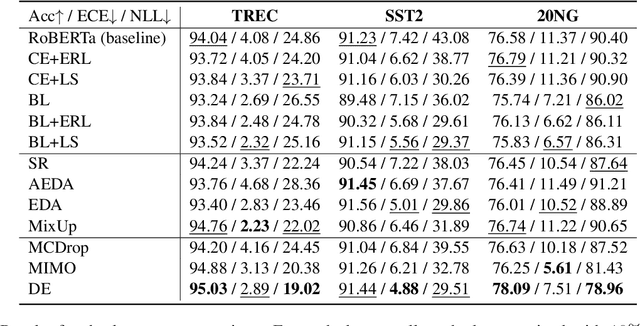
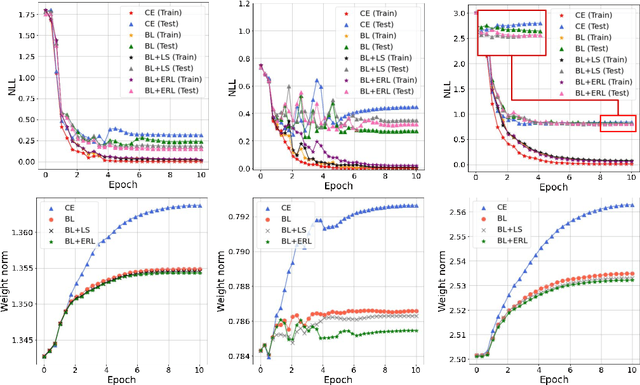
While pre-trained language models (PLMs) have become a de-facto standard promoting the accuracy of text classification tasks, recent studies find that PLMs often predict over-confidently. Although various calibration methods have been proposed, such as ensemble learning and data augmentation, most of the methods have been verified in computer vision benchmarks rather than in PLM-based text classification tasks. In this paper, we present an empirical study on confidence calibration for PLMs, addressing three categories, including confidence penalty losses, data augmentations, and ensemble methods. We find that the ensemble model overfitted to the training set shows sub-par calibration performance and also observe that PLMs trained with confidence penalty loss have a trade-off between calibration and accuracy. Building on these observations, we propose the Calibrated PLM (CALL), a combination of calibration techniques. The CALL complements the drawbacks that may occur when utilizing a calibration method individually and boosts both classification and calibration accuracy. Design choices in CALL's training procedures are extensively studied, and we provide a detailed analysis of how calibration techniques affect the calibration performance of PLMs.