 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reliable AI Model Deployments: Multiple Input Mixup for Out-of-Distribution Detection
Dec 24, 2023Recent remarkable success in the deep-learning industries has unprecedentedly increased the need for reliable model deployment. For example, the model should alert the user if the produced model outputs might not be reliable. Previous studies have proposed various methods to solve the Out-of-Distribution (OOD) detection problem, however, they generally require a burden of resources. In this work, we propose a novel and simple method, Multiple Input Mixup (MIM). Our method can help improve the OOD detection performance with only single epoch fine-tuning. Our method does not require training the model from scratch and can be attached to the classifier simply. Despite its simplicity, our MIM shows competitive performance. Our method can be suitable for various environments because our method only utilizes the In-Distribution (ID) samples to generate the synthesized OOD data. With extensive experiments with CIFAR10 and CIFAR100 benchmarks that have been largely adopted in out-of-distribution detection fields, we have demonstrated our MIM shows comprehensively superior performance compared to the SOTA method. Especially, our method does not need additional computation on the feature vectors compared to the previous studies. All source codes are publicly available at https://github.com/ndb796/MultipleInputMixup.
A New Korean Text Classification Benchmark for Recognizing the Political Intents in Online Newspapers
Nov 03, 2023



Many users reading online articles in various magazines may suffer considerable difficulty in distinguishing the implicit intents in texts. In this work, we focus on automatically recognizing the political intents of a given online newspaper by understanding the context of the text. To solve this task, we present a novel Korean text classification dataset that contains various articles. We also provide deep-learning-based text classification baseline models trained on the proposed dataset. Our dataset contains 12,000 news articles that may contain political intentions, from the politics section of six of the most representative newspaper organizations in South Korea. All the text samples are labeled simultaneously in two aspects (1) the level of political orientation and (2) the level of pro-government. To the best of our knowledge, our paper is the most large-scale Korean news dataset that contains long text and addresses multi-task classification problems. We also train recent state-of-the-art (SOTA) language models that are based on transformer architectures and demonstrate that the trained models show decent text classification performance. All the codes, datasets, and trained models are available at https://github.com/Kdavid2355/KoPolitic-Benchmark-Dataset.
Towards Machine Unlearning Benchmarks: Forgetting the Personal Identities in Facial Recognition Systems
Nov 03, 2023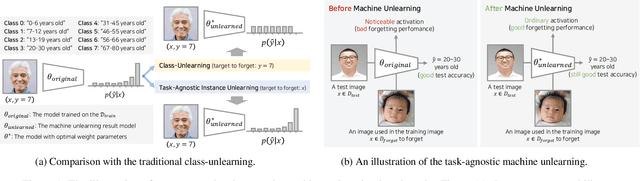

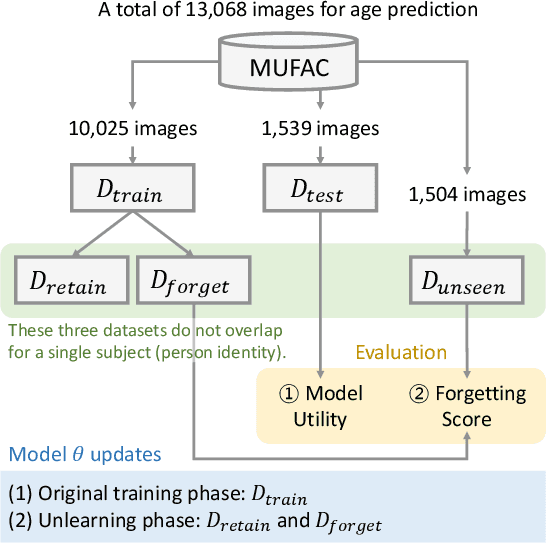

Machine unlearning is a crucial tool for enabling a classification model to forget specific data that are used in the training time. Recently, various studies have presented machine unlearning algorithms and evaluated their methods on several datasets. However, most of the current machine unlearning algorithms have been evaluated solely on traditional computer vision datasets such as CIFAR-10, MNIST, and SVHN. Furthermore, previous studies generally evaluate the unlearning methods in the class-unlearning setup. Most previous work first trains the classification models and then evaluates the machine unlearning performance of machine unlearning algorithms by forgetting selected image classes (categories) in the experiments. Unfortunately, these class-unlearning settings might not generalize to real-world scenarios. In this work, we propose a machine unlearning setting that aims to unlearn specific instance that contains personal privacy (identity) while maintaining the original task of a given model. Specifically, we propose two machine unlearning benchmark datasets, MUFAC and MUCAC, that are greatly useful to evaluate the performance and robustness of a machine unlearning algorithm. In our benchmark datasets, the original model performs facial feature recognition tasks: face age estimation (multi-class classification) and facial attribute classification (binary class classification), where a class does not depend on any single target subject (personal identity), which can be a realistic setting. Moreover, we also report the performance of the state-of-the-art machine unlearning methods on our proposed benchmark datasets. All the datasets, source codes, and trained models are publicly available at https://github.com/ndb796/MachineUnlearning.
New Benchmarks for Asian Facial Recognition Tasks: Face Classification with Large Foundation Models
Oct 15, 2023The face classification system is an important tool for recognizing personal identity properly. This paper introduces a new Large-Scale Korean Influencer Dataset named KoIn. Our presented dataset contains many real-world photos of Korean celebrities in various environments that might contain stage lighting, backup dancers, and background objects. These various images can be useful for training classification models classifying K-influencers. Most of the images in our proposed dataset have been collected from social network services (SNS) such as Instagram. Our dataset, KoIn, contains over 100,000 K-influencer photos from over 100 Korean celebrity classes. Moreover, our dataset provides additional hard case samples such as images including human faces with masks and hats. We note that the hard case samples are greatly useful in evaluating the robustness of the classification systems. We have extensively conducted several experiments utilizing various classification models to validate the effectiveness of our proposed dataset. Specifically, we demonstrate that recent state-of-the-art (SOTA) foundation architectures show decent classification performance when trained on our proposed dataset. In this paper, we also analyze the robustness performance against hard case samples of large-scale foundation models when we fine-tune the foundation models on the normal cases of the proposed dataset, KoIn. Our presented dataset and codes will be publicly available at https://github.com/dukong1/KoIn_Benchmark_Dataset.
Problem-Solving Guide: Predicting the Algorithm Tags and Difficulty for Competitive Programming Problems
Oct 09, 2023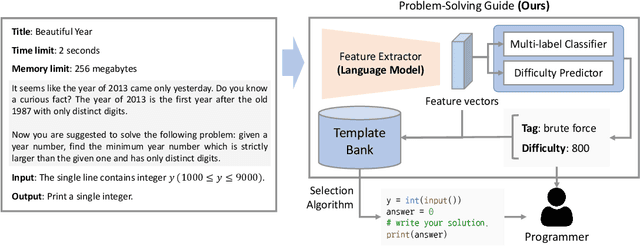
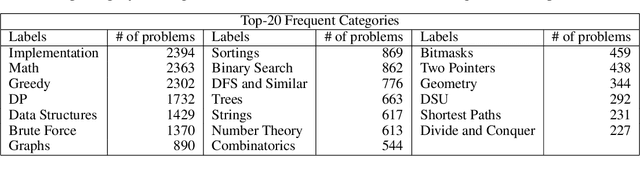
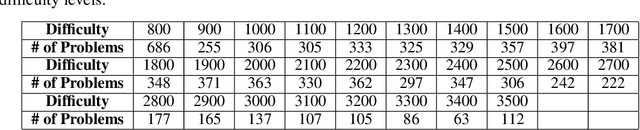
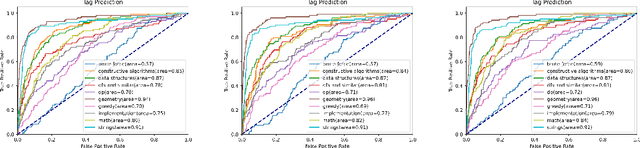
The recent program development industries have required problem-solving abilities for engineers, especially application developers. However, AI-based education systems to help solve computer algorithm problems have not yet attracted attention, while most big tech companies require the ability to solve algorithm problems including Google, Meta, and Amazon. The most useful guide to solving algorithm problems might be guessing the category (tag) of the facing problems. Therefore, our study addresses the task of predicting the algorithm tag as a useful tool for engineers and developers. Moreover, we also consider predicting the difficulty levels of algorithm problems, which can be used as useful guidance to calculate the required time to solve that problem. In this paper, we present a real-world algorithm problem multi-task dataset, AMT, by mainly collecting problem samples from the most famous and large competitive programming website Codeforces. To the best of our knowledge, our proposed dataset is the most large-scale dataset for predicting algorithm tags compared to previous studies. Moreover, our work is the first to address predicting the difficulty levels of algorithm problems. We present a deep learning-based novel method for simultaneously predicting algorithm tags and the difficulty levels of an algorithm problem given. All datasets and source codes are available at https://github.com/sronger/PSG_Predicting_Algorithm_Tags_and_Difficulty.
HOD: A Benchmark Dataset for Harmful Object Detection
Oct 08, 2023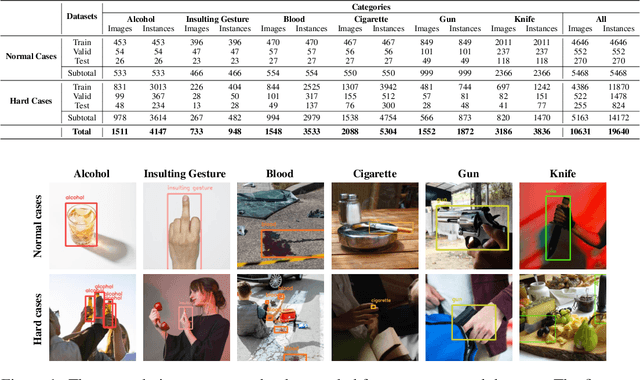
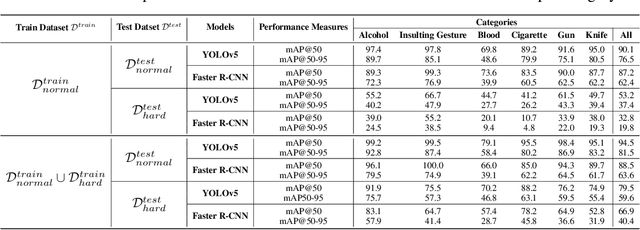

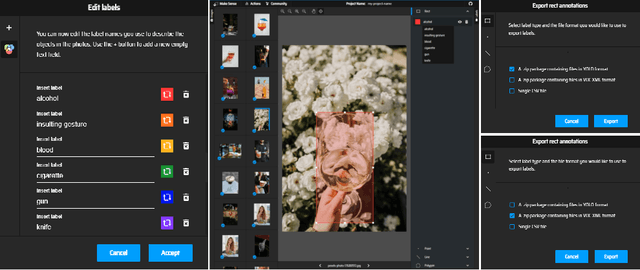
Recent multi-media data such as images and videos have been rapidly spread out on various online services such as social network services (SNS). With the explosive growth of online media services, the number of image content that may harm users is also growing exponentially. Thus, most recent online platforms such as Facebook and Instagram have adopted content filtering systems to prevent the prevalence of harmful content and reduce the possible risk of adverse effects on users. Unfortunately, computer vision research on detecting harmful content has not yet attracted attention enough. Users of each platform still manually click the report button to recognize patterns of harmful content they dislike when exposed to harmful content. However, the problem with manual reporting is that users are already exposed to harmful content. To address these issues, our research goal in this work is to develop automatic harmful object detection systems for online services. We present a new benchmark dataset for harmful object detection. Unlike most related studies focusing on a small subset of object categories, our dataset addresses various categories. Specifically, our proposed dataset contains more than 10,000 images across 6 categories that might be harmful, consisting of not only normal cases but also hard cases that are difficult to detect. Moreover, we have conducted extensive experiments to evaluate the effectiveness of our proposed dataset. We have utilized the recently proposed state-of-the-art (SOTA) object detection architectures and demonstrated our proposed dataset can be greatly useful for the real-time harmful object detection task. The whole source codes and datasets are publicly accessible at https://github.com/poori-nuna/HOD-Benchmark-Dataset.
Large-Scale Korean Text Dataset for Classifying Biased Speech in Real-World Online Services
Oct 06, 2023



With the growth of online services, the need for advanced text classification algorithms, such as sentiment analysis and biased text detection, has become increasingly evident. The anonymous nature of online services often leads to the presence of biased and harmful language, posing challenges to maintaining the health of online communities. This phenomenon is especially relevant in South Korea, where large-scale hate speech detection algorithms have not yet been broadly explored. In this paper, we introduce a new comprehensive, large-scale dataset collected from a well-known South Korean SNS platform. Our proposed dataset provides annotations including (1) Preferences, (2) Profanities, and (3) Nine types of Bias for the text samples, enabling multi-task learning for simultaneous classification of user-generated texts. Leveraging state-of-the-art BERT-based language models, our approach surpasses human-level accuracy across diverse classification tasks, as measured by various metrics. Beyond academic contributions, our work can provide practical solutions for real-world hate speech and bias mitigation, contributing directly to the improvement of online community health. Our work provides a robust foundation for future research aiming to improve the quality of online discourse and foster societal well-being. All source codes and datasets are publicly accessible at https://github.com/Dasol-Choi/KoMultiText.
Pseudo Outlier Exposure for Out-of-Distribution Detection using Pretrained Transformers
Jul 19, 2023For real-world language applications, detecting an out-of-distribution (OOD) sample is helpful to alert users or reject such unreliable samples. However, modern over-parameterized language models often produce overconfident predictions for both in-distribution (ID) and OOD samples. In particular, language models suffer from OOD samples with a similar semantic representation to ID samples since these OOD samples lie near the ID manifold. A rejection network can be trained with ID and diverse outlier samples to detect test OOD samples, but explicitly collecting auxiliary OOD datasets brings an additional burden for data collection. In this paper, we propose a simple but effective method called Pseudo Outlier Exposure (POE) that constructs a surrogate OOD dataset by sequentially masking tokens related to ID classes. The surrogate OOD sample introduced by POE shows a similar representation to ID data, which is most effective in training a rejection network. Our method does not require any external OOD data and can be easily implemented within off-the-shelf Transformers. A comprehensive comparison with state-of-the-art algorithms demonstrates POE's competitiveness on several text classification benchmarks.
* 12 pages, 2 figures
Self-accumulative Vision Transformer for Bone Age Assessment Using the Sauvegrain Method
Mar 30, 2023
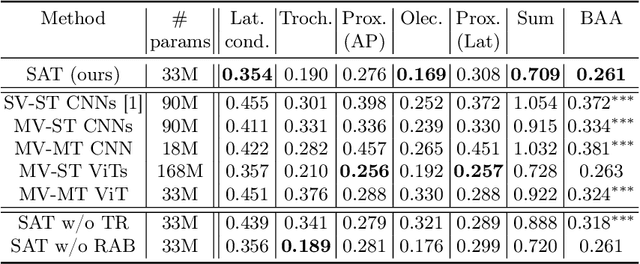
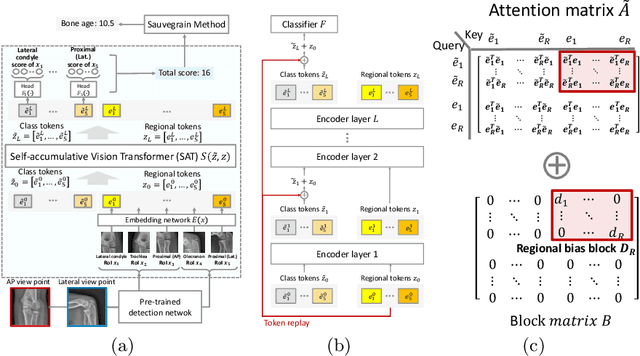
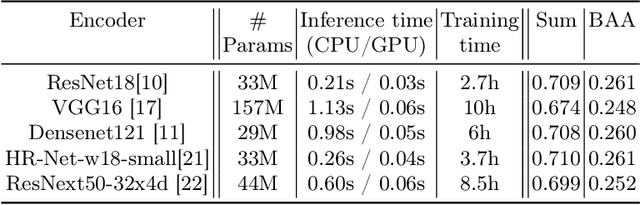
This study presents a novel approach to bone age assessment (BAA) using a multi-view, multi-task classification model based on the Sauvegrain method. A straightforward solution to automating the Sauvegrain method, which assesses a maturity score for each landmark in the elbow and predicts the bone age, is to train classifiers independently to score each region of interest (RoI), but this approach limits the accessible information to local morphologies and increases computational costs. As a result, this work proposes a self-accumulative vision transformer (SAT) that mitigates anisotropic behavior, which usually occurs in multi-view, multi-task problems and limits the effectiveness of a vision transformer, by applying token replay and regional attention bias. A number of experiments show that SAT successfully exploits the relationships between landmarks and learns global morphological features, resulting in a mean absolute error of BAA that is 0.11 lower than that of the previous work. Additionally, the proposed SAT has four times reduced parameters than an ensemble of individual classifiers of the previous work. Lastly, this work also provides informative implications for clinical practice, improving the accuracy and efficiency of BAA in diagnosing abnormal growth in adolescents.
Bag of Tricks for In-Distribution Calibration of Pretrained Transformers
Feb 13, 2023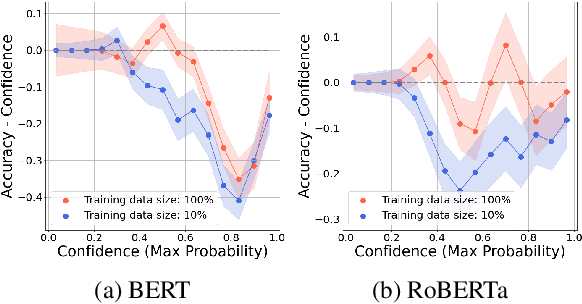
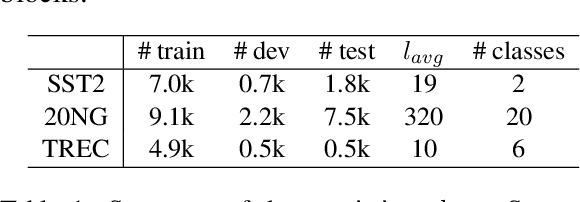
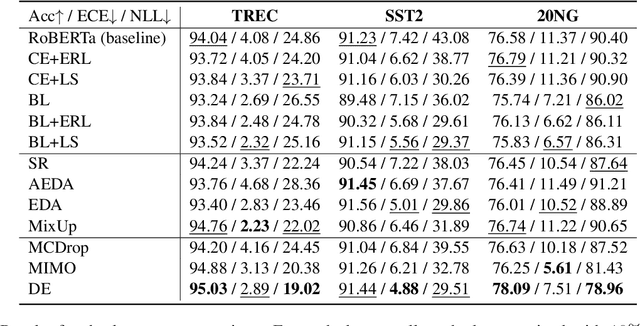
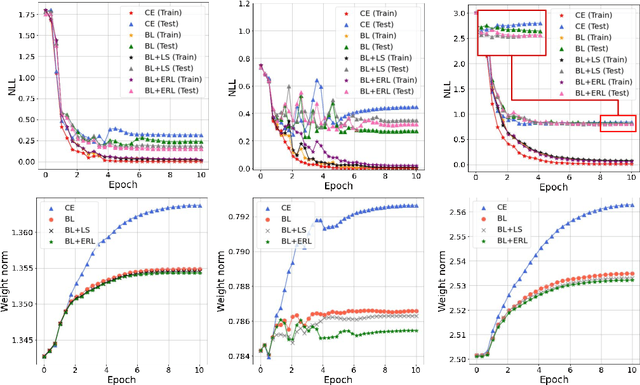
While pre-trained language models (PLMs) have become a de-facto standard promoting the accuracy of text classification tasks, recent studies find that PLMs often predict over-confidently. Although various calibration methods have been proposed, such as ensemble learning and data augmentation, most of the methods have been verified in computer vision benchmarks rather than in PLM-based text classification tasks. In this paper, we present an empirical study on confidence calibration for PLMs, addressing three categories, including confidence penalty losses, data augmentations, and ensemble methods. We find that the ensemble model overfitted to the training set shows sub-par calibration performance and also observe that PLMs trained with confidence penalty loss have a trade-off between calibration and accuracy. Building on these observations, we propose the Calibrated PLM (CALL), a combination of calibration techniques. The CALL complements the drawbacks that may occur when utilizing a calibration method individually and boosts both classification and calibration accuracy. Design choices in CALL's training procedures are extensively studied, and we provide a detailed analysis of how calibration techniques affect the calibration performance of PLMs.