 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise Schedule Design for Diffusion Models: An Optimal Control Perspective
May 21, 2026We develop a principled framework for analyzing and designing noise schedules in diffusion models. We show that one can recast this design problem as an optimal control problem, whose state is the Fisher information of the diffusion process which evolves according to an ODE and the control input is the noise schedule. The objective of the optimal control problem is a functional involving the Fisher information, which is shown to be an upper bound on the Kullback-Leibler sampling error. By solving this optimal control problem, we obtain sufficient conditions on noise schedules under which state-of-the-art $\tilde{\mathcal{O}} (d/n)$ sampling error is achievable, where $d$ is the data dimension and $n$ is the number of discretization steps. While existing theoretical work also prove that $\tilde{\mathcal{O}}(d/n)$ sampling error bounds are achievable, these results hold for specific noise schedules, which do not include the schedules used in practice. Under a further parametric assumption on the data distribution, we show that one can obtain closed-form expressions for the noise schedules. These noise schedules generalize standard empirical schedules such as exponential and sigmoid schedules by allowing additional parameters that can be tuned. Systematically tuning the parameters of these schedules yields new schedules that achieve superior FID scores on image generation benchmarks.
Finite-Sample Wasserstein Error Bounds and Concentration Inequalities for Nonlinear Stochastic Approximation
Feb 02, 2026This paper derives non-asymptotic error bounds for nonlinear stochastic approximation algorithms in the Wasserstein-$p$ distance. To obtain explicit finite-sample guarantees for the last iterate, we develop a coupling argument that compares the discrete-time process to a limiting Ornstein-Uhlenbeck process. Our analysis applies to algorithms driven by general noise conditions, including martingale differences and functions of ergodic Markov chains. Complementing this result, we handle the convergence rate of the Polyak-Ruppert average through a direct analysis that applies under the same general setting. Assuming the driving noise satisfies a non-asymptotic central limit theorem, we show that the normalized last iterates converge to a Gaussian distribution in the $p$-Wasserstein distance at a rate of order $γ_n^{1/6}$, where $γ_n$ is the step size. Similarly, the Polyak-Ruppert average is shown to converge in the Wasserstein distance at a rate of order $n^{-1/6}$. These distributional guarantees imply high-probability concentration inequalities that improve upon those derived from moment bounds and Markov's inequality. We demonstrate the utility of this approach by considering two applications: (1) linear stochastic approximation, where we explicitly quantify the transition from heavy-tailed to Gaussian behavior of the iterates, thereby bridging the gap between recent finite-sample analyses and asymptotic theory and (2) stochastic gradient descent, where we establish rate of convergence to the central limit theorem.
Self-accumulative Vision Transformer for Bone Age Assessment Using the Sauvegrain Method
Mar 30, 2023
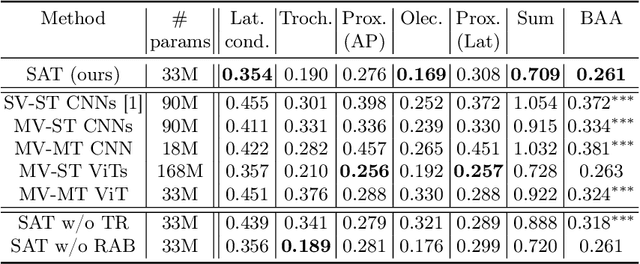
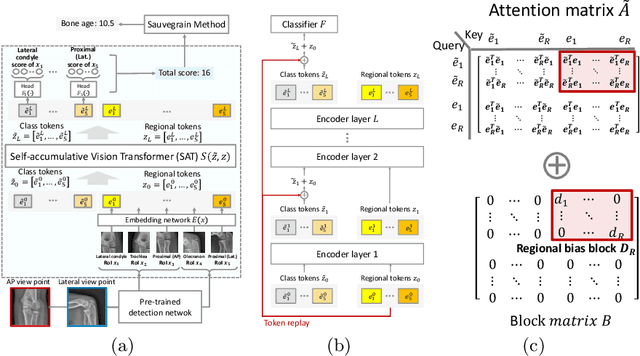
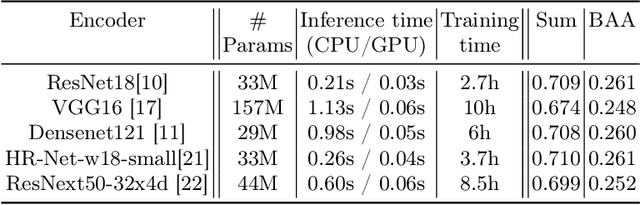
This study presents a novel approach to bone age assessment (BAA) using a multi-view, multi-task classification model based on the Sauvegrain method. A straightforward solution to automating the Sauvegrain method, which assesses a maturity score for each landmark in the elbow and predicts the bone age, is to train classifiers independently to score each region of interest (RoI), but this approach limits the accessible information to local morphologies and increases computational costs. As a result, this work proposes a self-accumulative vision transformer (SAT) that mitigates anisotropic behavior, which usually occurs in multi-view, multi-task problems and limits the effectiveness of a vision transformer, by applying token replay and regional attention bias. A number of experiments show that SAT successfully exploits the relationships between landmarks and learns global morphological features, resulting in a mean absolute error of BAA that is 0.11 lower than that of the previous work. Additionally, the proposed SAT has four times reduced parameters than an ensemble of individual classifiers of the previous work. Lastly, this work also provides informative implications for clinical practice, improving the accuracy and efficiency of BAA in diagnosing abnormal growth in adolescents.
A Provably Improved Algorithm for Crowdsourcing with Hard and Easy Tasks
Feb 14, 2023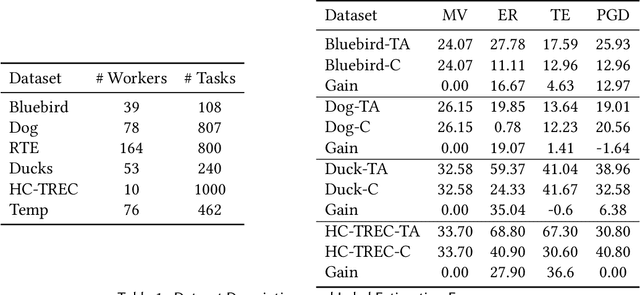
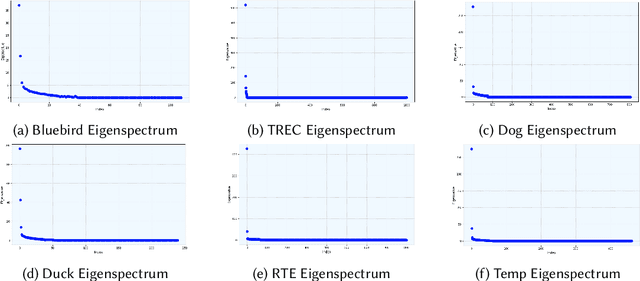
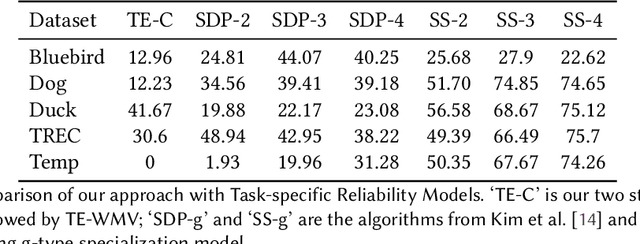
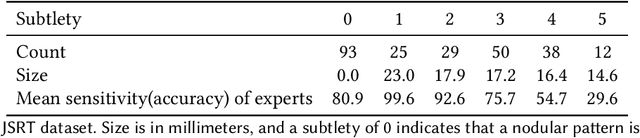
Crowdsourcing is a popular method used to estimate ground-truth labels by collecting noisy labels from workers. In this work, we are motivated by crowdsourcing applications where each worker can exhibit two levels of accuracy depending on a task's type. Applying algorithms designed for the traditional Dawid-Skene model to such a scenario results in performance which is limited by the hard tasks. Therefore, we first extend the model to allow worker accuracy to vary depending on a task's unknown type. Then we propose a spectral method to partition tasks by type. After separating tasks by type, any Dawid-Skene algorithm (i.e., any algorithm designed for the Dawid-Skene model) can be applied independently to each type to infer the truth values. We theoretically prove that when crowdsourced data contain tasks with varying levels of difficulty, our algorithm infers the true labels with higher accuracy than any Dawid-Skene algorithm. Experiments show that our method is effective in practical applications.
Relieving the Plateau: Active Semi-Supervised Learning for a Better Landscape
Apr 08, 2021


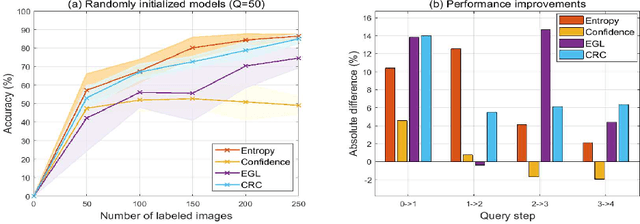
Deep learning (DL) relies on massive amounts of labeled data, and improving its labeled sample-efficiency remains one of the most important problems since its advent. Semi-supervised learning (SSL) leverages unlabeled data that are more accessible than their labeled counterparts. Active learning (AL) selects unlabeled instances to be annotated by a human-in-the-loop in hopes of better performance with less labeled data. Given the accessible pool of unlabeled data in pool-based AL, it seems natural to use SSL when training and AL to update the labeled set; however, algorithms designed for their combination remain limited. In this work, we first prove that convergence of gradient descent on sufficiently wide ReLU networks can be expressed in terms of their Gram matrix' eigen-spectrum. Equipped with a few theoretical insights, we propose convergence rate control (CRC), an AL algorithm that selects unlabeled data to improve the problem conditioning upon inclusion to the labeled set, by formulating an acquisition step in terms of improving training dynamics. Extensive experiments show that SSL algorithms coupled with CRC can achieve high performance using very few labeled data.
Almost Boltzmann Exploration
Jan 25, 2019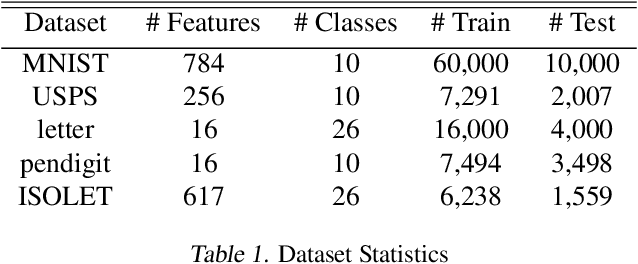
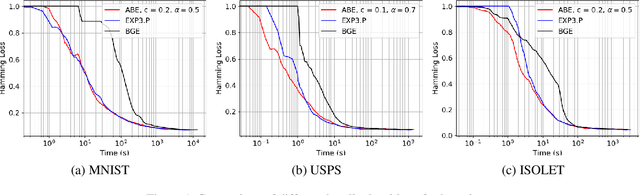
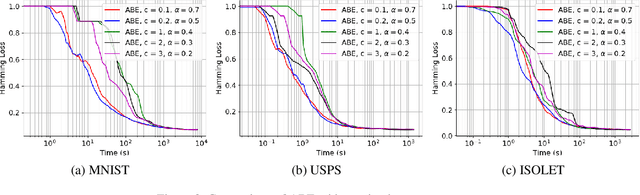
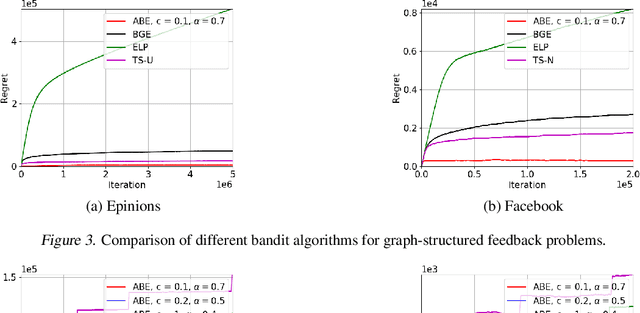
Boltzmann exploration is widely used in reinforcement learning to provide a trade-off between exploration and exploitation. Recently, in (Cesa-Bianchi et al., 2017) it has been shown that pure Boltzmann exploration does not perform well from a regret perspective, even in the simplest setting of stochastic multi-armed bandit (MAB) problems. In this paper, we show that a simple modification to Boltzmann exploration, motivated by a variation of the standard doubling trick, achieves $O(K\log^{1+\alpha} T)$ regret for a stochastic MAB problem with $K$ arms, where $\alpha>0$ is a parameter of the algorithm. This improves on the result in (Cesa-Bianchi et al., 2017), where an algorithm inspired by the Gumbel-softmax trick achieves $O(K\log^2 T)$ regret. We also show that our algorithm achieves $O(\beta(G) \log^{1+\alpha} T)$ regret in stochastic MAB problems with graph-structured feedback, without knowledge of the graph structure, where $\beta(G)$ is the independence number of the feedback graph. Additionally, we present extensive experimental results on real datasets and applications for multi-armed bandits with both traditional bandit feedback and graph-structured feedback. In all cases, our algorithm performs as well or better than the state-of-the-art.