 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Provably Improved Algorithm for Crowdsourcing with Hard and Easy Tasks
Paper and Code
Feb 14, 2023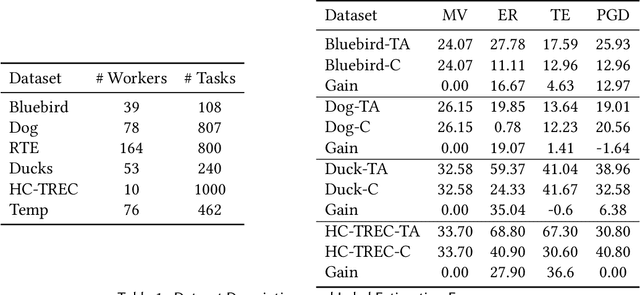
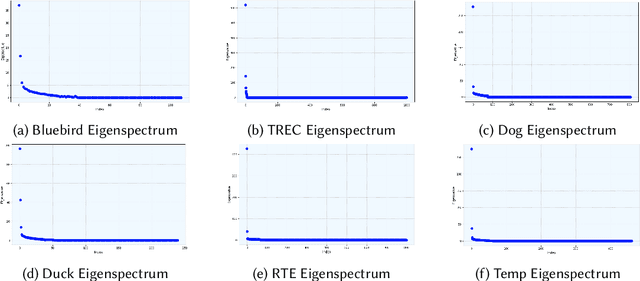
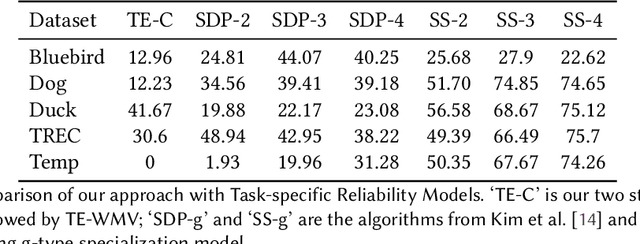
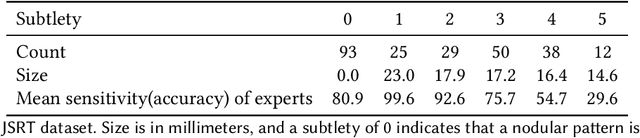
Crowdsourcing is a popular method used to estimate ground-truth labels by collecting noisy labels from workers. In this work, we are motivated by crowdsourcing applications where each worker can exhibit two levels of accuracy depending on a task's type. Applying algorithms designed for the traditional Dawid-Skene model to such a scenario results in performance which is limited by the hard tasks. Therefore, we first extend the model to allow worker accuracy to vary depending on a task's unknown type. Then we propose a spectral method to partition tasks by type. After separating tasks by type, any Dawid-Skene algorithm (i.e., any algorithm designed for the Dawid-Skene model) can be applied independently to each type to infer the truth values. We theoretically prove that when crowdsourced data contain tasks with varying levels of difficulty, our algorithm infers the true labels with higher accuracy than any Dawid-Skene algorithm. Experiments show that our method is effective in practical applications.