 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Provably Improved Algorithm for Crowdsourcing with Hard and Easy Tasks
Feb 14, 2023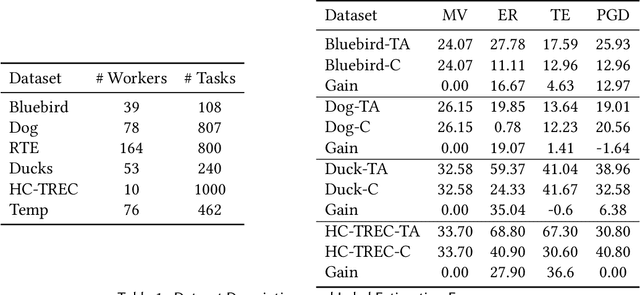
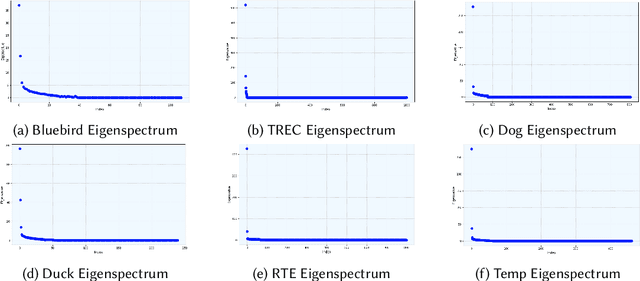
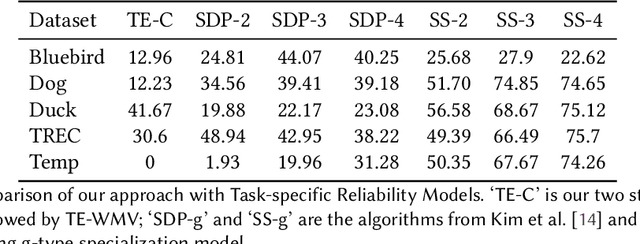
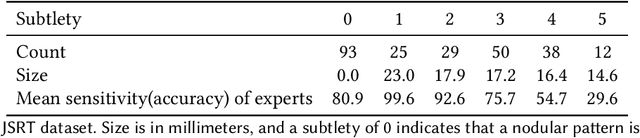
Crowdsourcing is a popular method used to estimate ground-truth labels by collecting noisy labels from workers. In this work, we are motivated by crowdsourcing applications where each worker can exhibit two levels of accuracy depending on a task's type. Applying algorithms designed for the traditional Dawid-Skene model to such a scenario results in performance which is limited by the hard tasks. Therefore, we first extend the model to allow worker accuracy to vary depending on a task's unknown type. Then we propose a spectral method to partition tasks by type. After separating tasks by type, any Dawid-Skene algorithm (i.e., any algorithm designed for the Dawid-Skene model) can be applied independently to each type to infer the truth values. We theoretically prove that when crowdsourced data contain tasks with varying levels of difficulty, our algorithm infers the true labels with higher accuracy than any Dawid-Skene algorithm. Experiments show that our method is effective in practical applications.
On the Consistency of Maximum Likelihood Estimators for Causal Network Identification
Oct 17, 2020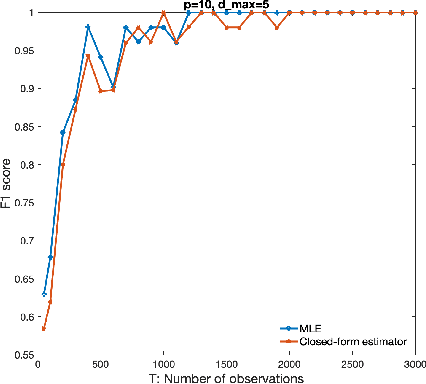
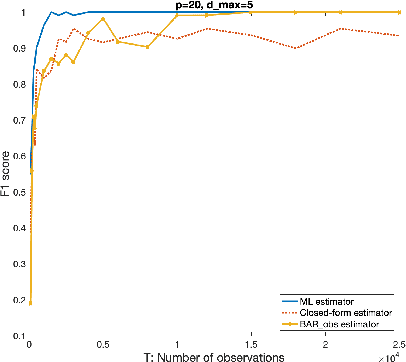
We consider the problem of identifying parameters of a particular class of Markov chains, called Bernoulli Autoregressive (BAR) processes. The structure of any BAR model is encoded by a directed graph. Incoming edges to a node in the graph indicate that the state of the node at a particular time instant is influenced by the states of the corresponding parental nodes in the previous time instant. The associated edge weights determine the corresponding level of influence from each parental node. In the simplest setup, the Bernoulli parameter of a particular node's state variable is a convex combination of the parental node states in the previous time instant and an additional Bernoulli noise random variable. This paper focuses on the problem of edge weight identification using Maximum Likelihood (ML) estimation and proves that the ML estimator is strongly consistent for two variants of the BAR model. We additionally derive closed-form estimators for the aforementioned two variants and prove their strong consistency.
Mixing Times and Structural Inference for Bernoulli Autoregressive Processes
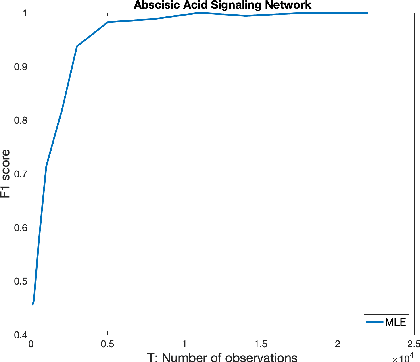
Dec 19, 2016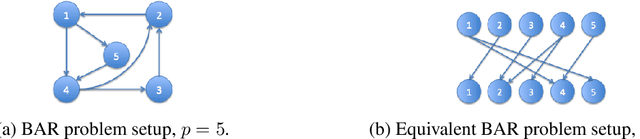
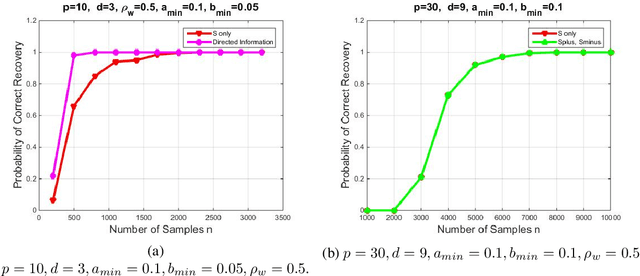
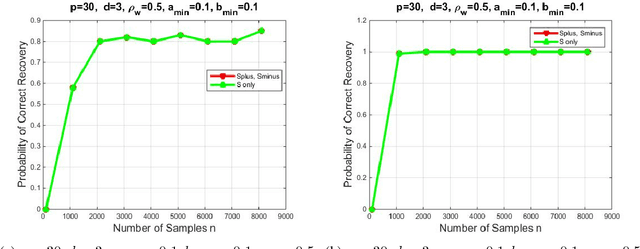
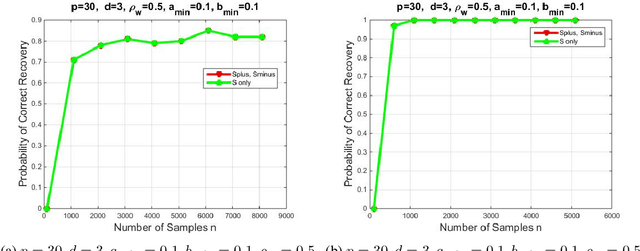
We introduce a novel multivariate random process producing Bernoulli outputs per dimension, that can possibly formalize binary interactions in various graphical structures and can be used to model opinion dynamics, epidemics, financial and biological time series data, etc. We call this a Bernoulli Autoregressive Process (BAR). A BAR process models a discrete-time vector random sequence of $p$ scalar Bernoulli processes with autoregressive dynamics and corresponds to a particular Markov Chain. The benefit from the autoregressive dynamics is the description of a $2^p\times 2^p$ transition matrix by at most $pd$ effective parameters for some $d\ll p$ or by two sparse matrices of dimensions $p\times p^2$ and $p\times p$, respectively, parameterizing the transitions. Additionally, we show that the BAR process mixes rapidly, by proving that the mixing time is $O(\log p)$. The hidden constant in the previous mixing time bound depends explicitly on the values of the chain parameters and implicitly on the maximum allowed in-degree of a node in the corresponding graph. For a network with $p$ nodes, where each node has in-degree at most $d$ and corresponds to a scalar Bernoulli process generated by a BAR, we provide a greedy algorithm that can efficiently learn the structure of the underlying directed graph with a sample complexity proportional to the mixing time of the BAR process. The sample complexity of the proposed algorithm is nearly order-optimal as it is only a $\log p$ factor away from an information-theoretic lower bound. We present simulation results illustrating the performance of our algorithm in various setups, including a model for a biological signaling network.
A MAP approach for $\ell_q$-norm regularized sparse parameter estimation using the EM algorithm
Aug 05, 2015



In this paper, Bayesian parameter estimation through the consideration of the Maximum A Posteriori (MAP) criterion is revisited under the prism of the Expectation-Maximization (EM) algorithm. By incorporating a sparsity-promoting penalty term in the cost function of the estimation problem through the use of an appropriate prior distribution, we show how the EM algorithm can be used to efficiently solve the corresponding optimization problem. To this end, we rely on variance-mean Gaussian mixtures (VMGM) to describe the prior distribution, while we incorporate many nice features of these mixtures to our estimation problem. The corresponding MAP estimation problem is completely expressed in terms of the EM algorithm, which allows for handling nonlinearities and hidden variables that cannot be easily handled with traditional methods. For comparison purposes, we also develop a Coordinate Descent algorithm for the $\ell_q$-norm penalized problem and present the performance results via simulations.
Estimator Selection: End-Performance Metric Aspects
Jul 26, 2015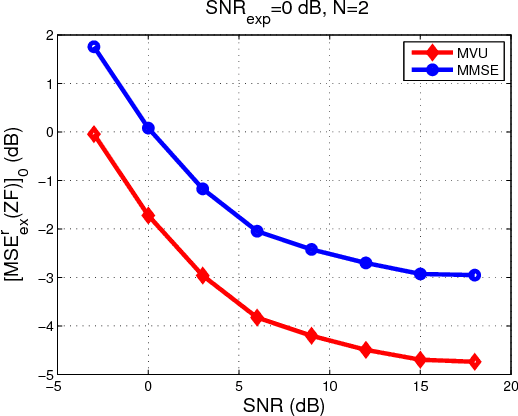
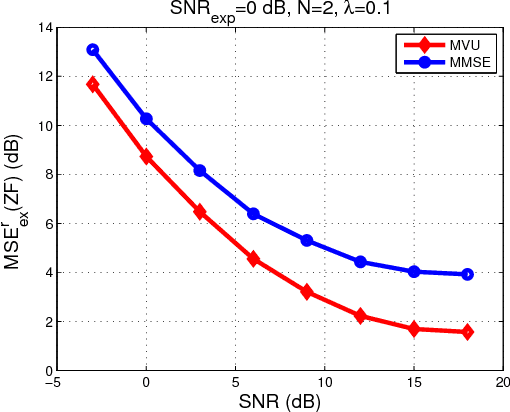
Recently, a framework for application-oriented optimal experiment design has been introduced. In this context, the distance of the estimated system from the true one is measured in terms of a particular end-performance metric. This treatment leads to superior unknown system estimates to classical experiment designs based on usual pointwise functional distances of the estimated system from the true one. The separation of the system estimator from the experiment design is done within this new framework by choosing and fixing the estimation method to either a maximum likelihood (ML) approach or a Bayesian estimator such as the minimum mean square error (MMSE). Since the MMSE estimator delivers a system estimate with lower mean square error (MSE) than the ML estimator for finite-length experiments, it is usually considered the best choice in practice in signal processing and control applications. Within the application-oriented framework a related meaningful question is: Are there end-performance metrics for which the ML estimator outperforms the MMSE when the experiment is finite-length? In this paper, we affirmatively answer this question based on a simple linear Gaussian regression example.
A Note on the SPICE Method
Sep 21, 2012
In this article, we analyze the SPICE method developed in [1], and establish its connections with other standard sparse estimation methods such as the Lasso and the LAD-Lasso. This result positions SPICE as a computationally efficient technique for the calculation of Lasso-type estimators. Conversely, this connection is very useful for establishing the asymptotic properties of SPICE under several problem scenarios and for suggesting suitable modifications in cases where the naive version of SPICE would not work.