 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite-Time Bounds for Distributionally Robust TD Learning with Linear Function Approximation
Oct 02, 2025Distributionally robust reinforcement learning (DRRL) focuses on designing policies that achieve good performance under model uncertainties. In particular, we are interested in maximizing the worst-case long-term discounted reward, where the data for RL comes from a nominal model while the deployed environment can deviate from the nominal model within a prescribed uncertainty set. Existing convergence guarantees for robust temporal-difference (TD) learning for policy evaluation are limited to tabular MDPs or are dependent on restrictive discount-factor assumptions when function approximation is used. We present the first robust TD learning with linear function approximation, where robustness is measured with respect to the total-variation distance and Wasserstein-l distance uncertainty set. Additionally, our algorithm is both model-free and does not require generative access to the MDP. Our algorithm combines a two-time-scale stochastic-approximation update with an outer-loop target-network update. We establish an $\tilde{O}(1/\epsilon^2)$ sample complexity to obtain an $\epsilon$-accurate value estimate. Our results close a key gap between the empirical success of robust RL algorithms and the non-asymptotic guarantees enjoyed by their non-robust counterparts. The key ideas in the paper also extend in a relatively straightforward fashion to robust Q-learning with function approximation.
Finite-Horizon Single-Pull Restless Bandits: An Efficient Index Policy For Scarce Resource Allocation
Jan 10, 2025Restless multi-armed bandits (RMABs) have been highly successful in optimizing sequential resource allocation across many domains. However, in many practical settings with highly scarce resources, where each agent can only receive at most one resource, such as healthcare intervention programs, the standard RMAB framework falls short. To tackle such scenarios, we introduce Finite-Horizon Single-Pull RMABs (SPRMABs), a novel variant in which each arm can only be pulled once. This single-pull constraint introduces additional complexity, rendering many existing RMAB solutions suboptimal or ineffective. %To address this, we propose using dummy states to duplicate the system, ensuring that once an arm is activated, it transitions exclusively within the dummy states. To address this shortcoming, we propose using \textit{dummy states} that expand the system and enforce the one-pull constraint. We then design a lightweight index policy for this expanded system. For the first time, we demonstrate that our index policy achieves a sub-linearly decaying average optimality gap of $\tilde{\mathcal{O}}\left(\frac{1}{\rho^{1/2}}\right)$ for a finite number of arms, where $\rho$ is the scaling factor for each arm cluster. Extensive simulations validate the proposed method, showing robust performance across various domains compared to existing benchmarks.
A Theoretical Analysis of Soft-Label vs Hard-Label Training in Neural Networks
Dec 12, 2024
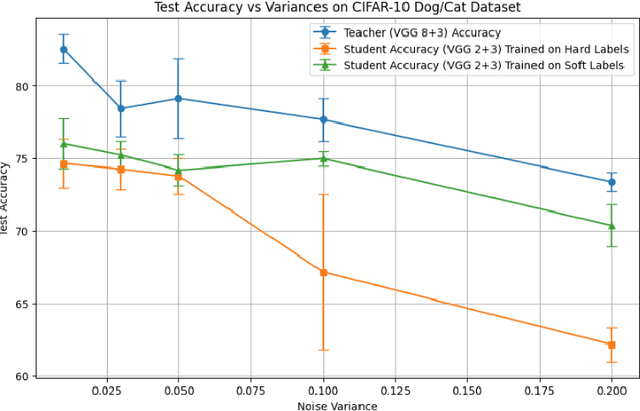
Knowledge distillation, where a small student model learns from a pre-trained large teacher model, has achieved substantial empirical success since the seminal work of \citep{hinton2015distilling}. Despite prior theoretical studies exploring the benefits of knowledge distillation, an important question remains unanswered: why does soft-label training from the teacher require significantly fewer neurons than directly training a small neural network with hard labels? To address this, we first present motivating experimental results using simple neural network models on a binary classification problem. These results demonstrate that soft-label training consistently outperforms hard-label training in accuracy, with the performance gap becoming more pronounced as the dataset becomes increasingly difficult to classify. We then substantiate these observations with a theoretical contribution based on two-layer neural network models. Specifically, we show that soft-label training using gradient descent requires only $O\left(\frac{1}{\gamma^2 \epsilon}\right)$ neurons to achieve a classification loss averaged over epochs smaller than some $\epsilon > 0$, where $\gamma$ is the separation margin of the limiting kernel. In contrast, hard-label training requires $O\left(\frac{1}{\gamma^4} \cdot \ln\left(\frac{1}{\epsilon}\right)\right)$ neurons, as derived from an adapted version of the gradient descent analysis in \citep{ji2020polylogarithmic}. This implies that when $\gamma \leq \epsilon$, i.e., when the dataset is challenging to classify, the neuron requirement for soft-label training can be significantly lower than that for hard-label training. Finally, we present experimental results on deep neural networks, further validating these theoretical findings.
A Provably Improved Algorithm for Crowdsourcing with Hard and Easy Tasks
Feb 14, 2023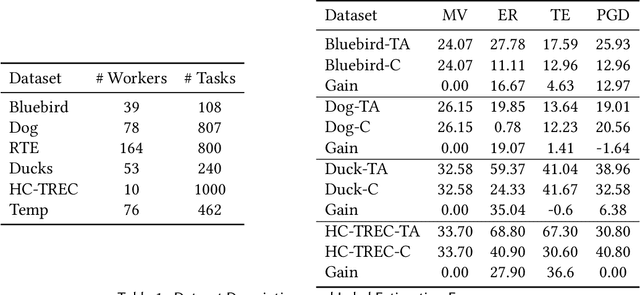
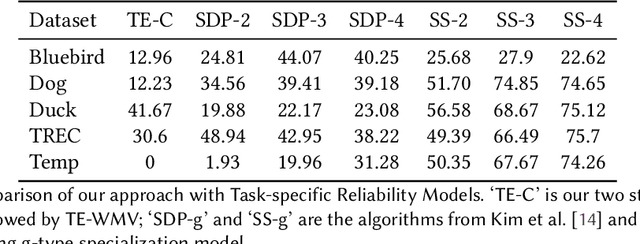
Crowdsourcing is a popular method used to estimate ground-truth labels by collecting noisy labels from workers. In this work, we are motivated by crowdsourcing applications where each worker can exhibit two levels of accuracy depending on a task's type. Applying algorithms designed for the traditional Dawid-Skene model to such a scenario results in performance which is limited by the hard tasks. Therefore, we first extend the model to allow worker accuracy to vary depending on a task's unknown type. Then we propose a spectral method to partition tasks by type. After separating tasks by type, any Dawid-Skene algorithm (i.e., any algorithm designed for the Dawid-Skene model) can be applied independently to each type to infer the truth values. We theoretically prove that when crowdsourced data contain tasks with varying levels of difficulty, our algorithm infers the true labels with higher accuracy than any Dawid-Skene algorithm. Experiments show that our method is effective in practical applications.