 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Cost-Sensitive Surrogate Losses via $\mathcal{H}$-calibration
Feb 26, 2025This paper aims to understand whether machine learning models should be trained using cost-sensitive surrogates or cost-agnostic ones (e.g., cross-entropy). Analyzing this question through the lens of $\mathcal{H}$-calibration, we find that cost-sensitive surrogates can strictly outperform their cost-agnostic counterparts when learning small models under common distributional assumptions. Since these distributional assumptions are hard to verify in practice, we also show that cost-sensitive surrogates consistently outperform cost-agnostic surrogates on classification datasets from the UCI repository. Together, these make a strong case for using cost-sensitive surrogates in practice.
Finite-Horizon Single-Pull Restless Bandits: An Efficient Index Policy For Scarce Resource Allocation
Jan 10, 2025Restless multi-armed bandits (RMABs) have been highly successful in optimizing sequential resource allocation across many domains. However, in many practical settings with highly scarce resources, where each agent can only receive at most one resource, such as healthcare intervention programs, the standard RMAB framework falls short. To tackle such scenarios, we introduce Finite-Horizon Single-Pull RMABs (SPRMABs), a novel variant in which each arm can only be pulled once. This single-pull constraint introduces additional complexity, rendering many existing RMAB solutions suboptimal or ineffective. %To address this, we propose using dummy states to duplicate the system, ensuring that once an arm is activated, it transitions exclusively within the dummy states. To address this shortcoming, we propose using \textit{dummy states} that expand the system and enforce the one-pull constraint. We then design a lightweight index policy for this expanded system. For the first time, we demonstrate that our index policy achieves a sub-linearly decaying average optimality gap of $\tilde{\mathcal{O}}\left(\frac{1}{\rho^{1/2}}\right)$ for a finite number of arms, where $\rho$ is the scaling factor for each arm cluster. Extensive simulations validate the proposed method, showing robust performance across various domains compared to existing benchmarks.
Efficient Public Health Intervention Planning Using Decomposition-Based Decision-Focused Learning
Mar 08, 2024



The declining participation of beneficiaries over time is a key concern in public health programs. A popular strategy for improving retention is to have health workers `intervene' on beneficiaries at risk of dropping out. However, the availability and time of these health workers are limited resources. As a result, there has been a line of research on optimizing these limited intervention resources using Restless Multi-Armed Bandits (RMABs). The key technical barrier to using this framework in practice lies in the need to estimate the beneficiaries' RMAB parameters from historical data. Recent research has shown that Decision-Focused Learning (DFL), which focuses on maximizing the beneficiaries' adherence rather than predictive accuracy, improves the performance of intervention targeting using RMABs. Unfortunately, these gains come at a high computational cost because of the need to solve and evaluate the RMAB in each DFL training step. In this paper, we provide a principled way to exploit the structure of RMABs to speed up intervention planning by cleverly decoupling the planning for different beneficiaries. We use real-world data from an Indian NGO, ARMMAN, to show that our approach is up to two orders of magnitude faster than the state-of-the-art approach while also yielding superior model performance. This would enable the NGO to scale up deployments using DFL to potentially millions of mothers, ultimately advancing progress toward UNSDG 3.1.
Evaluating the Effectiveness of Index-Based Treatment Allocation
Feb 19, 2024When resources are scarce, an allocation policy is needed to decide who receives a resource. This problem occurs, for instance, when allocating scarce medical resources and is often solved using modern ML methods. This paper introduces methods to evaluate index-based allocation policies -- that allocate a fixed number of resources to those who need them the most -- by using data from a randomized control trial. Such policies create dependencies between agents, which render the assumptions behind standard statistical tests invalid and limit the effectiveness of estimators. Addressing these challenges, we translate and extend recent ideas from the statistics literature to present an efficient estimator and methods for computing asymptotically correct confidence intervals. This enables us to effectively draw valid statistical conclusions, a critical gap in previous work. Our extensive experiments validate our methodology in practical settings, while also showcasing its statistical power. We conclude by proposing and empirically verifying extensions of our methodology that enable us to reevaluate a past randomized control trial to evaluate different ML allocation policies in the context of a mHealth program, drawing previously invisible conclusions.
Leaving the Nest: Going Beyond Local Loss Functions for Predict-Then-Optimize
May 26, 2023Predict-then-Optimize is a framework for using machine learning to perform decision-making under uncertainty. The central research question it asks is, "How can the structure of a decision-making task be used to tailor ML models for that specific task?" To this end, recent work has proposed learning task-specific loss functions that capture this underlying structure. However, current approaches make restrictive assumptions about the form of these losses and their impact on ML model behavior. These assumptions both lead to approaches with high computational cost, and when they are violated in practice, poor performance. In this paper, we propose solutions to these issues, avoiding the aforementioned assumptions and utilizing the ML model's features to increase the sample efficiency of learning loss functions. We empirically show that our method achieves state-of-the-art results in four domains from the literature, often requiring an order of magnitude fewer samples than comparable methods from past work. Moreover, our approach outperforms the best existing method by nearly 200% when the localness assumption is broken.
Learning (Local) Surrogate Loss Functions for Predict-Then-Optimize Problems
Mar 30, 2022
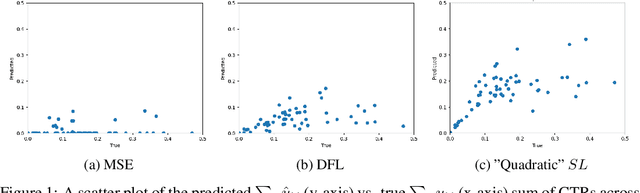
Decision-Focused Learning (DFL) is a paradigm for tailoring a predictive model to a downstream optimisation task that uses its predictions, so that it can perform better on that specific task. The main technical challenge associated with DFL is that it requires being able to differentiate through $argmin$ operations to work. However, these $argmin$ optimisations are often piecewise constant and, as a result, naively differentiating through them would provide uninformative gradients. Past work has largely focused on getting around this issue by handcrafting task-specific surrogates to the original optimisation problem that provide informative gradients when differentiated through. However, finding these surrogates can be challenging and the need to handcraft surrogates for each new task limits the usability of DFL. In addition, even after applying these relaxation techniques, there are no guarantees that the resulting surrogates are convex and, as a result, training a predictive model on them may lead to said model getting stuck in local minimas. In this paper, we provide an approach to learn faithful task-specific surrogates which (a) only requires access to a black-box oracle that can solve the optimisation problem and is thus generalizable, and (b) can be convex by construction and so can be easily optimized over. To the best of our knowledge, this is the first work on using learning to find good surrogates for DFL. We evaluate our approach on a budget allocation problem from the literature and find that our approach outperforms even the hand-crafted (non-convex) surrogate loss proposed by the original paper. Taking a step back, we hope that the generality and simplicity of our approach will help lower the barrier associated with implementing DFL-based solutions in practice. To that end, we are currently working on extending our experiments to more domains.
Decision-Focused Learning in Restless Multi-Armed Bandits with Application to Maternal and Child Care Domain
Feb 02, 2022
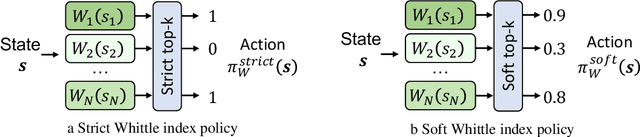

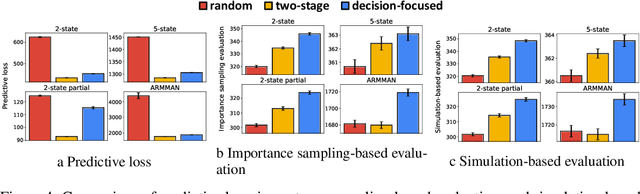
This paper studies restless multi-armed bandit (RMAB) problems with unknown arm transition dynamics but with known correlated arm features. The goal is to learn a model to predict transition dynamics given features, where the Whittle index policy solves the RMAB problems using predicted transitions. However, prior works often learn the model by maximizing the predictive accuracy instead of final RMAB solution quality, causing a mismatch between training and evaluation objectives. To address this shortcoming we propose a novel approach for decision-focused learning in RMAB that directly trains the predictive model to maximize the Whittle index solution quality. We present three key contributions: (i) we establish the differentiability of the Whittle index policy to support decision-focused learning; (ii) we significantly improve the scalability of previous decision-focused learning approaches in sequential problems; (iii) we apply our algorithm to the service call scheduling problem on a real-world maternal and child health domain. Our algorithm is the first for decision-focused learning in RMAB that scales to large-scale real-world problems. \end{abstract}
Data-Driven Methods for Balancing Fairness and Efficiency in Ride-Pooling
Oct 07, 2021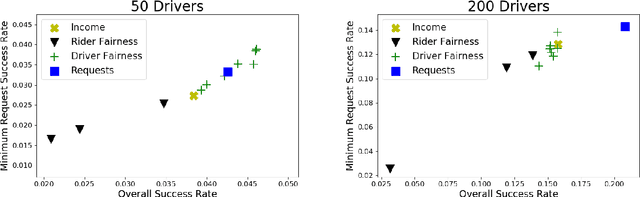
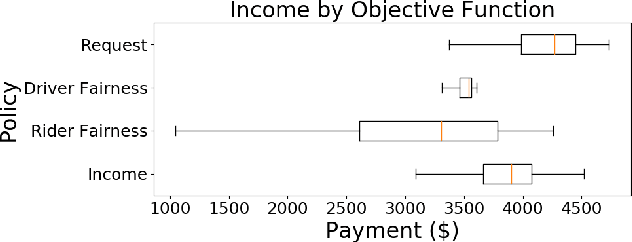
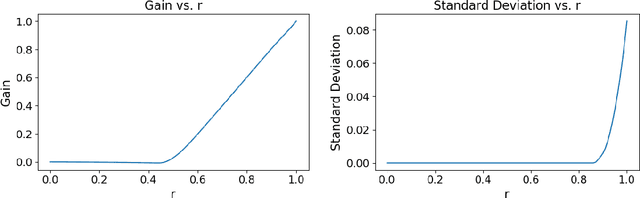
Rideshare and ride-pooling platforms use artificial intelligence-based matching algorithms to pair riders and drivers. However, these platforms can induce inequality either through an unequal income distribution or disparate treatment of riders. We investigate two methods to reduce forms of inequality in ride-pooling platforms: (1) incorporating fairness constraints into the objective function and (2) redistributing income to drivers to reduce income fluctuation and inequality. To evaluate our solutions, we use the New York City taxi data set. For the first method, we find that optimizing for driver-side fairness outperforms state-of-the-art models on the number of riders serviced, both in the worst-off neighborhood and overall, showing that optimizing for fairness can assist profitability in certain circumstances. For the second method, we explore income redistribution as a way to combat income inequality by having drivers keep an $r$ fraction of their income, and contributing the rest to a redistribution pool. For certain values of $r$, most drivers earn near their Shapley value, while still incentivizing drivers to maximize value, thereby avoiding the free-rider problem and reducing income variability. The first method can be extended to many definitions of fairness and the second method provably improves fairness without affecting profitability.
Q-Learning Lagrange Policies for Multi-Action Restless Bandits
Jun 22, 2021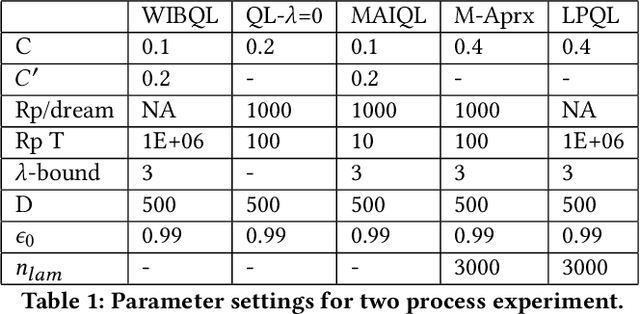
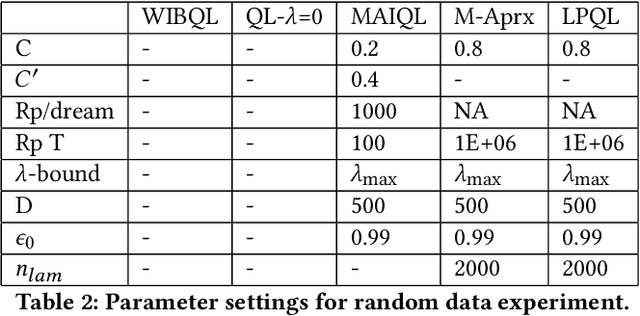
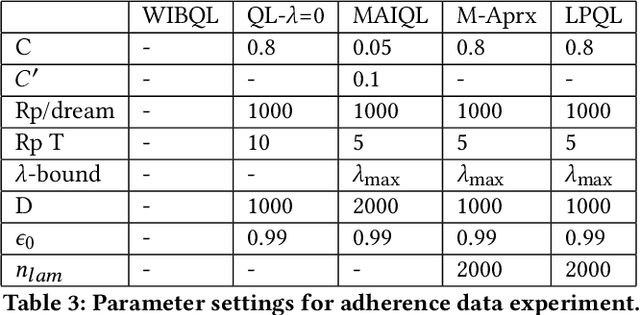
Multi-action restless multi-armed bandits (RMABs) are a powerful framework for constrained resource allocation in which $N$ independent processes are managed. However, previous work only study the offline setting where problem dynamics are known. We address this restrictive assumption, designing the first algorithms for learning good policies for Multi-action RMABs online using combinations of Lagrangian relaxation and Q-learning. Our first approach, MAIQL, extends a method for Q-learning the Whittle index in binary-action RMABs to the multi-action setting. We derive a generalized update rule and convergence proof and establish that, under standard assumptions, MAIQL converges to the asymptotically optimal multi-action RMAB policy as $t\rightarrow{}\infty$. However, MAIQL relies on learning Q-functions and indexes on two timescales which leads to slow convergence and requires problem structure to perform well. Thus, we design a second algorithm, LPQL, which learns the well-performing and more general Lagrange policy for multi-action RMABs by learning to minimize the Lagrange bound through a variant of Q-learning. To ensure fast convergence, we take an approximation strategy that enables learning on a single timescale, then give a guarantee relating the approximation's precision to an upper bound of LPQL's return as $t\rightarrow{}\infty$. Finally, we show that our approaches always outperform baselines across multiple settings, including one derived from real-world medication adherence data.
Learning MDPs from Features: Predict-Then-Optimize for Sequential Decision Problems by Reinforcement Learning
Jun 14, 2021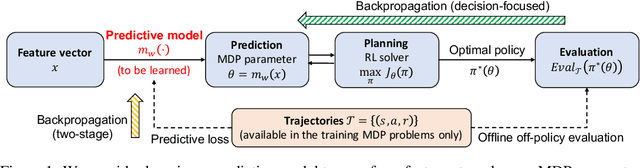
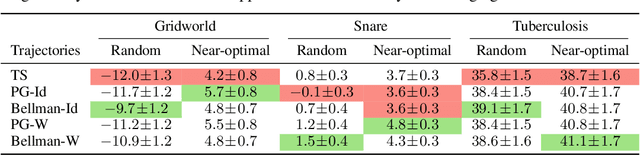
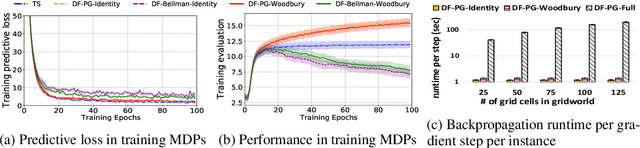
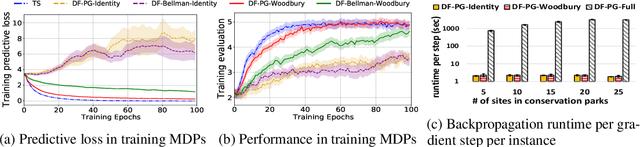
In the predict-then-optimize framework, the objective is to train a predictive model, mapping from environment features to parameters of an optimization problem, which maximizes decision quality when the optimization is subsequently solved. Recent work on decision-focused learning shows that embedding the optimization problem in the training pipeline can improve decision quality and help generalize better to unseen tasks compared to relying on an intermediate loss function for evaluating prediction quality. We study the predict-then-optimize framework in the context of sequential decision problems (formulated as MDPs) that are solved via reinforcement learning. In particular, we are given environment features and a set of trajectories from training MDPs, which we use to train a predictive model that generalizes to unseen test MDPs without trajectories. Two significant computational challenges arise in applying decision-focused learning to MDPs: (i) large state and action spaces make it infeasible for existing techniques to differentiate through MDP problems, and (ii) the high-dimensional policy space, as parameterized by a neural network, makes differentiating through a policy expensive. We resolve the first challenge by sampling provably unbiased derivatives to approximate and differentiate through optimality conditions, and the second challenge by using a low-rank approximation to the high-dimensional sample-based derivatives. We implement both Bellman--based and policy gradient--based decision-focused learning on three different MDP problems with missing parameters, and show that decision-focused learning performs better in generalization to unseen tasks.