 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-Learning Lagrange Policies for Multi-Action Restless Bandits
Paper and Code
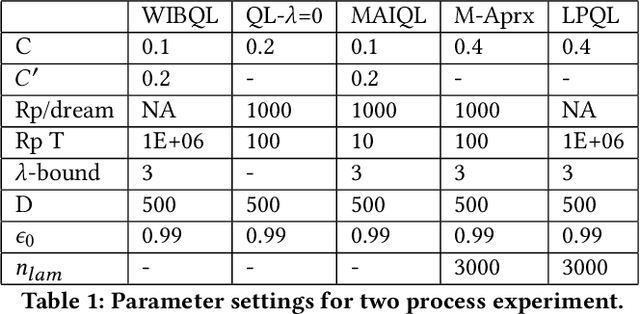
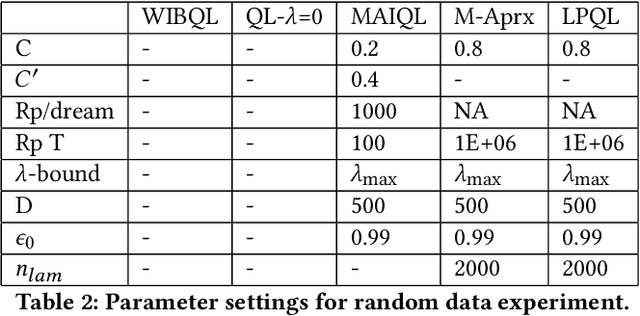
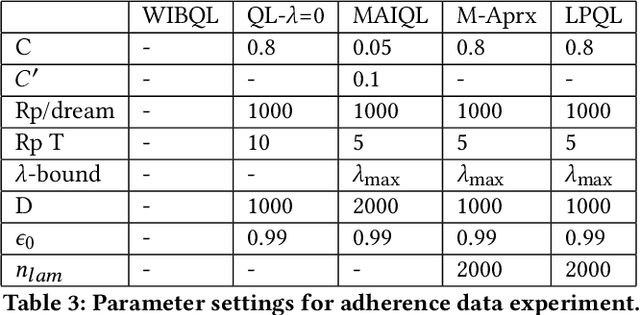
Multi-action restless multi-armed bandits (RMABs) are a powerful framework for constrained resource allocation in which $N$ independent processes are managed. However, previous work only study the offline setting where problem dynamics are known. We address this restrictive assumption, designing the first algorithms for learning good policies for Multi-action RMABs online using combinations of Lagrangian relaxation and Q-learning. Our first approach, MAIQL, extends a method for Q-learning the Whittle index in binary-action RMABs to the multi-action setting. We derive a generalized update rule and convergence proof and establish that, under standard assumptions, MAIQL converges to the asymptotically optimal multi-action RMAB policy as $t\rightarrow{}\infty$. However, MAIQL relies on learning Q-functions and indexes on two timescales which leads to slow convergence and requires problem structure to perform well. Thus, we design a second algorithm, LPQL, which learns the well-performing and more general Lagrange policy for multi-action RMABs by learning to minimize the Lagrange bound through a variant of Q-learning. To ensure fast convergence, we take an approximation strategy that enables learning on a single timescale, then give a guarantee relating the approximation's precision to an upper bound of LPQL's return as $t\rightarrow{}\infty$. Finally, we show that our approaches always outperform baselines across multiple settings, including one derived from real-world medication adherence data.