 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFind Rhinos without Finding Rhinos: Active Learning with Multimodal Imagery of South African Rhino Habitats
Sep 26, 2024


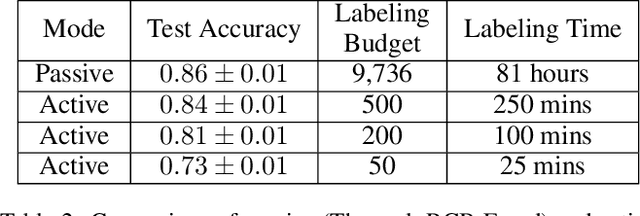
Much of Earth's charismatic megafauna is endangered by human activities, particularly the rhino, which is at risk of extinction due to the poaching crisis in Africa. Monitoring rhinos' movement is crucial to their protection but has unfortunately proven difficult because rhinos are elusive. Therefore, instead of tracking rhinos, we propose the novel approach of mapping communal defecation sites, called middens, which give information about rhinos' spatial behavior valuable to anti-poaching, management, and reintroduction efforts. This paper provides the first-ever mapping of rhino midden locations by building classifiers to detect them using remotely sensed thermal, RGB, and LiDAR imagery in passive and active learning settings. As existing active learning methods perform poorly due to the extreme class imbalance in our dataset, we design MultimodAL, an active learning system employing a ranking technique and multimodality to achieve competitive performance with passive learning models with 94% fewer labels. Our methods could therefore save over 76 hours in labeling time when used on a similarly-sized dataset. Unexpectedly, our midden map reveals that rhino middens are not randomly distributed throughout the landscape; rather, they are clustered. Consequently, rangers should be targeted at areas with high midden densities to strengthen anti-poaching efforts, in line with UN Target 15.7.
* 9 pages, 9 figures, IJCAI 2023 Special Track on AI for Good
Equitable Restless Multi-Armed Bandits: A General Framework Inspired By Digital Health
Aug 17, 2023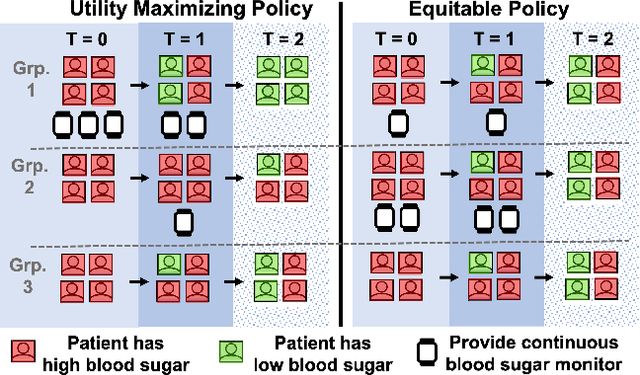
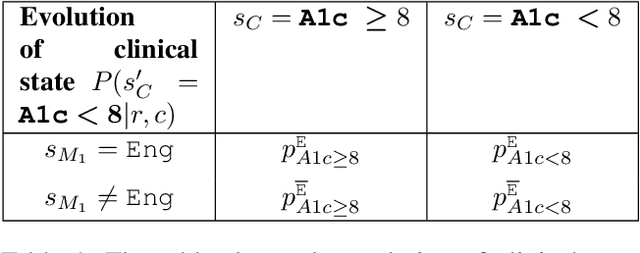
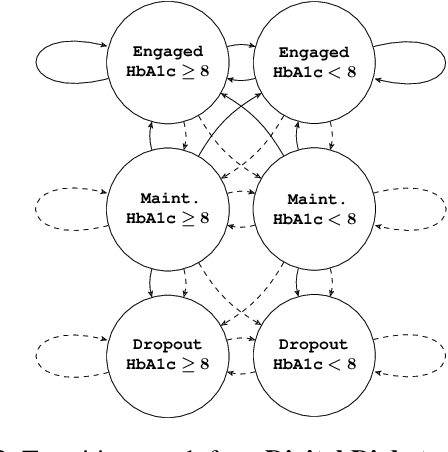
Restless multi-armed bandits (RMABs) are a popular framework for algorithmic decision making in sequential settings with limited resources. RMABs are increasingly being used for sensitive decisions such as in public health, treatment scheduling, anti-poaching, and -- the motivation for this work -- digital health. For such high stakes settings, decisions must both improve outcomes and prevent disparities between groups (e.g., ensure health equity). We study equitable objectives for RMABs (ERMABs) for the first time. We consider two equity-aligned objectives from the fairness literature, minimax reward and max Nash welfare. We develop efficient algorithms for solving each -- a water filling algorithm for the former, and a greedy algorithm with theoretically motivated nuance to balance disparate group sizes for the latter. Finally, we demonstrate across three simulation domains, including a new digital health model, that our approaches can be multiple times more equitable than the current state of the art without drastic sacrifices to utility. Our findings underscore our work's urgency as RMABs permeate into systems that impact human and wildlife outcomes. Code is available at https://github.com/google-research/socialgood/tree/equitable-rmab
Limited Resource Allocation in a Non-Markovian World: The Case of Maternal and Child Healthcare
May 22, 2023The success of many healthcare programs depends on participants' adherence. We consider the problem of scheduling interventions in low resource settings (e.g., placing timely support calls from health workers) to increase adherence and/or engagement. Past works have successfully developed several classes of Restless Multi-armed Bandit (RMAB) based solutions for this problem. Nevertheless, all past RMAB approaches assume that the participants' behaviour follows the Markov property. We demonstrate significant deviations from the Markov assumption on real-world data on a maternal health awareness program from our partner NGO, ARMMAN. Moreover, we extend RMABs to continuous state spaces, a previously understudied area. To tackle the generalised non-Markovian RMAB setting we (i) model each participant's trajectory as a time-series, (ii) leverage the power of time-series forecasting models to learn complex patterns and dynamics to predict future states, and (iii) propose the Time-series Arm Ranking Index (TARI) policy, a novel algorithm that selects the RMAB arms that will benefit the most from an intervention, given our future state predictions. We evaluate our approach on both synthetic data, and a secondary analysis on real data from ARMMAN, and demonstrate significant increase in engagement compared to the SOTA, deployed Whittle index solution. This translates to 16.3 hours of additional content listened, 90.8% more engagement drops prevented, and reaching more than twice as many high dropout-risk beneficiaries.
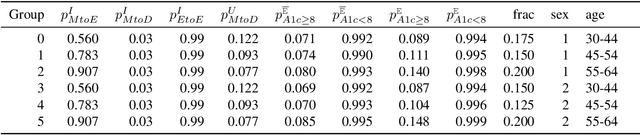
Fairness for Workers Who Pull the Arms: An Index Based Policy for Allocation of Restless Bandit Tasks
Mar 01, 2023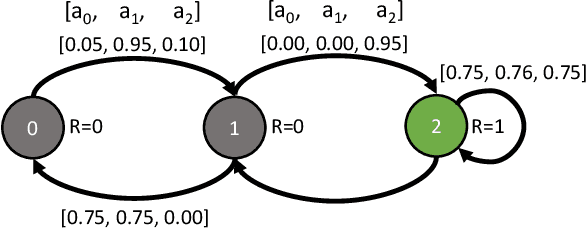
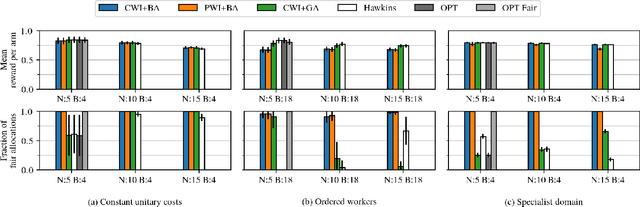
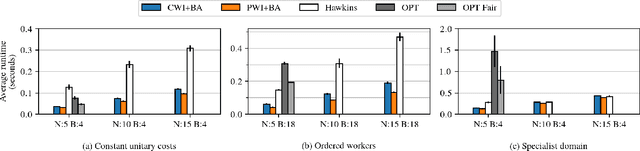
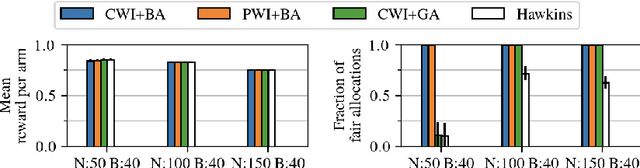
Motivated by applications such as machine repair, project monitoring, and anti-poaching patrol scheduling, we study intervention planning of stochastic processes under resource constraints. This planning problem has previously been modeled as restless multi-armed bandits (RMAB), where each arm is an intervention-dependent Markov Decision Process. However, the existing literature assumes all intervention resources belong to a single uniform pool, limiting their applicability to real-world settings where interventions are carried out by a set of workers, each with their own costs, budgets, and intervention effects. In this work, we consider a novel RMAB setting, called multi-worker restless bandits (MWRMAB) with heterogeneous workers. The goal is to plan an intervention schedule that maximizes the expected reward while satisfying budget constraints on each worker as well as fairness in terms of the load assigned to each worker. Our contributions are two-fold: (1) we provide a multi-worker extension of the Whittle index to tackle heterogeneous costs and per-worker budget and (2) we develop an index-based scheduling policy to achieve fairness. Further, we evaluate our method on various cost structures and show that our method significantly outperforms other baselines in terms of fairness without sacrificing much in reward accumulated.
Robust Restless Bandits: Tackling Interval Uncertainty with Deep Reinforcement Learning
Jul 04, 2021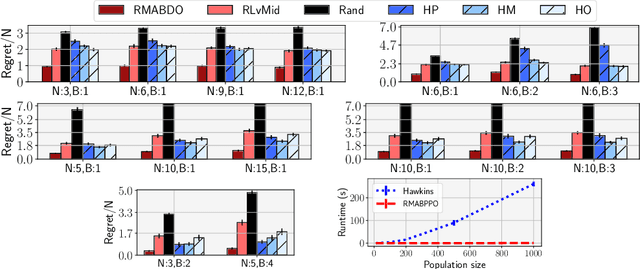
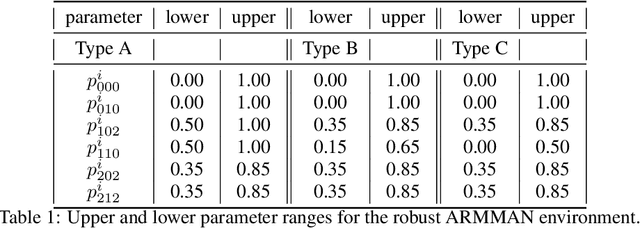
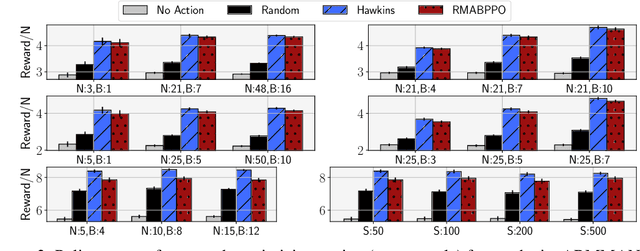

We introduce Robust Restless Bandits, a challenging generalization of restless multi-arm bandits (RMAB). RMABs have been widely studied for intervention planning with limited resources. However, most works make the unrealistic assumption that the transition dynamics are known perfectly, restricting the applicability of existing methods to real-world scenarios. To make RMABs more useful in settings with uncertain dynamics: (i) We introduce the Robust RMAB problem and develop solutions for a minimax regret objective when transitions are given by interval uncertainties; (ii) We develop a double oracle algorithm for solving Robust RMABs and demonstrate its effectiveness on three experimental domains; (iii) To enable our double oracle approach, we introduce RMABPPO, a novel deep reinforcement learning algorithm for solving RMABs. RMABPPO hinges on learning an auxiliary "$\lambda$-network" that allows each arm's learning to decouple, greatly reducing sample complexity required for training; (iv) Under minimax regret, the adversary in the double oracle approach is notoriously difficult to implement due to non-stationarity. To address this, we formulate the adversary oracle as a multi-agent reinforcement learning problem and solve it with a multi-agent extension of RMABPPO, which may be of independent interest as the first known algorithm for this setting. Code is available at https://github.com/killian-34/RobustRMAB.
Q-Learning Lagrange Policies for Multi-Action Restless Bandits
Jun 22, 2021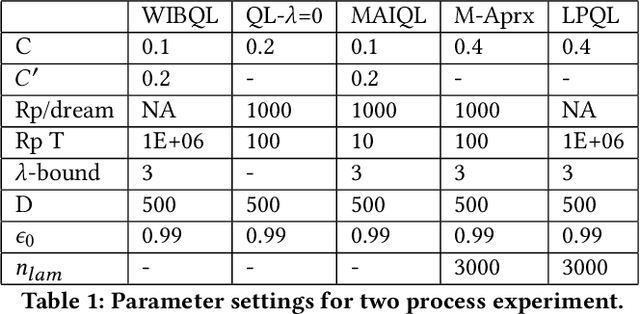
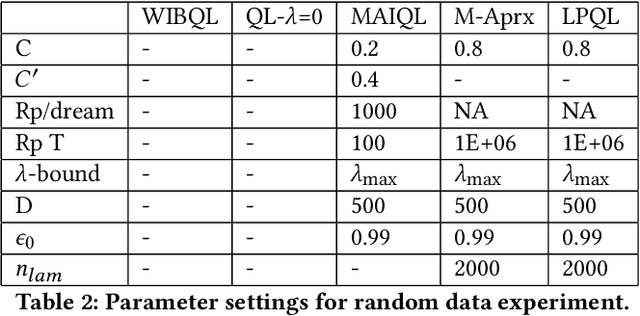
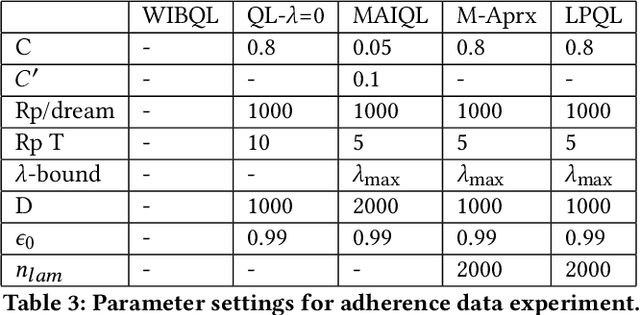
Multi-action restless multi-armed bandits (RMABs) are a powerful framework for constrained resource allocation in which $N$ independent processes are managed. However, previous work only study the offline setting where problem dynamics are known. We address this restrictive assumption, designing the first algorithms for learning good policies for Multi-action RMABs online using combinations of Lagrangian relaxation and Q-learning. Our first approach, MAIQL, extends a method for Q-learning the Whittle index in binary-action RMABs to the multi-action setting. We derive a generalized update rule and convergence proof and establish that, under standard assumptions, MAIQL converges to the asymptotically optimal multi-action RMAB policy as $t\rightarrow{}\infty$. However, MAIQL relies on learning Q-functions and indexes on two timescales which leads to slow convergence and requires problem structure to perform well. Thus, we design a second algorithm, LPQL, which learns the well-performing and more general Lagrange policy for multi-action RMABs by learning to minimize the Lagrange bound through a variant of Q-learning. To ensure fast convergence, we take an approximation strategy that enables learning on a single timescale, then give a guarantee relating the approximation's precision to an upper bound of LPQL's return as $t\rightarrow{}\infty$. Finally, we show that our approaches always outperform baselines across multiple settings, including one derived from real-world medication adherence data.
Envisioning Communities: A Participatory Approach Towards AI for Social Good
May 04, 2021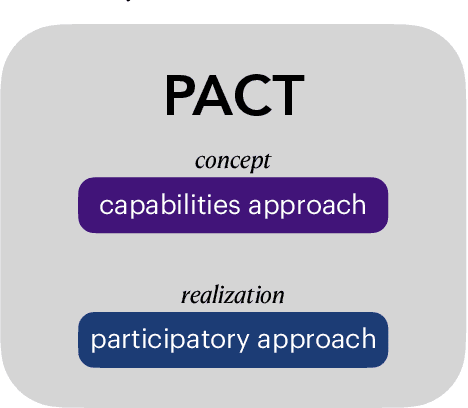
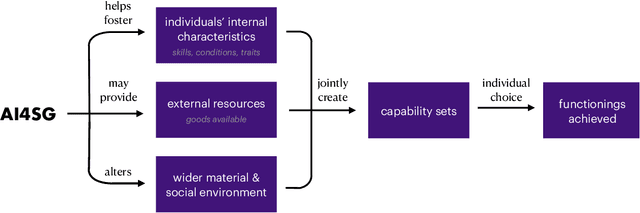
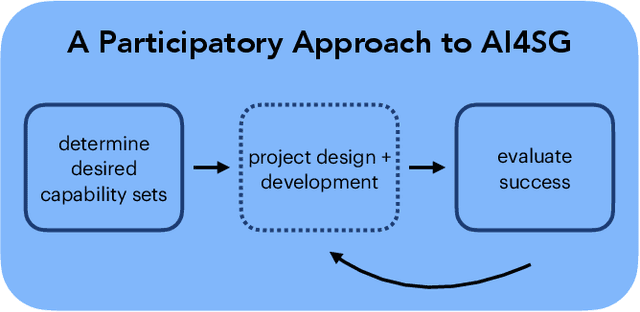
Research in artificial intelligence (AI) for social good presupposes some definition of social good, but potential definitions have been seldom suggested and never agreed upon. The normative question of what AI for social good research should be "for" is not thoughtfully elaborated, or is frequently addressed with a utilitarian outlook that prioritizes the needs of the majority over those who have been historically marginalized, brushing aside realities of injustice and inequity. We argue that AI for social good ought to be assessed by the communities that the AI system will impact, using as a guide the capabilities approach, a framework to measure the ability of different policies to improve human welfare equity. Furthermore, we lay out how AI research has the potential to catalyze social progress by expanding and equalizing capabilities. We show how the capabilities approach aligns with a participatory approach for the design and implementation of AI for social good research in a framework we introduce called PACT, in which community members affected should be brought in as partners and their input prioritized throughout the project. We conclude by providing an incomplete set of guiding questions for carrying out such participatory AI research in a way that elicits and respects a community's own definition of social good.
Collapsing Bandits and Their Application to Public Health Interventions
Jul 05, 2020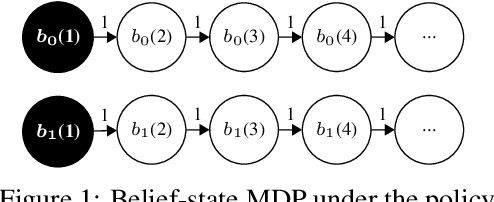
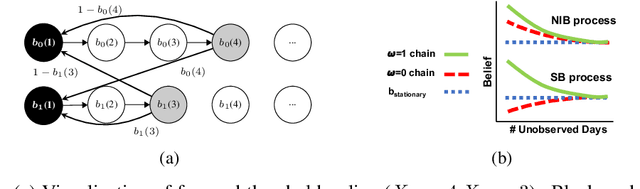
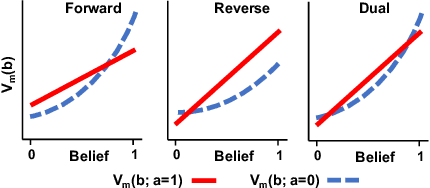
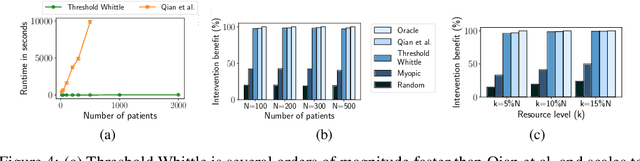
We propose and study Collpasing Bandits, a new restless multi-armed bandit (RMAB) setting in which each arm follows a binary-state Markovian process with a special structure: when an arm is played, the state is fully observed, thus "collapsing" any uncertainty, but when an arm is passive, no observation is made, thus allowing uncertainty to evolve. The goal is to keep as many arms in the "good" state as possible by planning a limited budget of actions per round. Such Collapsing Bandits are natural models for many healthcare domains in which workers must simultaneously monitor patients and deliver interventions in a way that maximizes the health of their patient cohort. Our main contributions are as follows: (i) Building on the Whittle index technique for RMABs, we derive conditions under which the Collapsing Bandits problem is indexable. Our derivation hinges on novel conditions that characterize when the optimal policies may take the form of either "forward" or "reverse" threshold policies. (ii) We exploit the optimality of threshold policies to build fast algorithms for computing the Whittle index, including a closed-form. (iii) We evaluate our algorithm on several data distributions including data from a real-world healthcare task in which a worker must monitor and deliver interventions to maximize their patients' adherence to tuberculosis medication. Our algorithm achieves a 3-order-of-magnitude speedup compared to state-of-the-art RMAB techniques while achieving similar performance.
Learning to Prescribe Interventions for Tuberculosis Patients using Digital Adherence Data
Feb 05, 2019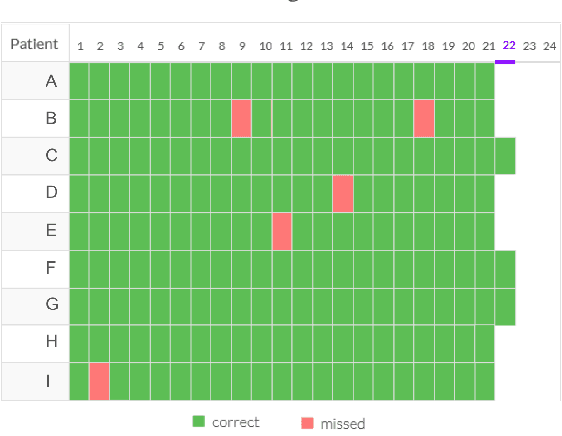
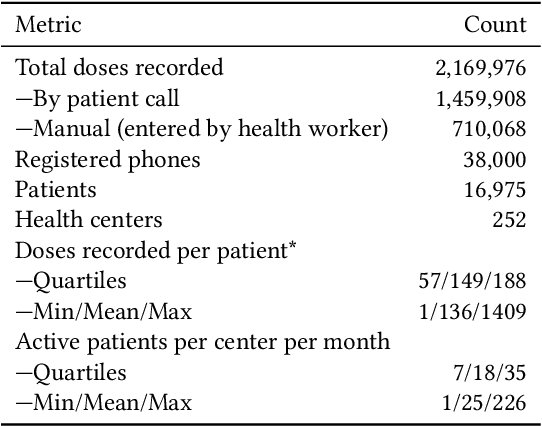
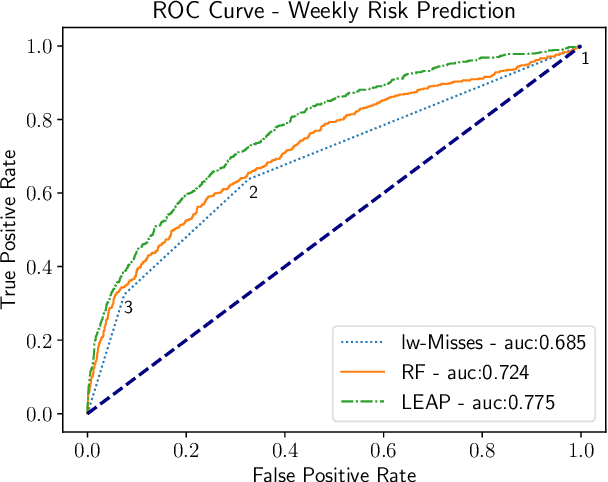

Digital Adherence Technologies (DATs) are an increasingly popular method for verifying patient adherence to many medications. We analyze data from one city served by 99DOTS, a phone-call-based DAT deployed for Tuberculosis (TB) treatment in India where nearly 3 million people are afflicted with the disease each year. The data contains nearly 17,000 patients and 2.1M phone calls. We lay the groundwork for learning from this real-world data, including a method for avoiding the effects of unobserved interventions in training data used for machine learning. We then construct a deep learning model, demonstrate its interpretability, and show how it can be adapted and trained in three different clinical scenarios to better target and improve patient care. In the real-time risk prediction setting our model could be used to proactively intervene with 21% more patients and before 76% more missed doses than current heuristic baselines. For outcome prediction, our model performs 40% better than baseline methods, allowing cities to target more resources to clinics with a heavier burden of patients at risk of failure. Finally, we present a case study demonstrating how our model can be trained in an end-to-end decision focused learning setting to achieve 15% better solution quality in an example decision problem faced by health workers.