 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Representations from Incomplete EHR Data with Dual-Masked Autoencoding
Feb 16, 2026Learning from electronic health records (EHRs) time series is challenging due to irregular sam- pling, heterogeneous missingness, and the resulting sparsity of observations. Prior self-supervised meth- ods either impute before learning, represent missingness through a dedicated input signal, or optimize solely for imputation, reducing their capacity to efficiently learn representations that support clinical downstream tasks. We propose the Augmented-Intrinsic Dual-Masked Autoencoder (AID-MAE), which learns directly from incomplete time series by applying an intrinsic missing mask to represent naturally missing values and an augmented mask that hides a subset of observed values for reconstruction during training. AID-MAE processes only the unmasked subset of tokens and consistently outperforms strong baselines, including XGBoost and DuETT, across multiple clinical tasks on two datasets. In addition, the learned embeddings naturally stratify patient cohorts in the representation space.
STEER: Inference-Time Risk Control via Constrained Quality-Diversity Search
Feb 02, 2026Large Language Models (LLMs) trained for average correctness often exhibit mode collapse, producing narrow decision behaviors on tasks where multiple responses may be reasonable. This limitation is particularly problematic in ordinal decision settings such as clinical triage, where standard alignment removes the ability to trade off specificity and sensitivity (the ROC operating point) based on contextual constraints. We propose STEER (Steerable Tuning via Evolutionary Ensemble Refinement), a training-free framework that reintroduces this tunable control. STEER constructs a population of natural-language personas through an offline, constrained quality-diversity search that promotes behavioral coverage while enforcing minimum safety, reasoning, and stability thresholds. At inference time, STEER exposes a single, interpretable control parameter that maps a user-specified risk percentile to a selected persona, yielding a monotonic adjustment of decision conservativeness. On two clinical triage benchmarks, STEER achieves broader behavioral coverage compared to temperature-based sampling and static persona ensembles. Compared to a representative post-training method, STEER maintains substantially higher accuracy on unambiguous urgent cases while providing comparable control over ambiguous decisions. These results demonstrate STEER as a safety-preserving paradigm for risk control, capable of steering behavior without compromising domain competence.
AI Agents for Conversational Patient Triage: Preliminary Simulation-Based Evaluation with Real-World EHR Data
Jun 04, 2025



Background: We present a Patient Simulator that leverages real world patient encounters which cover a broad range of conditions and symptoms to provide synthetic test subjects for development and testing of healthcare agentic models. The simulator provides a realistic approach to patient presentation and multi-turn conversation with a symptom-checking agent. Objectives: (1) To construct and instantiate a Patient Simulator to train and test an AI health agent, based on patient vignettes derived from real EHR data. (2) To test the validity and alignment of the simulated encounters provided by the Patient Simulator to expert human clinical providers. (3) To illustrate the evaluation framework of such an LLM system on the generated realistic, data-driven simulations -- yielding a preliminary assessment of our proposed system. Methods: We first constructed realistic clinical scenarios by deriving patient vignettes from real-world EHR encounters. These vignettes cover a variety of presenting symptoms and underlying conditions. We then evaluate the performance of the Patient Simulator as a simulacrum of a real patient encounter across over 500 different patient vignettes. We leveraged a separate AI agent to provide multi-turn questions to obtain a history of present illness. The resulting multiturn conversations were evaluated by two expert clinicians. Results: Clinicians scored the Patient Simulator as consistent with the patient vignettes in those same 97.7% of cases. The extracted case summary based on the conversation history was 99% relevant. Conclusions: We developed a methodology to incorporate vignettes derived from real healthcare patient data to build a simulation of patient responses to symptom checking agents. The performance and alignment of this Patient Simulator could be used to train and test a multi-turn conversational AI agent at scale.
Sleepless Nights, Sugary Days: Creating Synthetic Users with Health Conditions for Realistic Coaching Agent Interactions
Feb 18, 2025We present an end-to-end framework for generating synthetic users for evaluating interactive agents designed to encourage positive behavior changes, such as in health and lifestyle coaching. The synthetic users are grounded in health and lifestyle conditions, specifically sleep and diabetes management in this study, to ensure realistic interactions with the health coaching agent. Synthetic users are created in two stages: first, structured data are generated grounded in real-world health and lifestyle factors in addition to basic demographics and behavioral attributes; second, full profiles of the synthetic users are developed conditioned on the structured data. Interactions between synthetic users and the coaching agent are simulated using generative agent-based models such as Concordia, or directly by prompting a language model. Using two independently-developed agents for sleep and diabetes coaching as case studies, the validity of this framework is demonstrated by analyzing the coaching agent's understanding of the synthetic users' needs and challenges. Finally, through multiple blinded evaluations of user-coach interactions by human experts, we demonstrate that our synthetic users with health and behavioral attributes more accurately portray real human users with the same attributes, compared to generic synthetic users not grounded in such attributes. The proposed framework lays the foundation for efficient development of conversational agents through extensive, realistic, and grounded simulated interactions.
Foundation Model of Electronic Medical Records for Adaptive Risk Estimation
Feb 10, 2025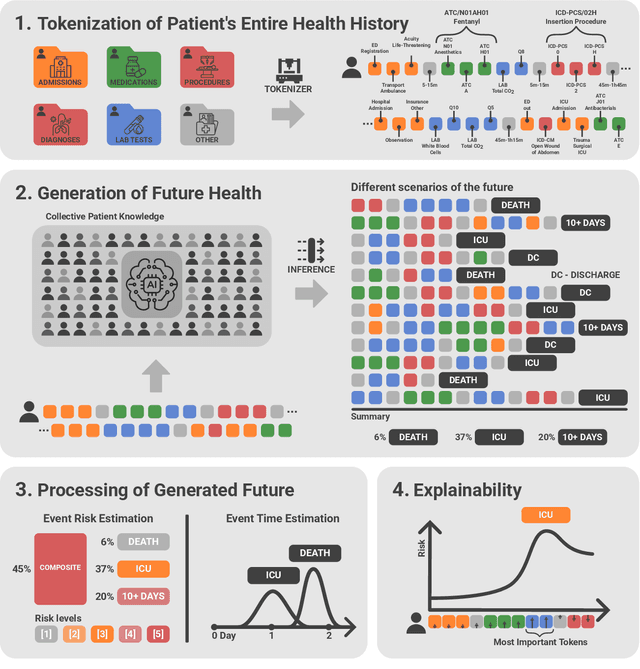
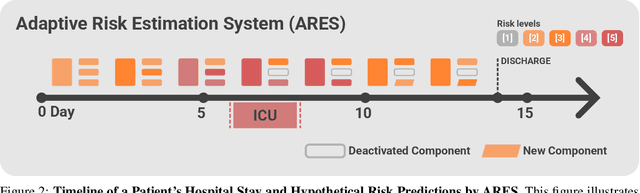
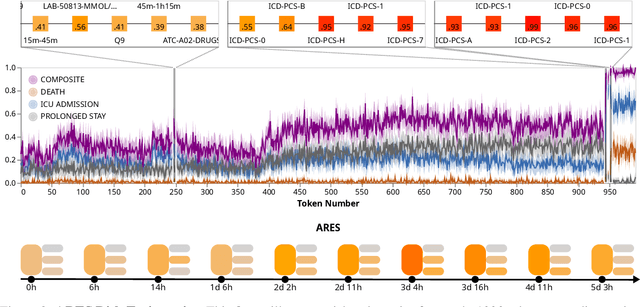
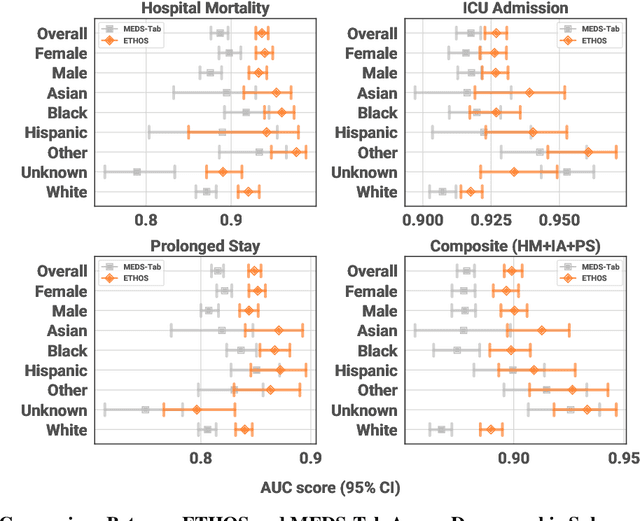
We developed the Enhanced Transformer for Health Outcome Simulation (ETHOS), an AI model that tokenizes patient health timelines (PHTs) from EHRs. ETHOS predicts future PHTs using transformer-based architectures. The Adaptive Risk Estimation System (ARES) employs ETHOS to compute dynamic and personalized risk probabilities for clinician-defined critical events. ARES incorporates a personalized explainability module that identifies key clinical factors influencing risk estimates for individual patients. ARES was evaluated on the MIMIC-IV v2.2 dataset in emergency department (ED) settings, benchmarking its performance against traditional early warning systems and machine learning models. We processed 299,721 unique patients from MIMIC-IV into 285,622 PHTs, with 60% including hospital admissions. The dataset contained over 357 million tokens. ETHOS outperformed benchmark models in predicting hospital admissions, ICU admissions, and prolonged hospital stays, achieving superior AUC scores. ETHOS-based risk estimates demonstrated robustness across demographic subgroups with strong model reliability, confirmed via calibration curves. The personalized explainability module provides insights into patient-specific factors contributing to risk. ARES, powered by ETHOS, advances predictive healthcare AI by providing dynamic, real-time, and personalized risk estimation with patient-specific explainability to enhance clinician trust. Its adaptability and superior accuracy position it as a transformative tool for clinical decision-making, potentially improving patient outcomes and resource allocation in emergency and inpatient settings. We release the full code at github.com/ipolharvard/ethos-ares to facilitate future research.
Representation Learning of Lab Values via Masked AutoEncoder
Jan 05, 2025



Accurate imputation of missing laboratory values in electronic health records (EHRs) is critical to enable robust clinical predictions and reduce biases in AI systems in healthcare. Existing methods, such as variational autoencoders (VAEs) and decision tree-based approaches such as XGBoost, struggle to model the complex temporal and contextual dependencies in EHR data, mainly in underrepresented groups. In this work, we propose Lab-MAE, a novel transformer-based masked autoencoder framework that leverages self-supervised learning for the imputation of continuous sequential lab values. Lab-MAE introduces a structured encoding scheme that jointly models laboratory test values and their corresponding timestamps, enabling explicit capturing temporal dependencies. Empirical evaluation on the MIMIC-IV dataset demonstrates that Lab-MAE significantly outperforms the state-of-the-art baselines such as XGBoost across multiple metrics, including root mean square error (RMSE), R-squared (R2), and Wasserstein distance (WD). Notably, Lab-MAE achieves equitable performance across demographic groups of patients, advancing fairness in clinical predictions. We further investigate the role of follow-up laboratory values as potential shortcut features, revealing Lab-MAE's robustness in scenarios where such data is unavailable. The findings suggest that our transformer-based architecture, adapted to the characteristics of the EHR data, offers a foundation model for more accurate and fair clinical imputation models. In addition, we measure and compare the carbon footprint of Lab-MAE with the baseline XGBoost model, highlighting its environmental requirements.
From Barriers to Tactics: A Behavioral Science-Informed Agentic Workflow for Personalized Nutrition Coaching
Oct 17, 2024



Effective management of cardiometabolic conditions requires sustained positive nutrition habits, often hindered by complex and individualized barriers. Direct human management is simply not scalable, while previous attempts aimed at automating nutrition coaching lack the personalization needed to address these diverse challenges. This paper introduces a novel LLM-powered agentic workflow designed to provide personalized nutrition coaching by directly targeting and mitigating patient-specific barriers. Grounded in behavioral science principles, the workflow leverages a comprehensive mapping of nutrition-related barriers to corresponding evidence-based strategies. A specialized LLM agent intentionally probes for and identifies the root cause of a patient's dietary struggles. Subsequently, a separate LLM agent delivers tailored tactics designed to overcome those specific barriers with patient context. We designed and validated our approach through a user study with individuals with cardiometabolic conditions, demonstrating the system's ability to accurately identify barriers and provide personalized guidance. Furthermore, we conducted a large-scale simulation study, grounding on real patient vignettes and expert-validated metrics, to evaluate the system's performance across a wide range of scenarios. Our findings demonstrate the potential of this LLM-powered agentic workflow to improve nutrition coaching by providing personalized, scalable, and behaviorally-informed interventions.
Zero Shot Health Trajectory Prediction Using Transformer
Jul 30, 2024Integrating modern machine learning and clinical decision-making has great promise for mitigating healthcare's increasing cost and complexity. We introduce the Enhanced Transformer for Health Outcome Simulation (ETHOS), a novel application of the transformer deep-learning architecture for analyzing high-dimensional, heterogeneous, and episodic health data. ETHOS is trained using Patient Health Timelines (PHTs)-detailed, tokenized records of health events-to predict future health trajectories, leveraging a zero-shot learning approach. ETHOS represents a significant advancement in foundation model development for healthcare analytics, eliminating the need for labeled data and model fine-tuning. Its ability to simulate various treatment pathways and consider patient-specific factors positions ETHOS as a tool for care optimization and addressing biases in healthcare delivery. Future developments will expand ETHOS' capabilities to incorporate a wider range of data types and data sources. Our work demonstrates a pathway toward accelerated AI development and deployment in healthcare.
The Geometry of Queries: Query-Based Innovations in Retrieval-Augmented Generation
Jul 25, 2024Digital health chatbots powered by Large Language Models (LLMs) have the potential to significantly improve personal health management for chronic conditions by providing accessible and on-demand health coaching and question-answering. However, these chatbots risk providing unverified and inaccurate information because LLMs generate responses based on patterns learned from diverse internet data. Retrieval Augmented Generation (RAG) can help mitigate hallucinations and inaccuracies in LLM responses by grounding it on reliable content. However, efficiently and accurately retrieving most relevant set of content for real-time user questions remains a challenge. In this work, we introduce Query-Based Retrieval Augmented Generation (QB-RAG), a novel approach that pre-computes a database of potential queries from a content base using LLMs. For an incoming patient question, QB-RAG efficiently matches it against this pre-generated query database using vector search, improving alignment between user questions and the content. We establish a theoretical foundation for QB-RAG and provide a comparative analysis of existing retrieval enhancement techniques for RAG systems. Finally, our empirical evaluation demonstrates that QB-RAG significantly improves the accuracy of healthcare question answering, paving the way for robust and trustworthy LLM applications in digital health.
Selective Fine-tuning on LLM-labeled Data May Reduce Reliance on Human Annotation: A Case Study Using Schedule-of-Event Table Detection
May 09, 2024



Large Language Models (LLMs) have demonstrated their efficacy across a broad spectrum of tasks in healthcare applications. However, often LLMs need to be fine-tuned on task-specific expert annotated data to achieve optimal performance, which can be expensive and time consuming. In this study, we fine-tune PaLM-2 with parameter efficient fine-tuning (PEFT) using noisy labels obtained from gemini-pro 1.0 for the detection of Schedule-of-Event (SoE) tables, which specify care plan in clinical trial protocols. We introduce a filtering mechanism to select high-confidence labels for this table classification task, thereby reducing the noise in the auto-generated labels. We show that fine-tuned PaLM-2 with those labels achieves performance that exceeds the gemini-pro 1.0 and other LLMs. Furthermore, its performance is close to a PaLM-2 fine-tuned on labels obtained from non-expert annotators. Our results show that leveraging LLM-generated labels through powerful models like gemini-pro can potentially serve as a viable strategy for improving LLM performance through fine-tuning in specialized tasks, particularly in domains where expert annotations are scarce, expensive, or time-consuming to obtain.