 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeenhancing reasoning accuracy in large language models during inference time
Mar 22, 2026Large Language Models (LLMs) often exhibit strong linguistic abilities while remaining unreliable on multi-step reasoning tasks, particularly when deployed without additional training or fine-tuning. In this work, we study inference-time techniques to improve the reasoning accuracy of LLMs. We systematically evaluate three classes of inference-time strategies: (i) self-consistency via stochastic decoding, where the model is sampled multiple times using controlled temperature and nucleus sampling and the most frequent final answer is selected; (ii) dual-model reasoning agreement, where outputs from two independent models are compared and only consistent reasoning traces are trusted; and (iii) self-reflection, where the model critiques and revises its own reasoning. Across all evaluated methods, we employ Chain-of-Thought (CoT) [1] prompting to elicit explicit intermediate reasoning steps before generating final answers. In this work, we provide a controlled comparative evaluation across three inference-time strategies under identical prompting and verification settings. Our experiments on LLM [2] show that self-consistency with nucleus sampling and controlled temperature value yields the substantial gains, achieving a 9% to 15% absolute improvement in accuracy over greedy single-pass decoding, well-suited for low-risk domains, offering meaningful gains with minimal overhead. The dual-model approach provides additional confirmation for model reasoning steps thus more appropriate for moderate-risk domains, where higher reliability justifies additional compute. Self-reflection offers only marginal improvements, suggesting limited effectiveness for smaller non-reasoning models at inference time.
Reasoning-Guided Claim Normalization for Noisy Multilingual Social Media Posts
Nov 07, 2025We address claim normalization for multilingual misinformation detection - transforming noisy social media posts into clear, verifiable statements across 20 languages. The key contribution demonstrates how systematic decomposition of posts using Who, What, Where, When, Why and How questions enables robust cross-lingual transfer despite training exclusively on English data. Our methodology incorporates finetuning Qwen3-14B using LoRA with the provided dataset after intra-post deduplication, token-level recall filtering for semantic alignment and retrieval-augmented few-shot learning with contextual examples during inference. Our system achieves METEOR scores ranging from 41.16 (English) to 15.21 (Marathi), securing third rank on the English leaderboard and fourth rank for Dutch and Punjabi. The approach shows 41.3% relative improvement in METEOR over baseline configurations and substantial gains over existing methods. Results demonstrate effective cross-lingual generalization for Romance and Germanic languages while maintaining semantic coherence across diverse linguistic structures.
Equitable Restless Multi-Armed Bandits: A General Framework Inspired By Digital Health
Aug 17, 2023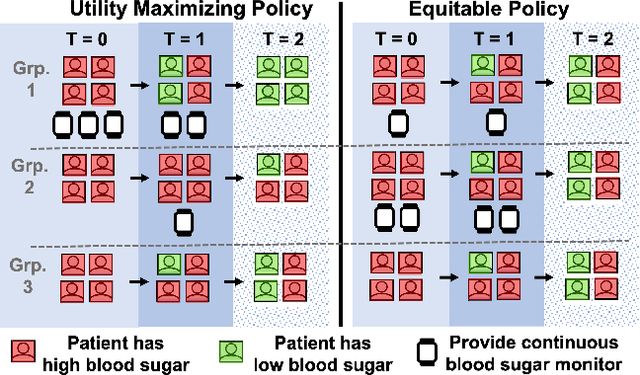
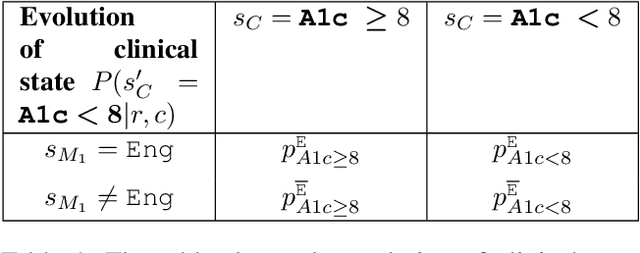
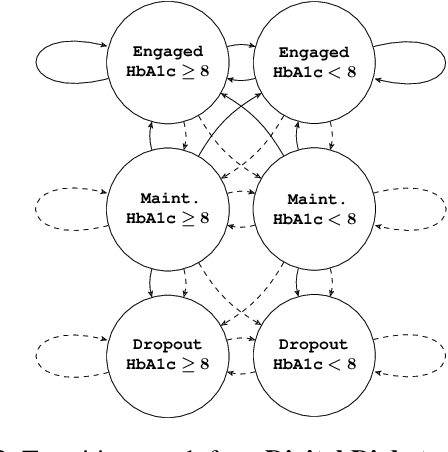
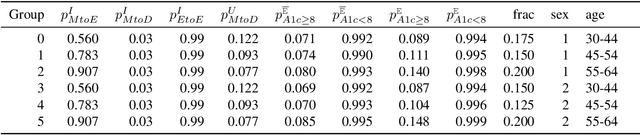
Restless multi-armed bandits (RMABs) are a popular framework for algorithmic decision making in sequential settings with limited resources. RMABs are increasingly being used for sensitive decisions such as in public health, treatment scheduling, anti-poaching, and -- the motivation for this work -- digital health. For such high stakes settings, decisions must both improve outcomes and prevent disparities between groups (e.g., ensure health equity). We study equitable objectives for RMABs (ERMABs) for the first time. We consider two equity-aligned objectives from the fairness literature, minimax reward and max Nash welfare. We develop efficient algorithms for solving each -- a water filling algorithm for the former, and a greedy algorithm with theoretically motivated nuance to balance disparate group sizes for the latter. Finally, we demonstrate across three simulation domains, including a new digital health model, that our approaches can be multiple times more equitable than the current state of the art without drastic sacrifices to utility. Our findings underscore our work's urgency as RMABs permeate into systems that impact human and wildlife outcomes. Code is available at https://github.com/google-research/socialgood/tree/equitable-rmab
Indexability is Not Enough for Whittle: Improved, Near-Optimal Algorithms for Restless Bandits
Oct 31, 2022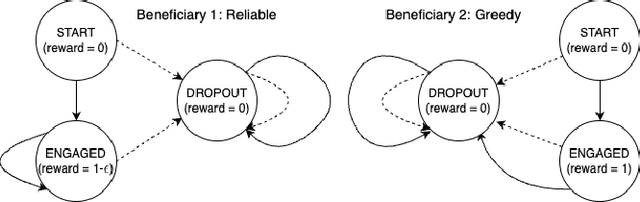


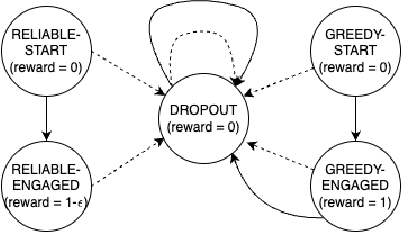
We study the problem of planning restless multi-armed bandits (RMABs) with multiple actions. This is a popular model for multi-agent systems with applications like multi-channel communication, monitoring and machine maintenance tasks, and healthcare. Whittle index policies, which are based on Lagrangian relaxations, are widely used in these settings due to their simplicity and near-optimality under certain conditions. In this work, we first show that Whittle index policies can fail in simple and practically relevant RMAB settings, \textit{even when} the RMABs are indexable. We discuss why the optimality guarantees fail and why asymptotic optimality may not translate well to practically relevant planning horizons. We then propose an alternate planning algorithm based on the mean-field method, which can provably and efficiently obtain near-optimal policies with a large number of arms, without the stringent structural assumptions required by the Whittle index policies. This borrows ideas from existing research with some improvements: our approach is hyper-parameter free, and we provide an improved non-asymptotic analysis which has: (a) no requirement for exogenous hyper-parameters and tighter polynomial dependence on known problem parameters; (b) high probability bounds which show that the reward of the policy is reliable; and (c) matching sub-optimality lower bounds for this algorithm with respect to the number of arms, thus demonstrating the tightness of our bounds. Our extensive experimental analysis shows that the mean-field approach matches or outperforms other baselines.
Using AntiPatterns to avoid MLOps Mistakes
Jun 30, 2021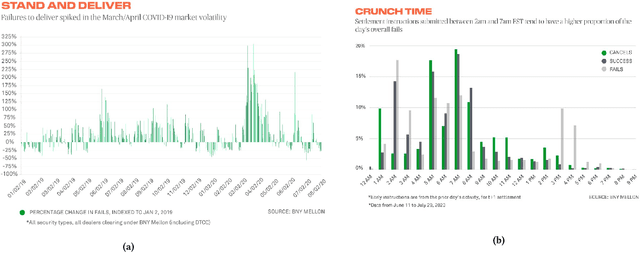
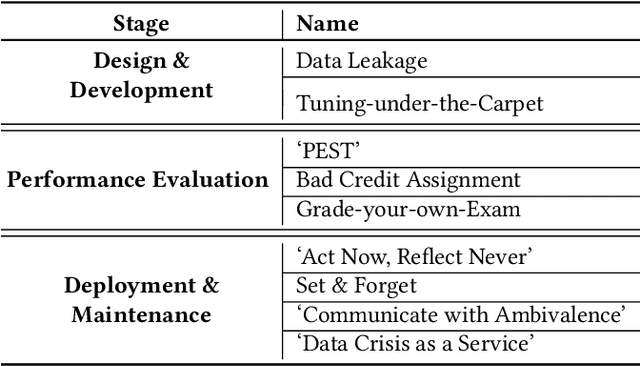
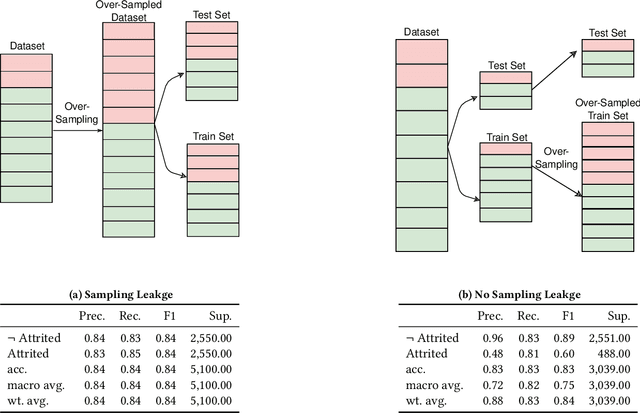
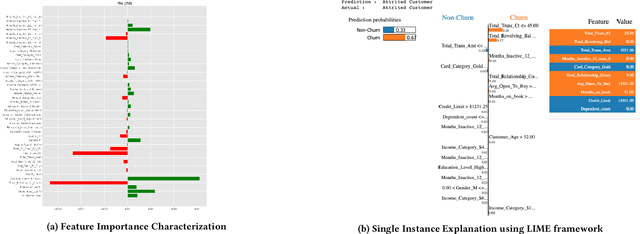
We describe lessons learned from developing and deploying machine learning models at scale across the enterprise in a range of financial analytics applications. These lessons are presented in the form of antipatterns. Just as design patterns codify best software engineering practices, antipatterns provide a vocabulary to describe defective practices and methodologies. Here we catalog and document numerous antipatterns in financial ML operations (MLOps). Some antipatterns are due to technical errors, while others are due to not having sufficient knowledge of the surrounding context in which ML results are used. By providing a common vocabulary to discuss these situations, our intent is that antipatterns will support better documentation of issues, rapid communication between stakeholders, and faster resolution of problems. In addition to cataloging antipatterns, we describe solutions, best practices, and future directions toward MLOps maturity.