 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward collision-free trajectory for autonomous and pilot-controlled unmanned aerial vehicles
Sep 18, 2023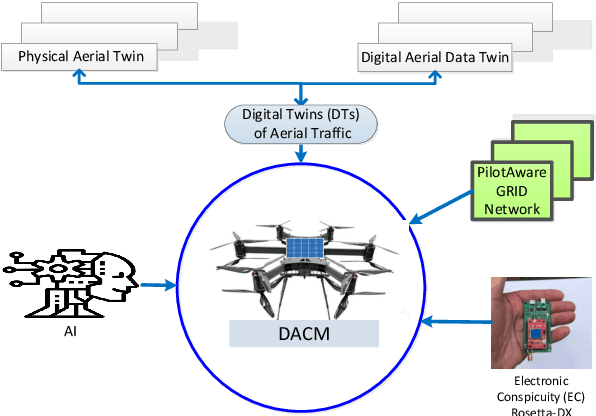



For drones, as safety-critical systems, there is an increasing need for onboard detect & avoid (DAA) technology i) to see, sense or detect conflicting traffic or imminent non-cooperative threats due to their high mobility with multiple degrees of freedom and the complexity of deployed unstructured environments, and subsequently ii) to take the appropriate actions to avoid collisions depending upon the level of autonomy. The safe and efficient integration of UAV traffic management (UTM) systems with air traffic management (ATM) systems, using intelligent autonomous approaches, is an emerging requirement where the number of diverse UAV applications is increasing on a large scale in dense air traffic environments for completing swarms of multiple complex missions flexibly and simultaneously. Significant progress over the past few years has been made in detecting UAVs present in aerospace, identifying them, and determining their existing flight path. This study makes greater use of electronic conspicuity (EC) information made available by PilotAware Ltd in developing an advanced collision management methodology -- Drone Aware Collision Management (DACM) -- capable of determining and executing a variety of time-optimal evasive collision avoidance (CA) manoeuvres using a reactive geometric conflict detection and resolution (CDR) technique. The merits of the DACM methodology have been demonstrated through extensive simulations and real-world field tests in avoiding mid-air collisions (MAC) between UAVs and manned aeroplanes. The results show that the proposed methodology can be employed successfully in avoiding collisions while limiting the deviation from the original trajectory in highly dynamic aerospace without requiring sophisticated sensors and prior training.
Causal Estimation of User Learning in Personalized Systems
Jun 01, 2023



In online platforms, the impact of a treatment on an observed outcome may change over time as 1) users learn about the intervention, and 2) the system personalization, such as individualized recommendations, change over time. We introduce a non-parametric causal model of user actions in a personalized system. We show that the Cookie-Cookie-Day (CCD) experiment, designed for the measurement of the user learning effect, is biased when there is personalization. We derive new experimental designs that intervene in the personalization system to generate the variation necessary to separately identify the causal effect mediated through user learning and personalization. Making parametric assumptions allows for the estimation of long-term causal effects based on medium-term experiments. In simulations, we show that our new designs successfully recover the dynamic causal effects of interest.
A lightweight Transformer-based model for fish landmark detection
Sep 13, 2022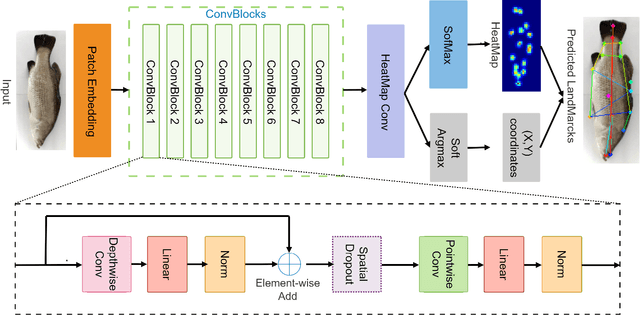
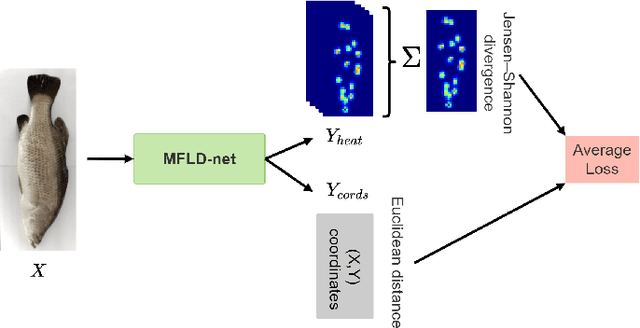


Transformer-based models, such as the Vision Transformer (ViT), can outperform onvolutional Neural Networks (CNNs) in some vision tasks when there is sufficient training data. However, (CNNs) have a strong and useful inductive bias for vision tasks (i.e. translation equivariance and locality). In this work, we developed a novel model architecture that we call a Mobile fish landmark detection network (MFLD-net). We have made this model using convolution operations based on ViT (i.e. Patch embeddings, Multi-Layer Perceptrons). MFLD-net can achieve competitive or better results in low data regimes while being lightweight and therefore suitable for embedded and mobile devices. Furthermore, we show that MFLD-net can achieve keypoint (landmark) estimation accuracies on-par or even better than some of the state-of-the-art (CNNs) on a fish image dataset. Additionally, unlike ViT, MFLD-net does not need a pre-trained model and can generalise well when trained on a small dataset. We provide quantitative and qualitative results that demonstrate the model's generalisation capabilities. This work will provide a foundation for future efforts in developing mobile, but efficient fish monitoring systems and devices.
Using AntiPatterns to avoid MLOps Mistakes
Jun 30, 2021
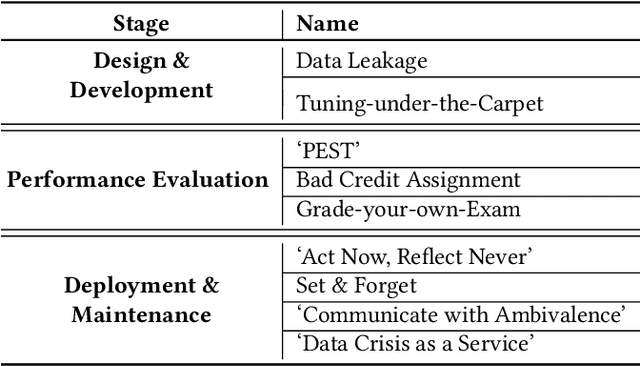
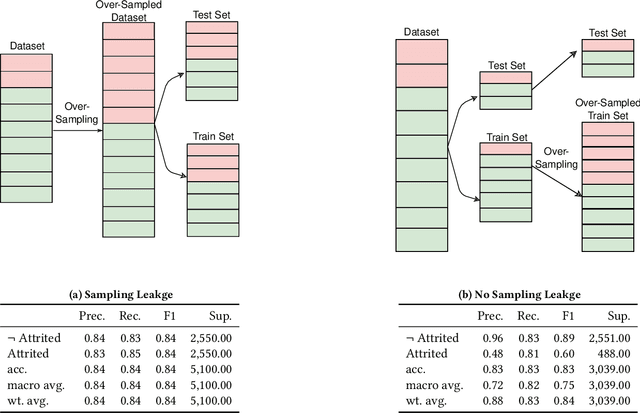
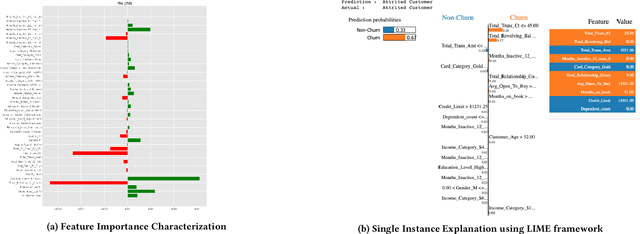
We describe lessons learned from developing and deploying machine learning models at scale across the enterprise in a range of financial analytics applications. These lessons are presented in the form of antipatterns. Just as design patterns codify best software engineering practices, antipatterns provide a vocabulary to describe defective practices and methodologies. Here we catalog and document numerous antipatterns in financial ML operations (MLOps). Some antipatterns are due to technical errors, while others are due to not having sufficient knowledge of the surrounding context in which ML results are used. By providing a common vocabulary to discuss these situations, our intent is that antipatterns will support better documentation of issues, rapid communication between stakeholders, and faster resolution of problems. In addition to cataloging antipatterns, we describe solutions, best practices, and future directions toward MLOps maturity.
Distinguishing artefacts: evaluating the saturation point of convolutional neural networks
May 21, 2021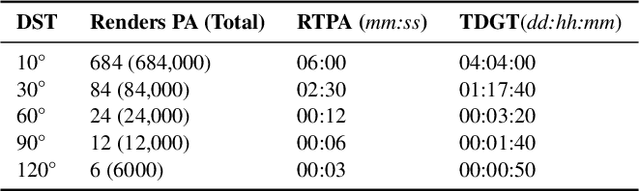
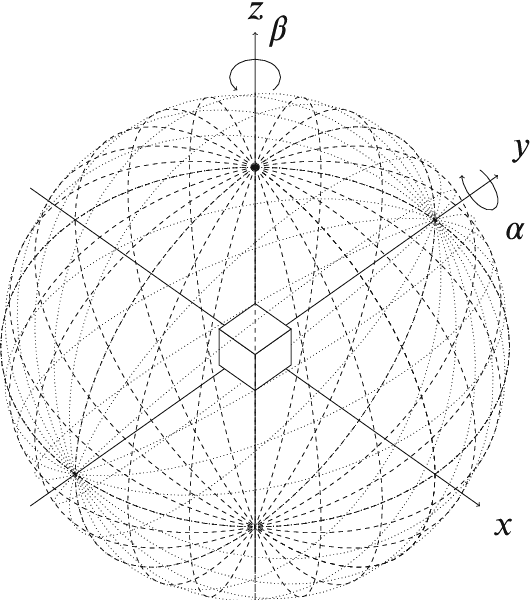
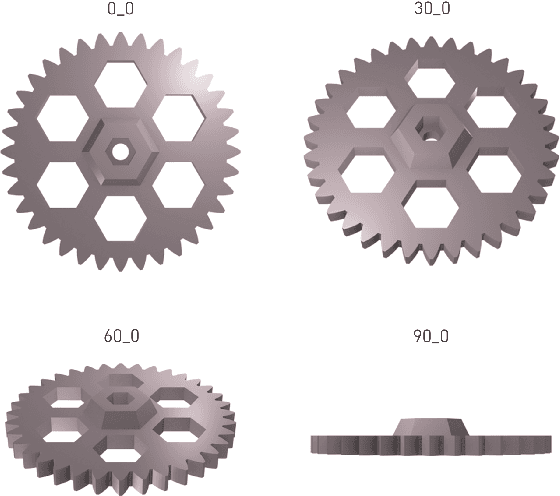
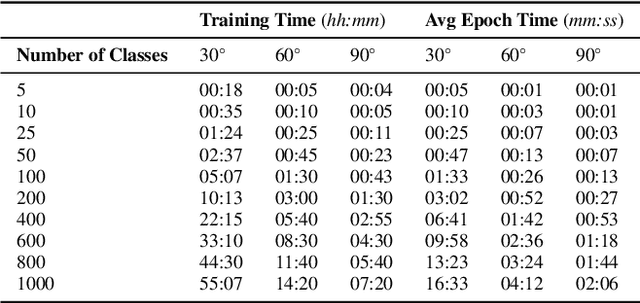
Prior work has shown Convolutional Neural Networks (CNNs) trained on surrogate Computer Aided Design (CAD) models are able to detect and classify real-world artefacts from photographs. The applications of which support twinning of digital and physical assets in design, including rapid extraction of part geometry from model repositories, information search \& retrieval and identifying components in the field for maintenance, repair, and recording. The performance of CNNs in classification tasks have been shown dependent on training data set size and number of classes. Where prior works have used relatively small surrogate model data sets ($<100$ models), the question remains as to the ability of a CNN to differentiate between models in increasingly large model repositories. This paper presents a method for generating synthetic image data sets from online CAD model repositories, and further investigates the capacity of an off-the-shelf CNN architecture trained on synthetic data to classify models as class size increases. 1,000 CAD models were curated and processed to generate large scale surrogate data sets, featuring model coverage at steps of 10$^{\circ}$, 30$^{\circ}$, 60$^{\circ}$, and 120$^{\circ}$ degrees. The findings demonstrate the capability of computer vision algorithms to classify artefacts in model repositories of up to 200, beyond this point the CNN's performance is observed to deteriorate significantly, limiting its present ability for automated twinning of physical to digital artefacts. Although, a match is more often found in the top-5 results showing potential for information search and retrieval on large repositories of surrogate models.
Intensity Harmonization for Airborne LiDAR
May 04, 2021
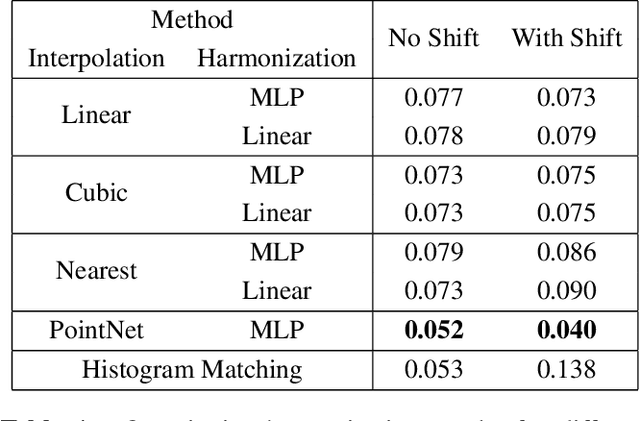

Constructing a point cloud for a large geographic region, such as a state or country, can require multiple years of effort. Often several vendors will be used to acquire LiDAR data, and a single region may be captured by multiple LiDAR scans. A key challenge is maintaining consistency between these scans, which includes point density, number of returns, and intensity. Intensity in particular can be very different between scans, even in areas that are overlapping. Harmonizing the intensity between scans to remove these discrepancies is expensive and time consuming. In this paper, we propose a novel method for point cloud harmonization based on deep neural networks. We evaluate our method quantitatively and qualitatively using a high quality real world LiDAR dataset. We compare our method to several baselines, including standard interpolation methods as well as histogram matching. We show that our method performs as well as the best baseline in areas with similar intensity distributions, and outperforms all baselines in areas with different intensity distributions. Source code is available at https://github.com/mvrl/lidar-harmonization .
European Language Grid: An Overview
Mar 30, 2020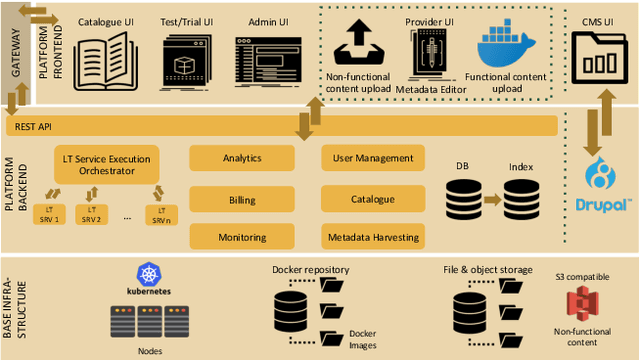

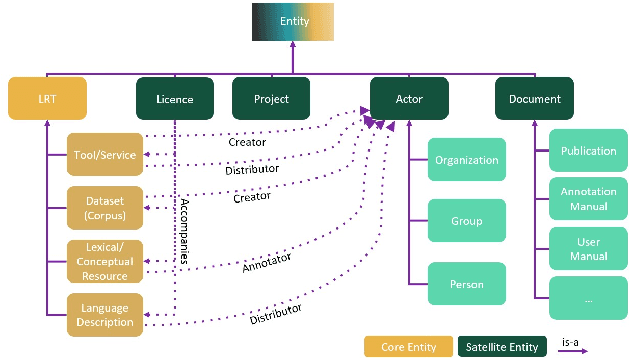
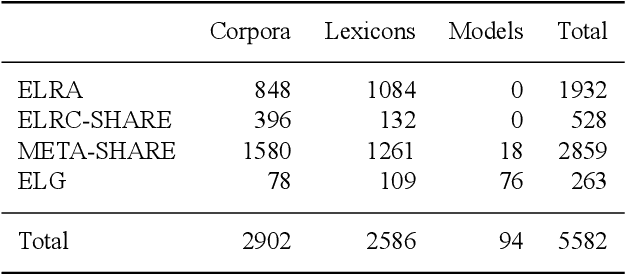
With 24 official EU and many additional languages, multilingualism in Europe and an inclusive Digital Single Market can only be enabled through Language Technologies (LTs). European LT business is dominated by hundreds of SMEs and a few large players. Many are world-class, with technologies that outperform the global players. However, European LT business is also fragmented, by nation states, languages, verticals and sectors, significantly holding back its impact. The European Language Grid (ELG) project addresses this fragmentation by establishing the ELG as the primary platform for LT in Europe. The ELG is a scalable cloud platform, providing, in an easy-to-integrate way, access to hundreds of commercial and non-commercial LTs for all European languages, including running tools and services as well as data sets and resources. Once fully operational, it will enable the commercial and non-commercial European LT community to deposit and upload their technologies and data sets into the ELG, to deploy them through the grid, and to connect with other resources. The ELG will boost the Multilingual Digital Single Market towards a thriving European LT community, creating new jobs and opportunities. Furthermore, the ELG project organises two open calls for up to 20 pilot projects. It also sets up 32 National Competence Centres (NCCs) and the European LT Council (LTC) for outreach and coordination purposes.
Evolutionary Deep Learning to Identify Galaxies in the Zone of Avoidance
Mar 20, 2019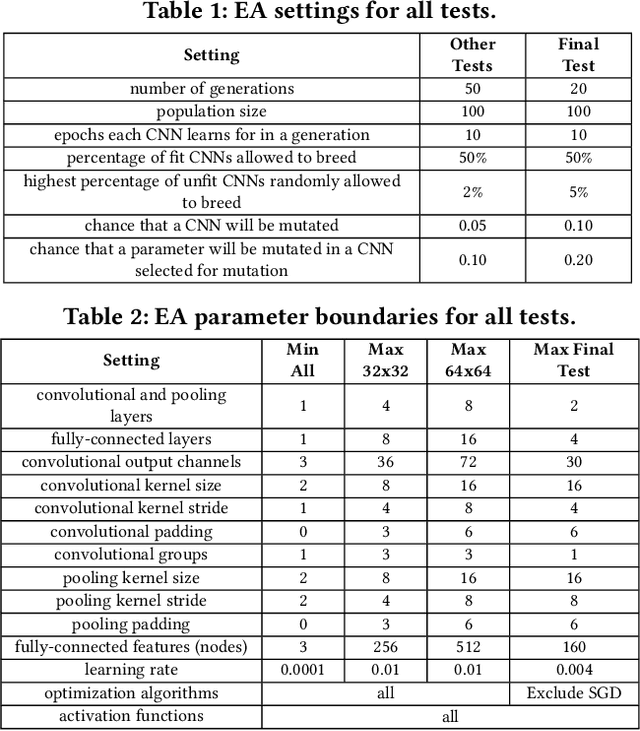
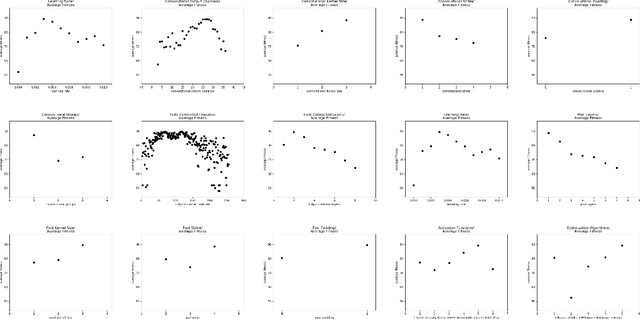
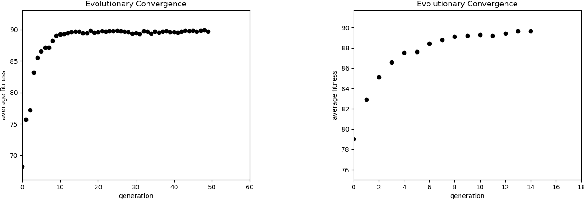
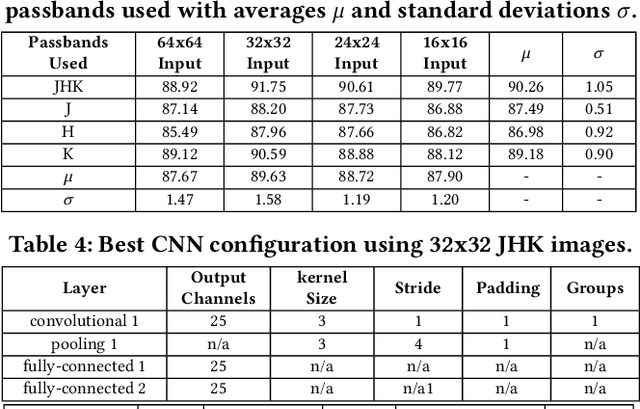
The Zone of Avoidance makes it difficult for astronomers to catalogue galaxies at low latitudes to our galactic plane due to high star densities and extinction. However, having a complete sky map of galaxies is important in a number of fields of research in astronomy. There are many unclassified sources of light in the Zone of Avoidance and it is therefore important that there exists an accurate automated system to identify and classify galaxies in this region. This study aims to evaluate the efficiency and accuracy of using an evolutionary algorithm to evolve the topology and configuration of Convolutional Neural Network (CNNs) to automatically identify galaxies in the Zone of Avoidance. A supervised learning method is used with data containing near-infrared images. Input image resolution and number of near-infrared passbands needed by the evolutionary algorithm is also analyzed while the accuracy of the best evolved CNN is compared to other CNN variants.