 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA lightweight Transformer-based model for fish landmark detection
Paper and Code
Sep 13, 2022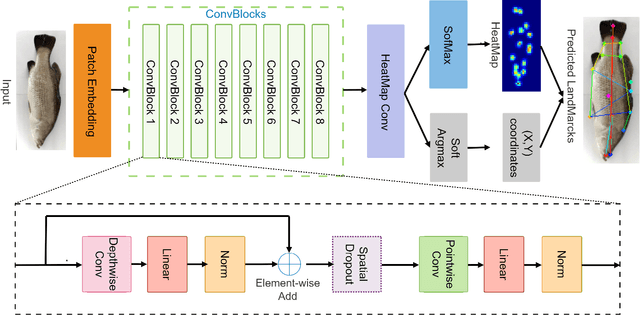
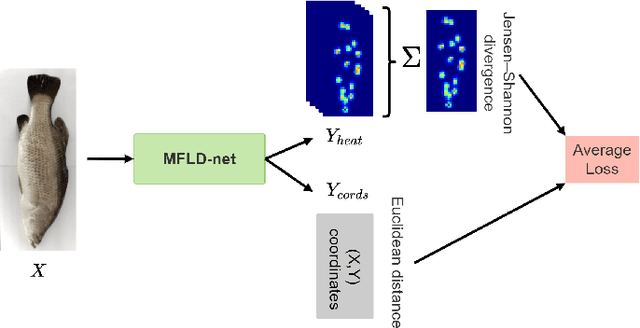


Transformer-based models, such as the Vision Transformer (ViT), can outperform onvolutional Neural Networks (CNNs) in some vision tasks when there is sufficient training data. However, (CNNs) have a strong and useful inductive bias for vision tasks (i.e. translation equivariance and locality). In this work, we developed a novel model architecture that we call a Mobile fish landmark detection network (MFLD-net). We have made this model using convolution operations based on ViT (i.e. Patch embeddings, Multi-Layer Perceptrons). MFLD-net can achieve competitive or better results in low data regimes while being lightweight and therefore suitable for embedded and mobile devices. Furthermore, we show that MFLD-net can achieve keypoint (landmark) estimation accuracies on-par or even better than some of the state-of-the-art (CNNs) on a fish image dataset. Additionally, unlike ViT, MFLD-net does not need a pre-trained model and can generalise well when trained on a small dataset. We provide quantitative and qualitative results that demonstrate the model's generalisation capabilities. This work will provide a foundation for future efforts in developing mobile, but efficient fish monitoring systems and devices.