 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Uncertainty Distribution in Deep Learning for Unsupervised Underwater Image Enhancement
Dec 18, 2022



One of the main challenges in deep learning-based underwater image enhancement is the limited availability of high-quality training data. Underwater images are difficult to capture and are often of poor quality due to the distortion and loss of colour and contrast in water. This makes it difficult to train supervised deep learning models on large and diverse datasets, which can limit the model's performance. In this paper, we explore an alternative approach to supervised underwater image enhancement. Specifically, we propose a novel unsupervised underwater image enhancement framework that employs a conditional variational autoencoder (cVAE) to train a deep learning model with probabilistic adaptive instance normalization (PAdaIN) and statistically guided multi-colour space stretch that produces realistic underwater images. The resulting framework is composed of a U-Net as a feature extractor and a PAdaIN to encode the uncertainty, which we call UDnet. To improve the visual quality of the images generated by UDnet, we use a statistically guided multi-colour space stretch module that ensures visual consistency with the input image and provides an alternative to training using a ground truth image. The proposed model does not need manual human annotation and can learn with a limited amount of data and achieves state-of-the-art results on underwater images. We evaluated our proposed framework on eight publicly-available datasets. The results show that our proposed framework yields competitive performance compared to other state-of-the-art approaches in quantitative as well as qualitative metrics. Code available at https://github.com/alzayats/UDnet .
A lightweight Transformer-based model for fish landmark detection
Sep 13, 2022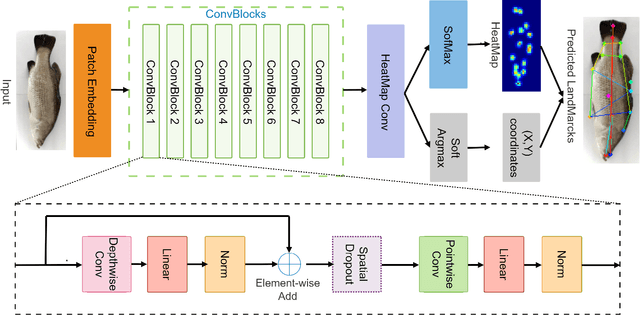
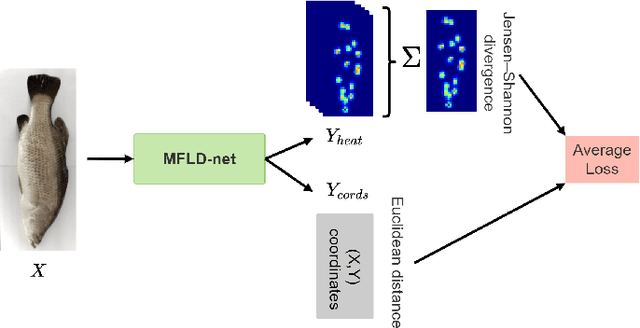


Transformer-based models, such as the Vision Transformer (ViT), can outperform onvolutional Neural Networks (CNNs) in some vision tasks when there is sufficient training data. However, (CNNs) have a strong and useful inductive bias for vision tasks (i.e. translation equivariance and locality). In this work, we developed a novel model architecture that we call a Mobile fish landmark detection network (MFLD-net). We have made this model using convolution operations based on ViT (i.e. Patch embeddings, Multi-Layer Perceptrons). MFLD-net can achieve competitive or better results in low data regimes while being lightweight and therefore suitable for embedded and mobile devices. Furthermore, we show that MFLD-net can achieve keypoint (landmark) estimation accuracies on-par or even better than some of the state-of-the-art (CNNs) on a fish image dataset. Additionally, unlike ViT, MFLD-net does not need a pre-trained model and can generalise well when trained on a small dataset. We provide quantitative and qualitative results that demonstrate the model's generalisation capabilities. This work will provide a foundation for future efforts in developing mobile, but efficient fish monitoring systems and devices.
Unsupervised Fish Trajectory Tracking and Segmentation
Aug 23, 2022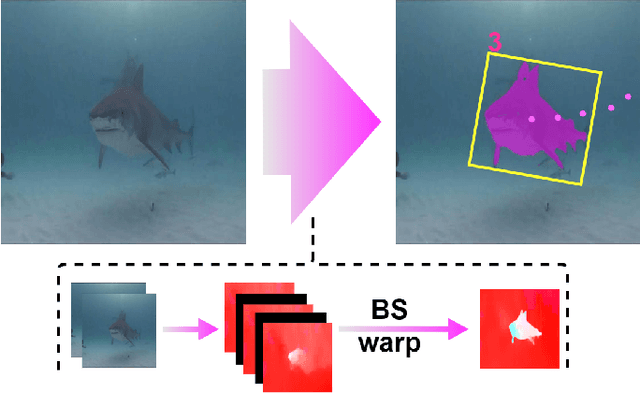


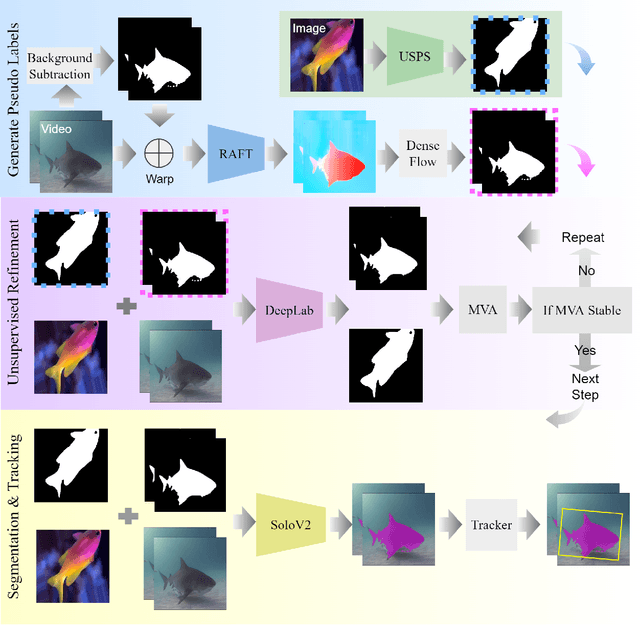
DNN for fish tracking and segmentation based on high-quality labels is expensive. Alternative unsupervised approaches rely on spatial and temporal variations that naturally occur in video data to generate noisy pseudo-ground-truth labels. These pseudo-labels are used to train a multi-task deep neural network. In this paper, we propose a three-stage framework for robust fish tracking and segmentation, where the first stage is an optical flow model, which generates the pseudo labels using spatial and temporal consistency between frames. In the second stage, a self-supervised model refines the pseudo-labels incrementally. In the third stage, the refined labels are used to train a segmentation network. No human annotations are used during the training or inference. Extensive experiments are performed to validate our method on three public underwater video datasets and to demonstrate that it is highly effective for video annotation and segmentation. We also evaluate the robustness of our framework to different imaging conditions and discuss the limitations of our current implementation.
Applications of Deep Learning in Fish Habitat Monitoring: A Tutorial and Survey
Jun 11, 2022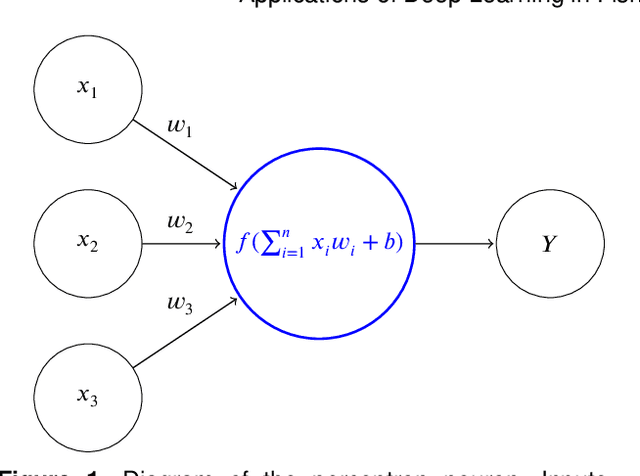
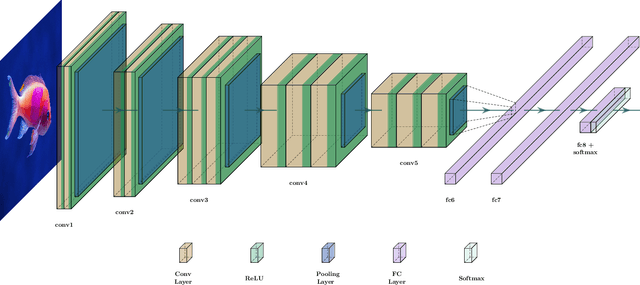

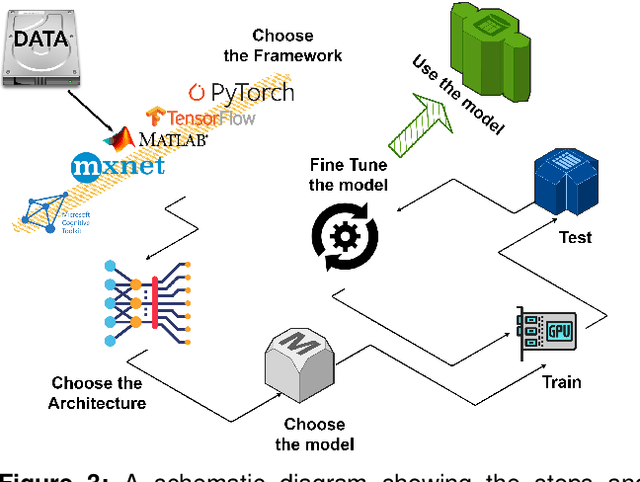
Marine ecosystems and their fish habitats are becoming increasingly important due to their integral role in providing a valuable food source and conservation outcomes. Due to their remote and difficult to access nature, marine environments and fish habitats are often monitored using underwater cameras. These cameras generate a massive volume of digital data, which cannot be efficiently analysed by current manual processing methods, which involve a human observer. DL is a cutting-edge AI technology that has demonstrated unprecedented performance in analysing visual data. Despite its application to a myriad of domains, its use in underwater fish habitat monitoring remains under explored. In this paper, we provide a tutorial that covers the key concepts of DL, which help the reader grasp a high-level understanding of how DL works. The tutorial also explains a step-by-step procedure on how DL algorithms should be developed for challenging applications such as underwater fish monitoring. In addition, we provide a comprehensive survey of key deep learning techniques for fish habitat monitoring including classification, counting, localization, and segmentation. Furthermore, we survey publicly available underwater fish datasets, and compare various DL techniques in the underwater fish monitoring domains. We also discuss some challenges and opportunities in the emerging field of deep learning for fish habitat processing. This paper is written to serve as a tutorial for marine scientists who would like to grasp a high-level understanding of DL, develop it for their applications by following our step-by-step tutorial, and see how it is evolving to facilitate their research efforts. At the same time, it is suitable for computer scientists who would like to survey state-of-the-art DL-based methodologies for fish habitat monitoring.
Transformer-based Self-Supervised Fish Segmentation in Underwater Videos
Jun 11, 2022
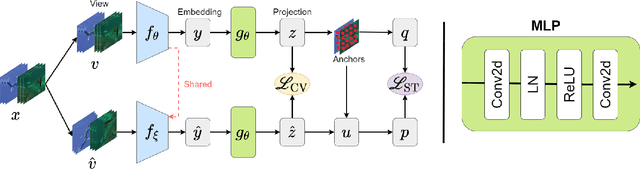
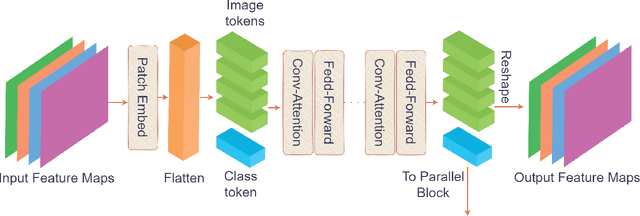
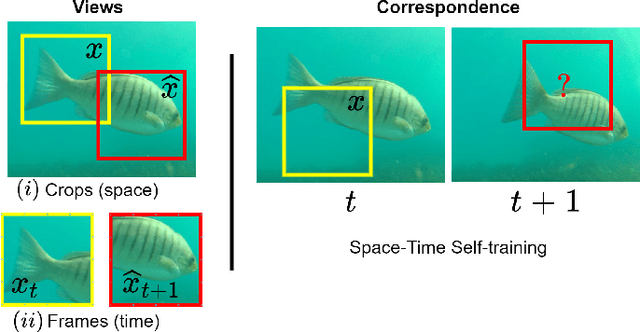
Underwater fish segmentation to estimate fish body measurements is still largely unsolved due to the complex underwater environment. Relying on fully-supervised segmentation models requires collecting per-pixel labels, which is time-consuming and prone to overfitting. Self-supervised learning methods can help avoid the requirement of large annotated training datasets, however, to be useful in real-world applications, they should achieve good segmentation quality. In this paper, we introduce a Transformer-based method that uses self-supervision for high-quality fish segmentation. Our proposed model is trained on videos -- without any annotations -- to perform fish segmentation in underwater videos taken in situ in the wild. We show that when trained on a set of underwater videos from one dataset, the proposed model surpasses previous CNN-based and Transformer-based self-supervised methods and achieves performance relatively close to supervised methods on two new unseen underwater video datasets. This demonstrates the great generalisability of our model and the fact that it does not need a pre-trained model. In addition, we show that, due to its dense representation learning, our model is compute-efficient. We provide quantitative and qualitative results that demonstrate our model's significant capabilities.