 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Fish Trajectory Tracking and Segmentation
Paper and Code
Aug 23, 2022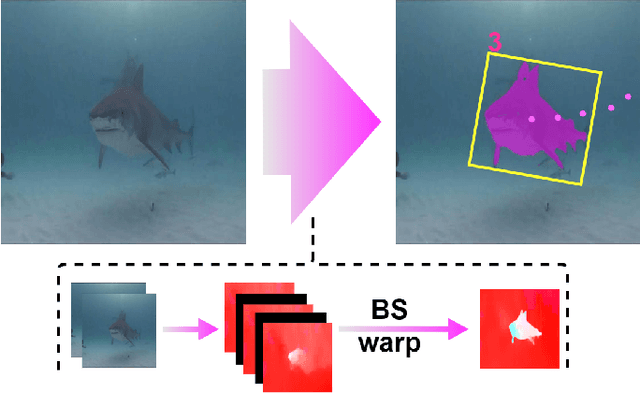


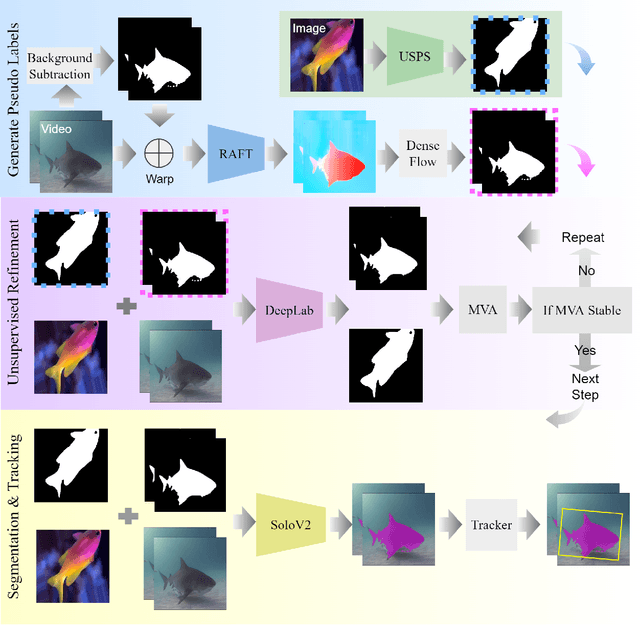
DNN for fish tracking and segmentation based on high-quality labels is expensive. Alternative unsupervised approaches rely on spatial and temporal variations that naturally occur in video data to generate noisy pseudo-ground-truth labels. These pseudo-labels are used to train a multi-task deep neural network. In this paper, we propose a three-stage framework for robust fish tracking and segmentation, where the first stage is an optical flow model, which generates the pseudo labels using spatial and temporal consistency between frames. In the second stage, a self-supervised model refines the pseudo-labels incrementally. In the third stage, the refined labels are used to train a segmentation network. No human annotations are used during the training or inference. Extensive experiments are performed to validate our method on three public underwater video datasets and to demonstrate that it is highly effective for video annotation and segmentation. We also evaluate the robustness of our framework to different imaging conditions and discuss the limitations of our current implementation.