 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Estimation of User Learning in Personalized Systems
Jun 01, 2023



In online platforms, the impact of a treatment on an observed outcome may change over time as 1) users learn about the intervention, and 2) the system personalization, such as individualized recommendations, change over time. We introduce a non-parametric causal model of user actions in a personalized system. We show that the Cookie-Cookie-Day (CCD) experiment, designed for the measurement of the user learning effect, is biased when there is personalization. We derive new experimental designs that intervene in the personalization system to generate the variation necessary to separately identify the causal effect mediated through user learning and personalization. Making parametric assumptions allows for the estimation of long-term causal effects based on medium-term experiments. In simulations, we show that our new designs successfully recover the dynamic causal effects of interest.
BAM: Bayes with Adaptive Memory
Feb 08, 2022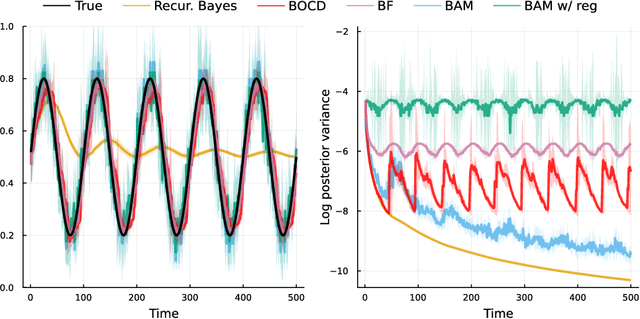
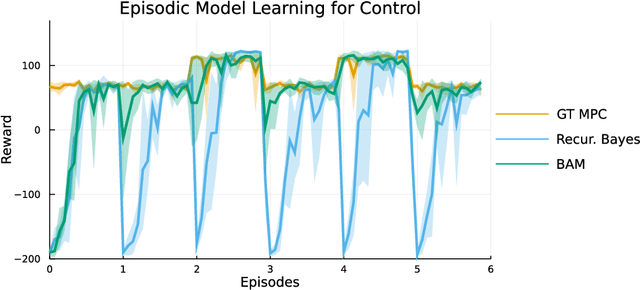
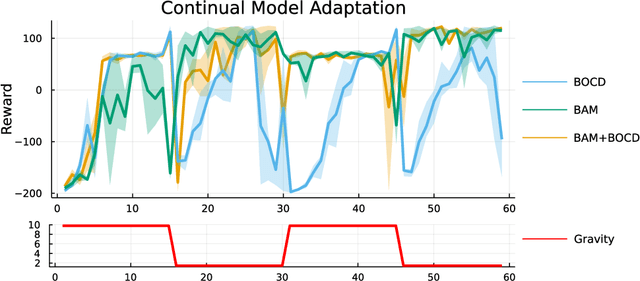
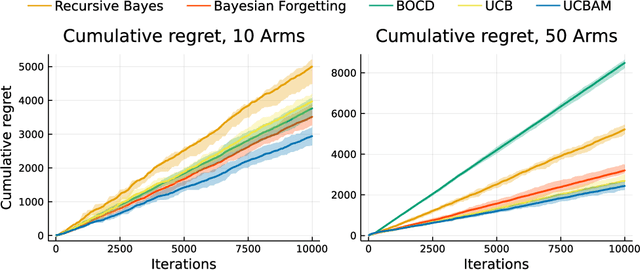
Online learning via Bayes' theorem allows new data to be continuously integrated into an agent's current beliefs. However, a naive application of Bayesian methods in non stationary environments leads to slow adaptation and results in state estimates that may converge confidently to the wrong parameter value. A common solution when learning in changing environments is to discard/downweight past data; however, this simple mechanism of "forgetting" fails to account for the fact that many real-world environments involve revisiting similar states. We propose a new framework, Bayes with Adaptive Memory (BAM), that takes advantage of past experience by allowing the agent to choose which past observations to remember and which to forget. We demonstrate that BAM generalizes many popular Bayesian update rules for non-stationary environments. Through a variety of experiments, we demonstrate the ability of BAM to continuously adapt in an ever-changing world.
Dynamic Tensor Rematerialization
Jun 18, 2020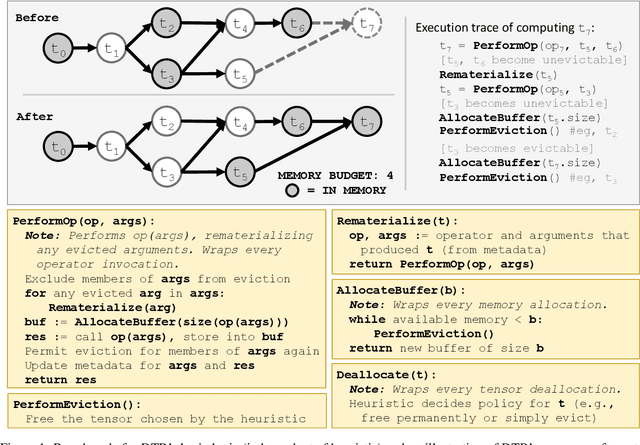

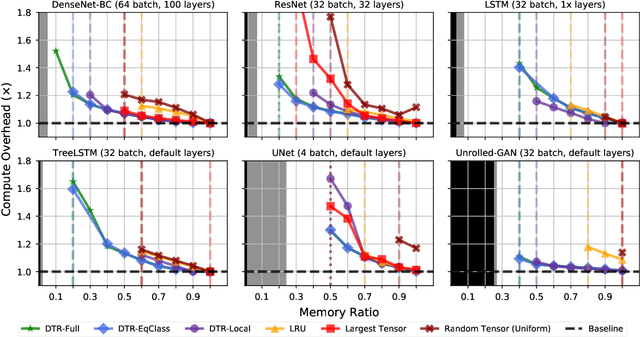
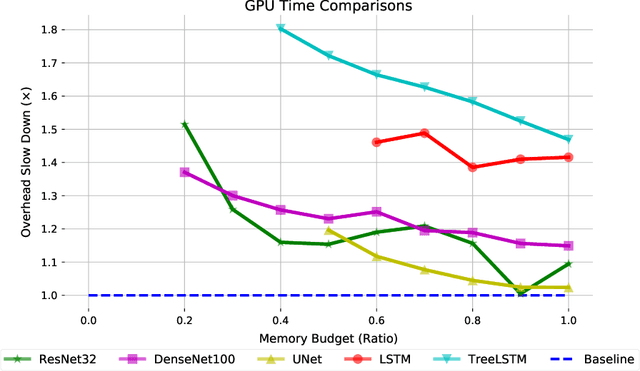
Checkpointing enables training larger models by freeing intermediate activations and recomputing them on demand. Previous checkpointing techniques are difficult to generalize to dynamic models because they statically plan recomputations offline. We present Dynamic Tensor Rematerialization (DTR), a greedy online algorithm for heuristically checkpointing arbitrary models. DTR is extensible and general: it is parameterized by an eviction policy and only collects lightweight metadata on tensors and operators. Though DTR has no advance knowledge of the model or training task, we prove it can train an $N$-layer feedforward network on an $\Omega(\sqrt{N})$ memory budget with only $\mathcal{O}(N)$ tensor operations. Moreover, we identify a general eviction heuristic and show how it allows DTR to automatically provide favorable checkpointing performance across a variety of models and memory budgets.
Estimating the number and effect sizes of non-null hypotheses
Feb 17, 2020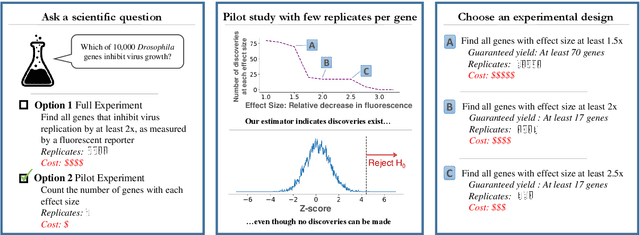
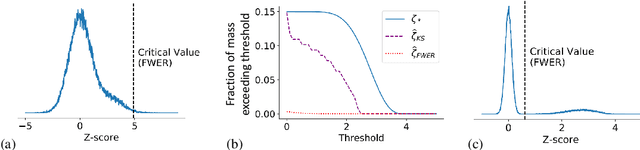
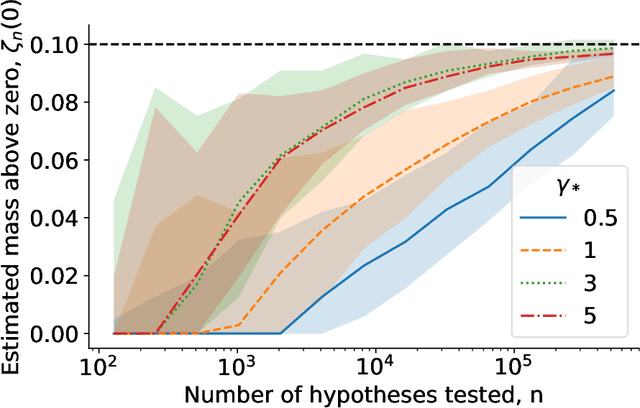
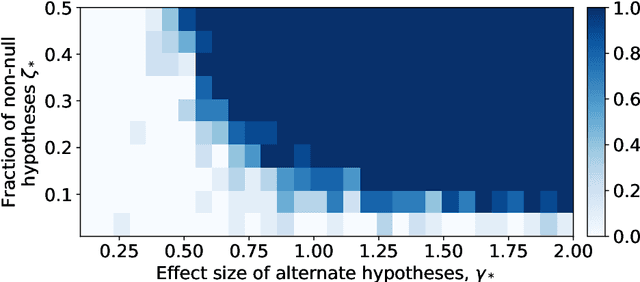
We study the problem of estimating the distribution of effect sizes (the mean of the test statistic under the alternate hypothesis) in a multiple testing setting. Knowing this distribution allows us to calculate the power (type II error) of any experimental design. We show that it is possible to estimate this distribution using an inexpensive pilot experiment, which takes significantly fewer samples than would be required by an experiment that identified the discoveries. Our estimator can be used to guarantee the number of discoveries that will be made using a given experimental design in a future experiment. We prove that this simple and computationally efficient estimator enjoys a number of favorable theoretical properties, and demonstrate its effectiveness on data from a gene knockout experiment on influenza inhibition in Drosophila.