 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAM: Bayes with Adaptive Memory
Feb 08, 2022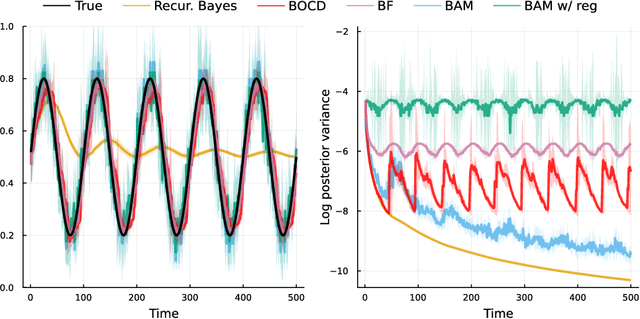
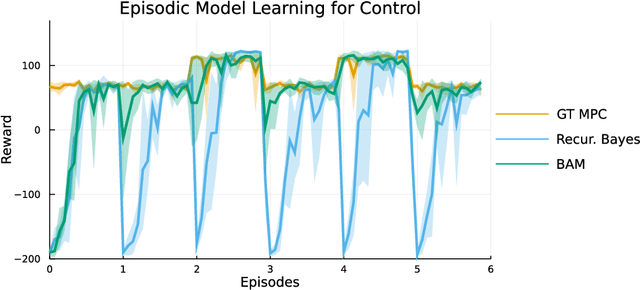
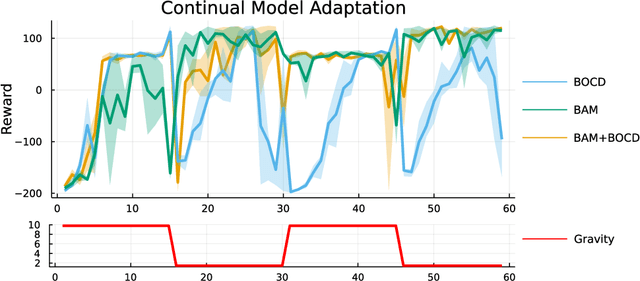
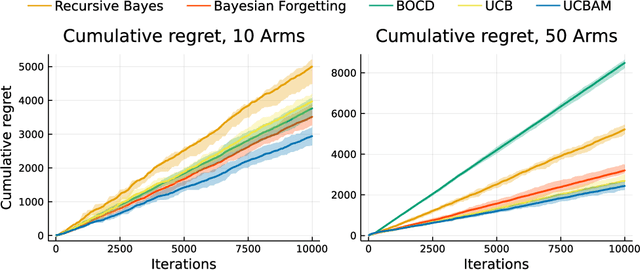
Online learning via Bayes' theorem allows new data to be continuously integrated into an agent's current beliefs. However, a naive application of Bayesian methods in non stationary environments leads to slow adaptation and results in state estimates that may converge confidently to the wrong parameter value. A common solution when learning in changing environments is to discard/downweight past data; however, this simple mechanism of "forgetting" fails to account for the fact that many real-world environments involve revisiting similar states. We propose a new framework, Bayes with Adaptive Memory (BAM), that takes advantage of past experience by allowing the agent to choose which past observations to remember and which to forget. We demonstrate that BAM generalizes many popular Bayesian update rules for non-stationary environments. Through a variety of experiments, we demonstrate the ability of BAM to continuously adapt in an ever-changing world.
Koopman Spectrum Nonlinear Regulator and Provably Efficient Online Learning
Jun 30, 2021

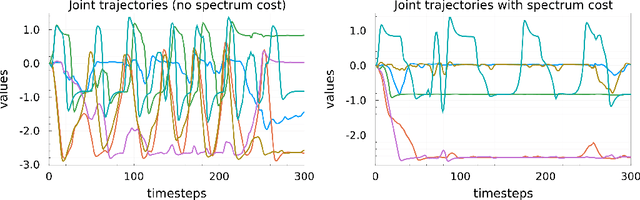

Most modern reinforcement learning algorithms optimize a cumulative single-step cost along a trajectory. The optimized motions are often 'unnatural', representing, for example, behaviors with sudden accelerations that waste energy and lack predictability. In this work, we present a novel paradigm of controlling nonlinear systems via the minimization of the Koopman spectrum cost: a cost over the Koopman operator of the controlled dynamics. This induces a broader class of dynamical behaviors that evolve over stable manifolds such as nonlinear oscillators, closed loops, and smooth movements. We demonstrate that some dynamics realizations that are not possible with a cumulative cost are feasible in this paradigm. Moreover, we present a provably efficient online learning algorithm for our problem that enjoys a sub-linear regret bound under some structural assumptions.
Faster Policy Learning with Continuous-Time Gradients
Dec 12, 2020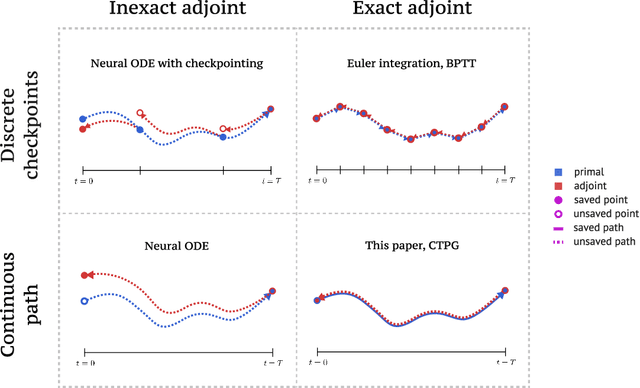
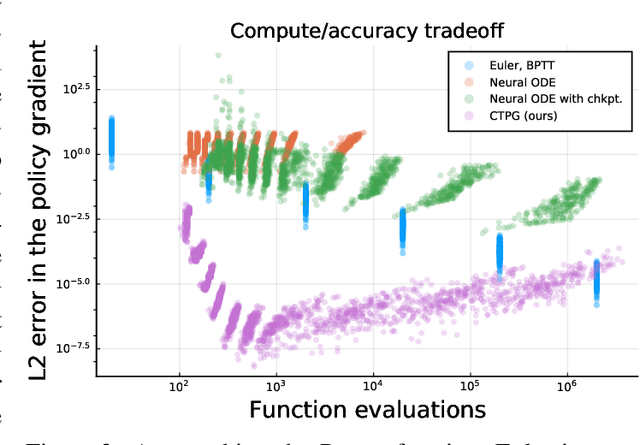
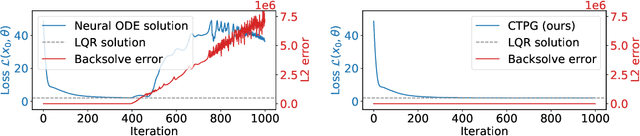
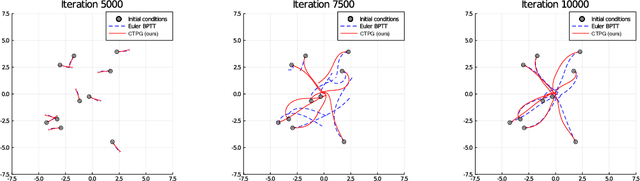
We study the estimation of policy gradients for continuous-time systems with known dynamics. By reframing policy learning in continuous-time, we show that it is possible construct a more efficient and accurate gradient estimator. The standard back-propagation through time estimator (BPTT) computes exact gradients for a crude discretization of the continuous-time system. In contrast, we approximate continuous-time gradients in the original system. With the explicit goal of estimating continuous-time gradients, we are able to discretize adaptively and construct a more efficient policy gradient estimator which we call the Continuous-Time Policy Gradient (CTPG). We show that replacing BPTT policy gradients with more efficient CTPG estimates results in faster and more robust learning in a variety of control tasks and simulators.
Information Theoretic Regret Bounds for Online Nonlinear Control
Jun 22, 2020


This work studies the problem of sequential control in an unknown, nonlinear dynamical system, where we model the underlying system dynamics as an unknown function in a known Reproducing Kernel Hilbert Space. This framework yields a general setting that permits discrete and continuous control inputs as well as non-smooth, non-differentiable dynamics. Our main result, the Lower Confidence-based Continuous Control ($LC^3$) algorithm, enjoys a near-optimal $O(\sqrt{T})$ regret bound against the optimal controller in episodic settings, where $T$ is the number of episodes. The bound has no explicit dependence on dimension of the system dynamics, which could be infinite, but instead only depends on information theoretic quantities. We empirically show its application to a number of nonlinear control tasks and demonstrate the benefit of exploration for learning model dynamics.
Model-Based Generalization Under Parameter Uncertainty Using Path Integral Control
Jun 04, 2020



This work addresses the problem of robot interaction in complex environments where online control and adaptation is necessary. By expanding the sample space in the free energy formulation of path integral control, we derive a natural extension to the path integral control that embeds uncertainty into action and provides robustness for model-based robot planning. Our algorithm is applied to a diverse set of tasks using different robots and validate our results in simulation and real-world experiments. We further show that our method is capable of running in real-time without loss of performance. Videos of the experiments as well as additional implementation details can be found at https://sites.google.com/view/emppi.
Lyceum: An efficient and scalable ecosystem for robot learning
Jan 21, 2020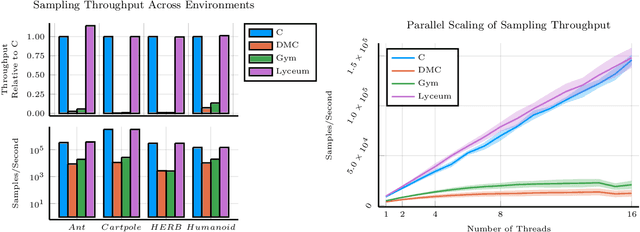

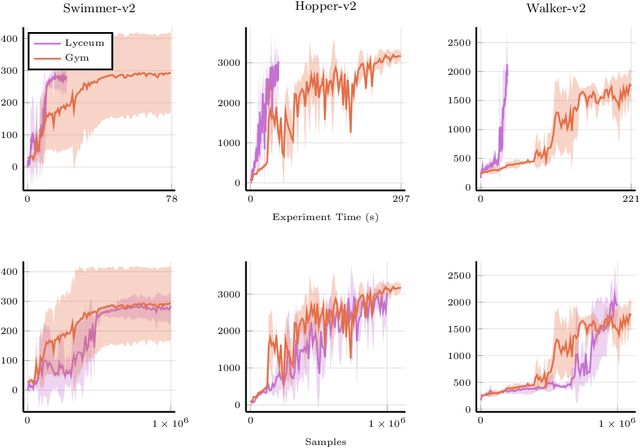
We introduce Lyceum, a high-performance computational ecosystem for robot learning. Lyceum is built on top of the Julia programming language and the MuJoCo physics simulator, combining the ease-of-use of a high-level programming language with the performance of native C. In addition, Lyceum has a straightforward API to support parallel computation across multiple cores and machines. Overall, depending on the complexity of the environment, Lyceum is 5-30x faster compared to other popular abstractions like OpenAI's Gym and DeepMind's dm-control. This substantially reduces training time for various reinforcement learning algorithms; and is also fast enough to support real-time model predictive control through MuJoCo. The code, tutorials, and demonstration videos can be found at: www.lyceum.ml.
Plan Online, Learn Offline: Efficient Learning and Exploration via Model-Based Control
Jan 28, 2019
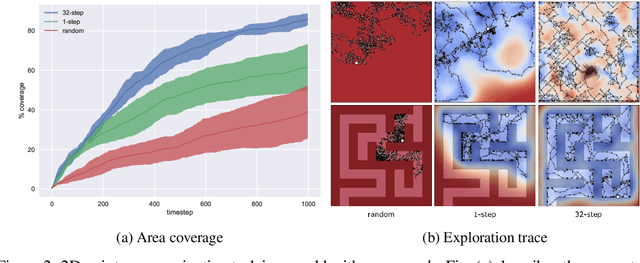
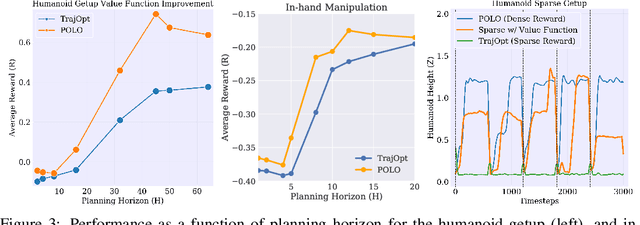
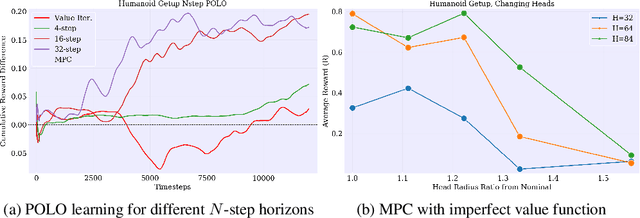
We propose a plan online and learn offline (POLO) framework for the setting where an agent, with an internal model, needs to continually act and learn in the world. Our work builds on the synergistic relationship between local model-based control, global value function learning, and exploration. We study how local trajectory optimization can cope with approximation errors in the value function, and can stabilize and accelerate value function learning. Conversely, we also study how approximate value functions can help reduce the planning horizon and allow for better policies beyond local solutions. Finally, we also demonstrate how trajectory optimization can be used to perform temporally coordinated exploration in conjunction with estimating uncertainty in value function approximation. This exploration is critical for fast and stable learning of the value function. Combining these components enable solutions to complex simulated control tasks, like humanoid locomotion and dexterous in-hand manipulation, in the equivalent of a few minutes of experience in the real world.
Reinforcement learning for non-prehensile manipulation: Transfer from simulation to physical system
Mar 28, 2018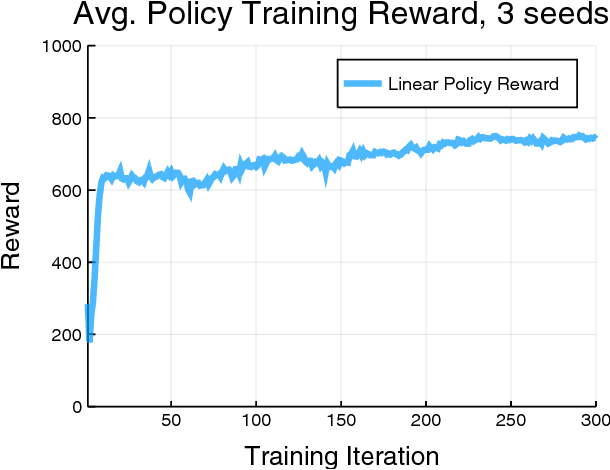

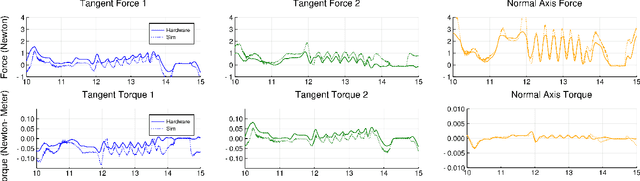
Reinforcement learning has emerged as a promising methodology for training robot controllers. However, most results have been limited to simulation due to the need for a large number of samples and the lack of automated-yet-safe data collection methods. Model-based reinforcement learning methods provide an avenue to circumvent these challenges, but the traditional concern has been the mismatch between the simulator and the real world. Here, we show that control policies learned in simulation can successfully transfer to a physical system, composed of three Phantom robots pushing an object to various desired target positions. We use a modified form of the natural policy gradient algorithm for learning, applied to a carefully identified simulation model. The resulting policies, trained entirely in simulation, work well on the physical system without additional training. In addition, we show that training with an ensemble of models makes the learned policies more robust to modeling errors, thus compensating for difficulties in system identification.
Towards Generalization and Simplicity in Continuous Control
Mar 20, 2018
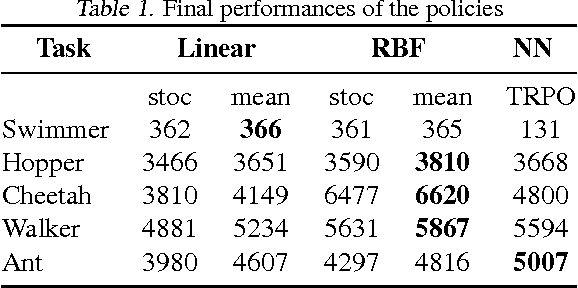
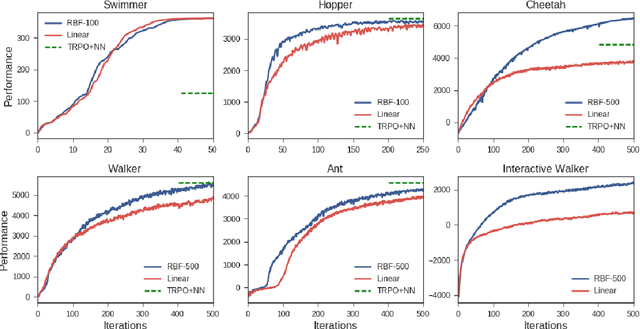
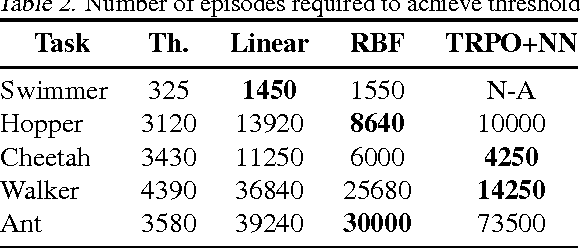
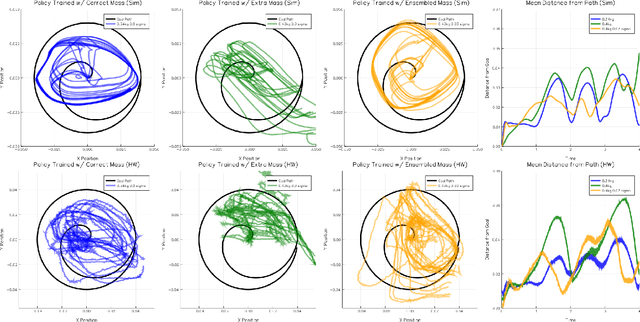
This work shows that policies with simple linear and RBF parameterizations can be trained to solve a variety of continuous control tasks, including the OpenAI gym benchmarks. The performance of these trained policies are competitive with state of the art results, obtained with more elaborate parameterizations such as fully connected neural networks. Furthermore, existing training and testing scenarios are shown to be very limited and prone to over-fitting, thus giving rise to only trajectory-centric policies. Training with a diverse initial state distribution is shown to produce more global policies with better generalization. This allows for interactive control scenarios where the system recovers from large on-line perturbations; as shown in the supplementary video.