 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Policy Learning with Continuous-Time Gradients
Dec 12, 2020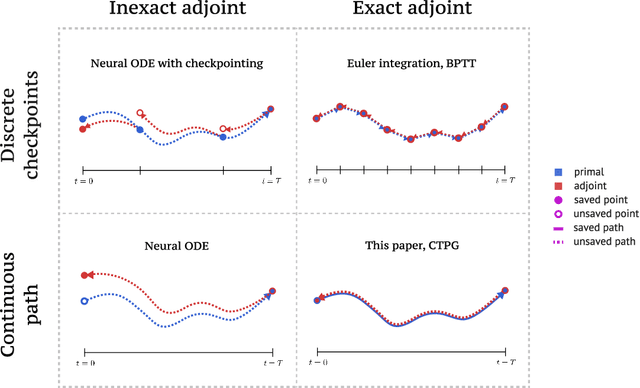
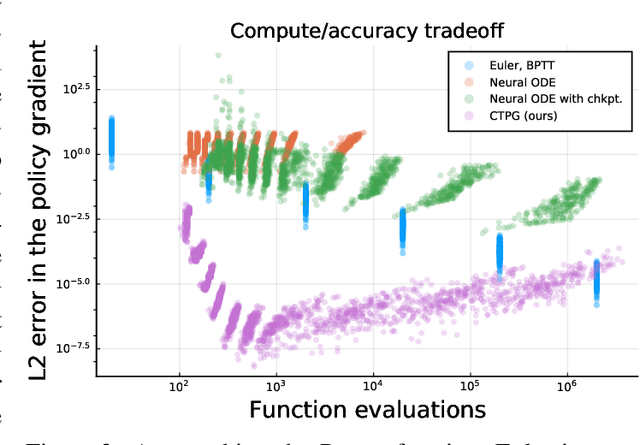
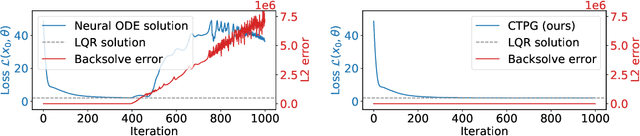
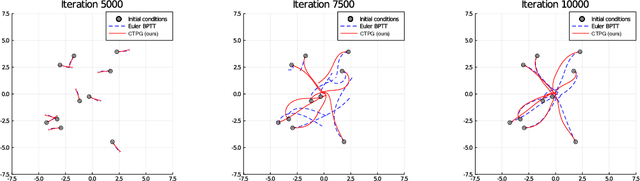
We study the estimation of policy gradients for continuous-time systems with known dynamics. By reframing policy learning in continuous-time, we show that it is possible construct a more efficient and accurate gradient estimator. The standard back-propagation through time estimator (BPTT) computes exact gradients for a crude discretization of the continuous-time system. In contrast, we approximate continuous-time gradients in the original system. With the explicit goal of estimating continuous-time gradients, we are able to discretize adaptively and construct a more efficient policy gradient estimator which we call the Continuous-Time Policy Gradient (CTPG). We show that replacing BPTT policy gradients with more efficient CTPG estimates results in faster and more robust learning in a variety of control tasks and simulators.
Mosaic: A Sample-Based Database System for Open World Query Processing
Jan 10, 2020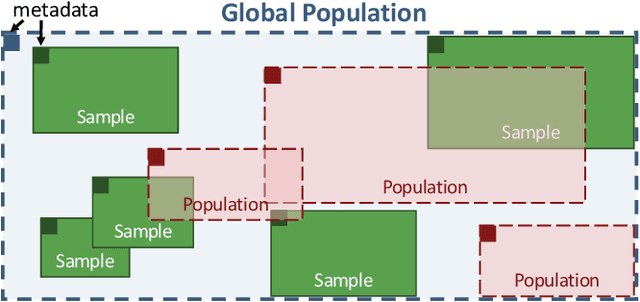
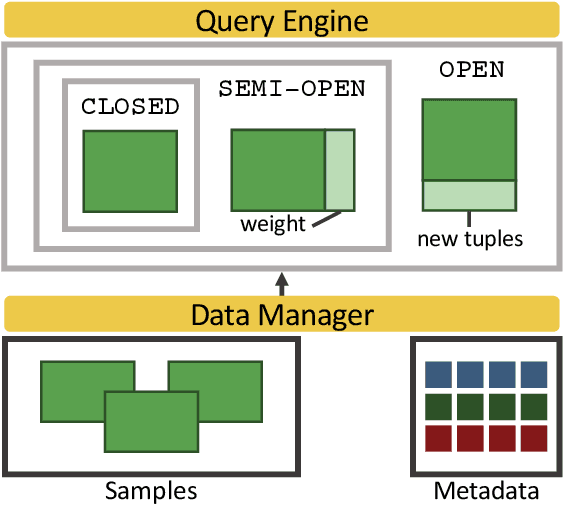

Data scientists have relied on samples to analyze populations of interest for decades. Recently, with the increase in the number of public data repositories, sample data has become easier to access. It has not, however, become easier to analyze. This sample data is arbitrarily biased with an unknown sampling probability, meaning data scientists must manually debias the sample with custom techniques to avoid inaccurate results. In this vision paper, we propose Mosaic, a database system that treats samples as first-class citizens and allows users to ask questions over populations represented by these samples. Answering queries over biased samples is non-trivial as there is no existing, standard technique to answer population queries when the sampling probability is unknown. In this paper, we show how our envisioned system solves this problem by having a unique sample-based data model with extensions to the SQL language. We propose how to perform population query answering using biased samples and give preliminary results for one of our novel query answering techniques.
Mo' States Mo' Problems: Emergency Stop Mechanisms from Observation
Dec 03, 2019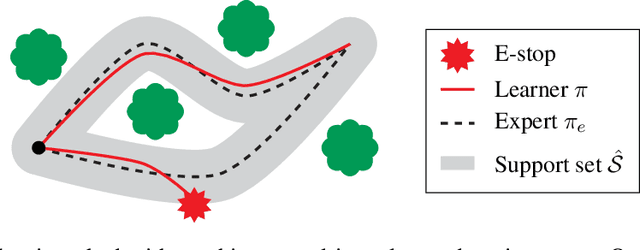
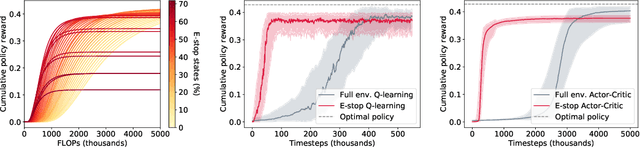
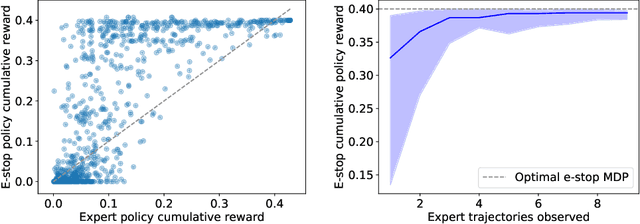
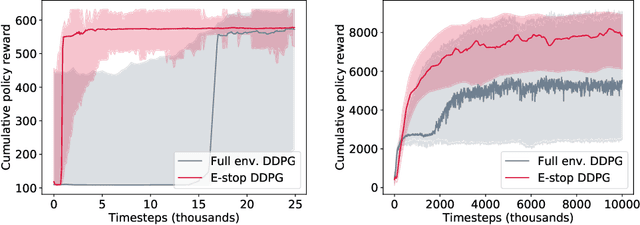
In many environments, only a relatively small subset of the complete state space is necessary in order to accomplish a given task. We develop a simple technique using emergency stops (e-stops) to exploit this phenomenon. Using e-stops significantly improves sample complexity by reducing the amount of required exploration, while retaining a performance bound that efficiently trades off the rate of convergence with a small asymptotic sub-optimality gap. We analyze the regret behavior of e-stops and present empirical results in discrete and continuous settings demonstrating that our reset mechanism can provide order-of-magnitude speedups on top of existing reinforcement learning methods.
Interpretable VAEs for nonlinear group factor analysis
Feb 17, 2018
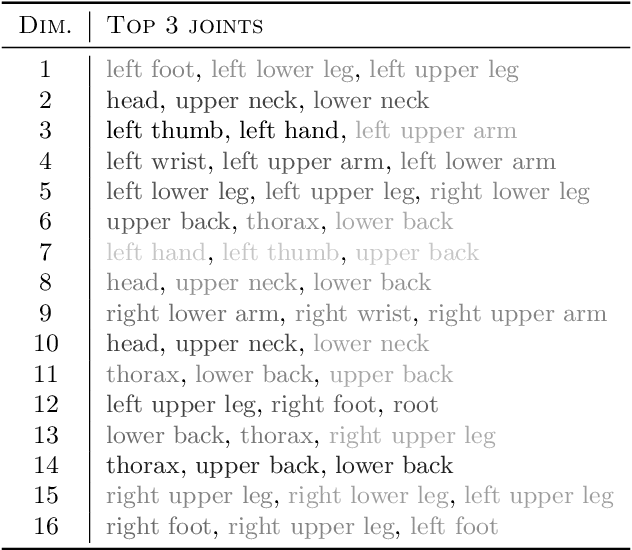
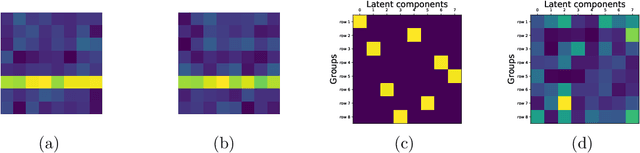
Deep generative models have recently yielded encouraging results in producing subjectively realistic samples of complex data. Far less attention has been paid to making these generative models interpretable. In many scenarios, ranging from scientific applications to finance, the observed variables have a natural grouping. It is often of interest to understand systems of interaction amongst these groups, and latent factor models (LFMs) are an attractive approach. However, traditional LFMs are limited by assuming a linear correlation structure. We present an output interpretable VAE (oi-VAE) for grouped data that models complex, nonlinear latent-to-observed relationships. We combine a structured VAE comprised of group-specific generators with a sparsity-inducing prior. We demonstrate that oi-VAE yields meaningful notions of interpretability in the analysis of motion capture and MEG data. We further show that in these situations, the regularization inherent to oi-VAE can actually lead to improved generalization and learned generative processes.