 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitating Language via Scalable Inverse Reinforcement Learning
Sep 02, 2024
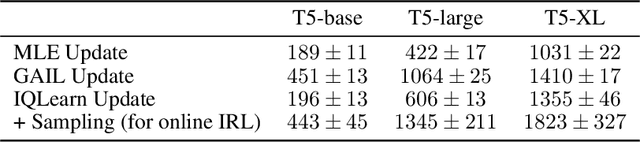
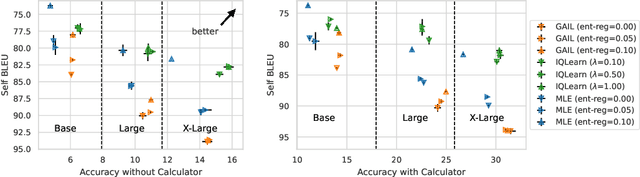

The majority of language model training builds on imitation learning. It covers pretraining, supervised fine-tuning, and affects the starting conditions for reinforcement learning from human feedback (RLHF). The simplicity and scalability of maximum likelihood estimation (MLE) for next token prediction led to its role as predominant paradigm. However, the broader field of imitation learning can more effectively utilize the sequential structure underlying autoregressive generation. We focus on investigating the inverse reinforcement learning (IRL) perspective to imitation, extracting rewards and directly optimizing sequences instead of individual token likelihoods and evaluate its benefits for fine-tuning large language models. We provide a new angle, reformulating inverse soft-Q-learning as a temporal difference regularized extension of MLE. This creates a principled connection between MLE and IRL and allows trading off added complexity with increased performance and diversity of generations in the supervised fine-tuning (SFT) setting. We find clear advantages for IRL-based imitation, in particular for retaining diversity while maximizing task performance, rendering IRL a strong alternative on fixed SFT datasets even without online data generation. Our analysis of IRL-extracted reward functions further indicates benefits for more robust reward functions via tighter integration of supervised and preference-based LLM post-training.
Massively Scalable Inverse Reinforcement Learning in Google Maps
May 24, 2023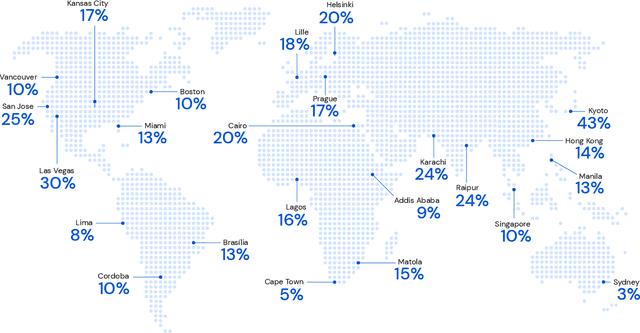
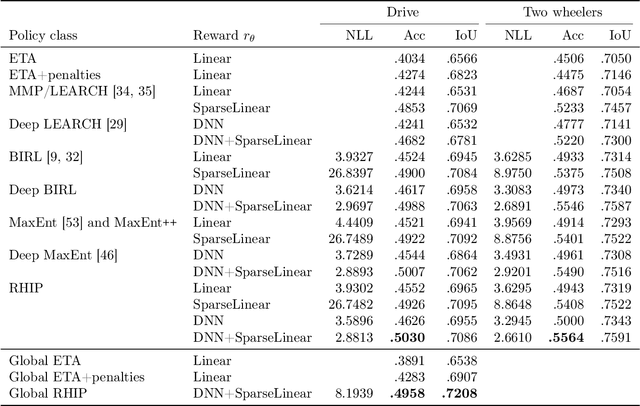
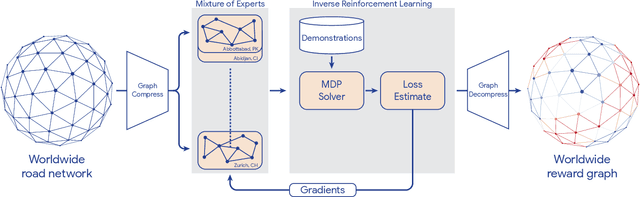

Optimizing for humans' latent preferences is a grand challenge in route recommendation, where globally-scalable solutions remain an open problem. Although past work created increasingly general solutions for the application of inverse reinforcement learning (IRL), these have not been successfully scaled to world-sized MDPs, large datasets, and highly parameterized models; respectively hundreds of millions of states, trajectories, and parameters. In this work, we surpass previous limitations through a series of advancements focused on graph compression, parallelization, and problem initialization based on dominant eigenvectors. We introduce Receding Horizon Inverse Planning (RHIP), which generalizes existing work and enables control of key performance trade-offs via its planning horizon. Our policy achieves a 16-24% improvement in global route quality, and, to our knowledge, represents the largest instance of IRL in a real-world setting to date. Our results show critical benefits to more sustainable modes of transportation (e.g. two-wheelers), where factors beyond journey time (e.g. route safety) play a substantial role. We conclude with ablations of key components, negative results on state-of-the-art eigenvalue solvers, and identify future opportunities to improve scalability via IRL-specific batching strategies.
Smartphone-based Hard-braking Event Detection at Scale for Road Safety Services
Feb 04, 2022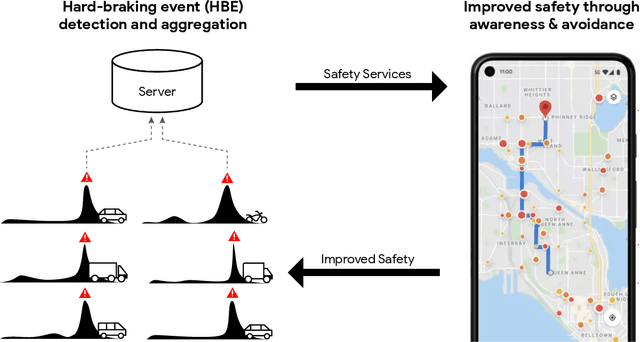
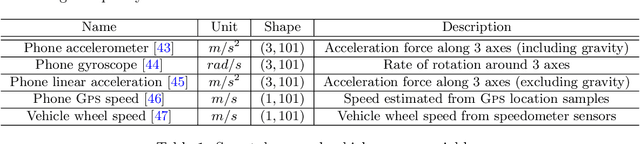
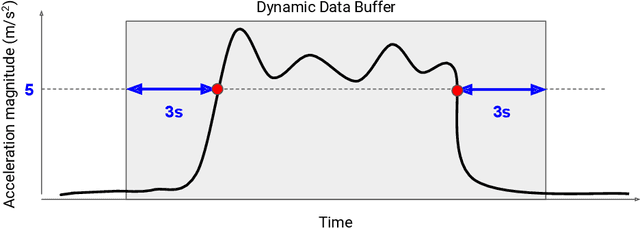

Road crashes are the sixth leading cause of lost disability-adjusted life-years (DALYs) worldwide. One major challenge in traffic safety research is the sparsity of crashes, which makes it difficult to achieve a fine-grain understanding of crash causations and predict future crash risk in a timely manner. Hard-braking events have been widely used as a safety surrogate due to their relatively high prevalence and ease of detection with embedded vehicle sensors. As an alternative to using sensors fixed in vehicles, this paper presents a scalable approach for detecting hard-braking events using the kinematics data collected from smartphone sensors. We train a Transformer-based machine learning model for hard-braking event detection using concurrent sensor readings from smartphones and vehicle sensors from drivers who connect their phone to the vehicle while navigating in Google Maps. The detection model shows superior performance with a $0.83$ Area under the Precision-Recall Curve (PR-AUC), which is $3.8\times$better than a GPS speed-based heuristic model, and $166.6\times$better than an accelerometer-based heuristic model. The detected hard-braking events are strongly correlated with crashes from publicly available datasets, supporting their use as a safety surrogate. In addition, we conduct model fairness and selection bias evaluation to ensure that the safety benefits are equally shared. The developed methodology can benefit many safety applications such as identifying safety hot spots at road network level, evaluating the safety of new user interfaces, as well as using routing to improve traffic safety.
Examining COVID-19 Forecasting using Spatio-Temporal Graph Neural Networks
Jul 06, 2020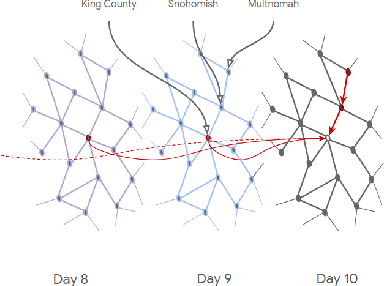
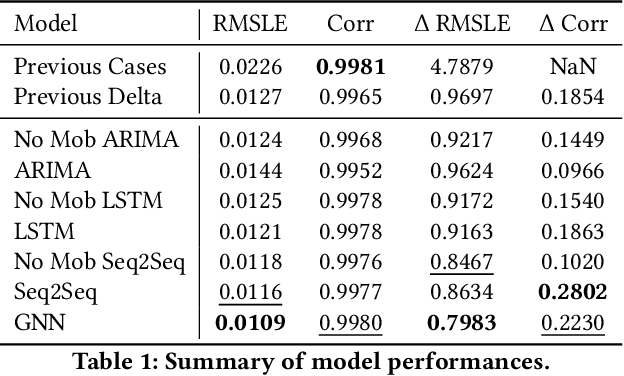
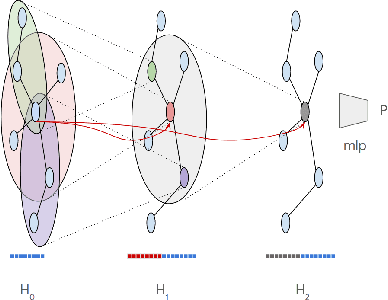
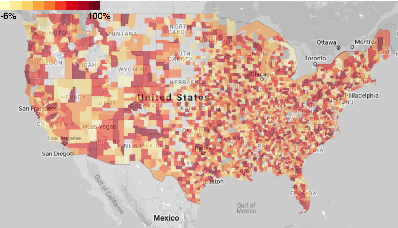
In this work, we examine a novel forecasting approach for COVID-19 case prediction that uses Graph Neural Networks and mobility data. In contrast to existing time series forecasting models, the proposed approach learns from a single large-scale spatio-temporal graph, where nodes represent the region-level human mobility, spatial edges represent the human mobility based inter-region connectivity, and temporal edges represent node features through time. We evaluate this approach on the US county level COVID-19 dataset, and demonstrate that the rich spatial and temporal information leveraged by the graph neural network allows the model to learn complex dynamics. We show a 6% reduction of RMSLE and an absolute Pearson Correlation improvement from 0.9978 to 0.998 compared to the best performing baseline models. This novel source of information combined with graph based deep learning approaches can be a powerful tool to understand the spread and evolution of COVID-19. We encourage others to further develop a novel modeling paradigm for infectious disease based on GNNs and high resolution mobility data.
Mo' States Mo' Problems: Emergency Stop Mechanisms from Observation
Dec 03, 2019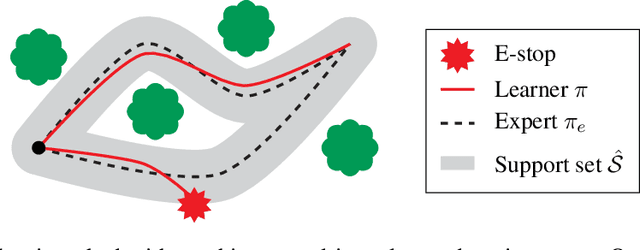
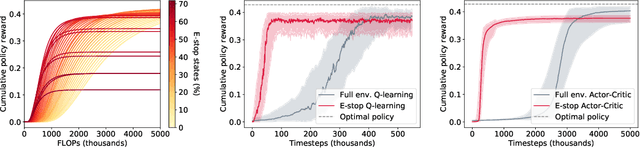
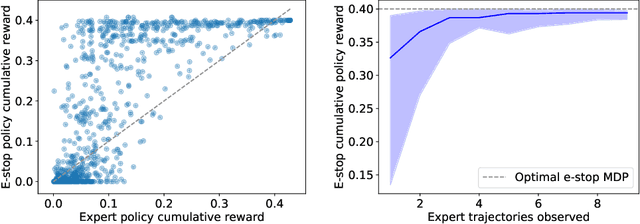
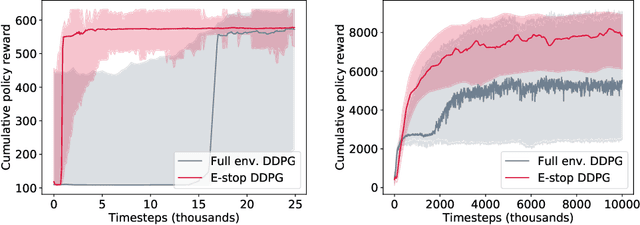
In many environments, only a relatively small subset of the complete state space is necessary in order to accomplish a given task. We develop a simple technique using emergency stops (e-stops) to exploit this phenomenon. Using e-stops significantly improves sample complexity by reducing the amount of required exploration, while retaining a performance bound that efficiently trades off the rate of convergence with a small asymptotic sub-optimality gap. We analyze the regret behavior of e-stops and present empirical results in discrete and continuous settings demonstrating that our reset mechanism can provide order-of-magnitude speedups on top of existing reinforcement learning methods.
Adaptive Robot-Assisted Feeding: An Online Learning Framework for Acquiring Previously-Unseen Food Items
Sep 16, 2019
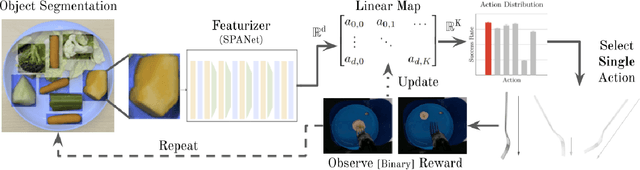
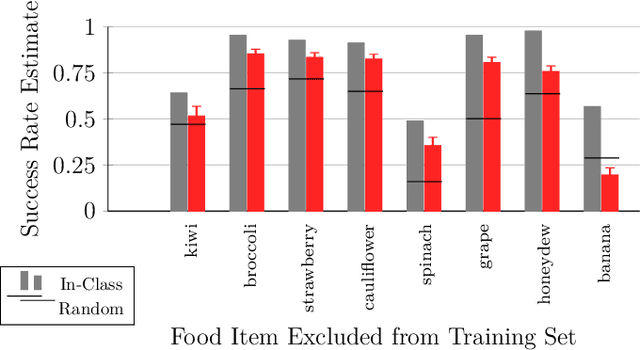
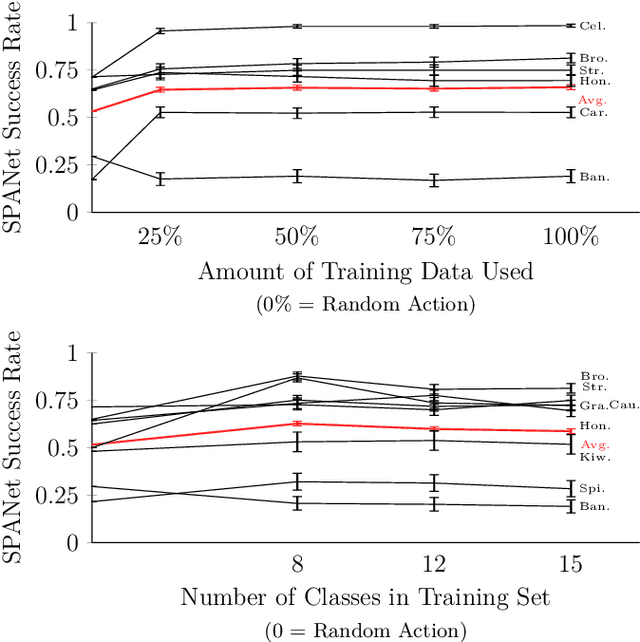
Successful robot-assisted feeding requires bite acquisition of a wide variety of food items. Different food items may require different manipulation actions for successful bite acquisition. Therefore, a key challenge is to handle previously-unseen food items with very different action distributions. By leveraging contexts from previous bite acquisition attempts, a robot should be able to learn online how to acquire those previously-unseen food items. We construct an online learning framework for this problem setting and use the $\epsilon$-greedy and LinUCB contextual bandit algorithms to minimize cumulative regret within that setting. Finally, we demonstrate empirically on a robot-assisted feeding system that this solution can adapt quickly to a food item with an action success rate distribution that differs greatly from previously-seen food items.
Imitation Learning as $f$-Divergence Minimization
May 30, 2019

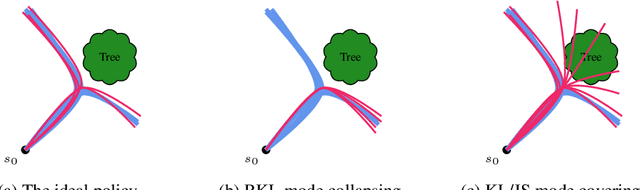
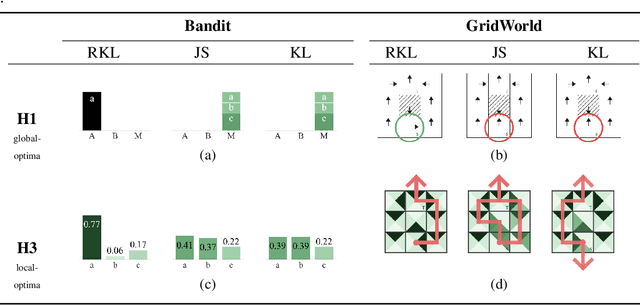
We address the problem of imitation learning with multi-modal demonstrations. Instead of attempting to learn all modes, we argue that in many tasks it is sufficient to imitate any one of them. We show that the state-of-the-art methods such as GAIL and behavior cloning, due to their choice of loss function, often incorrectly interpolate between such modes. Our key insight is to minimize the right divergence between the learner and the expert state-action distributions, namely the reverse KL divergence or I-projection. We propose a general imitation learning framework for estimating and minimizing any f-Divergence. By plugging in different divergences, we are able to recover existing algorithms such as Behavior Cloning (Kullback-Leibler), GAIL (Jensen Shannon) and Dagger (Total Variation). Empirical results show that our approximate I-projection technique is able to imitate multi-modal behaviors more reliably than GAIL and behavior cloning.
Dependency Leakage: Analysis and Scalable Estimators
Jul 18, 2018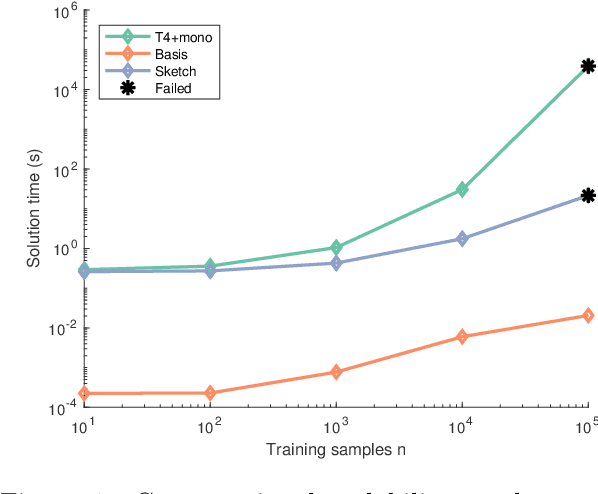
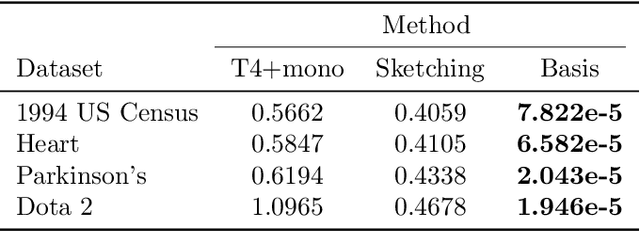
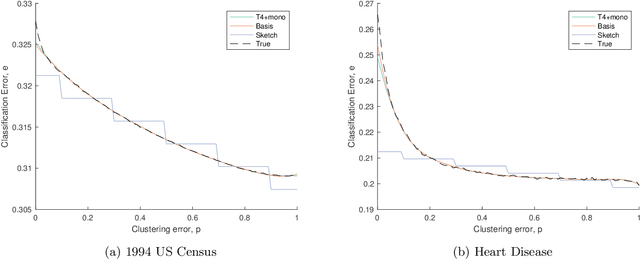
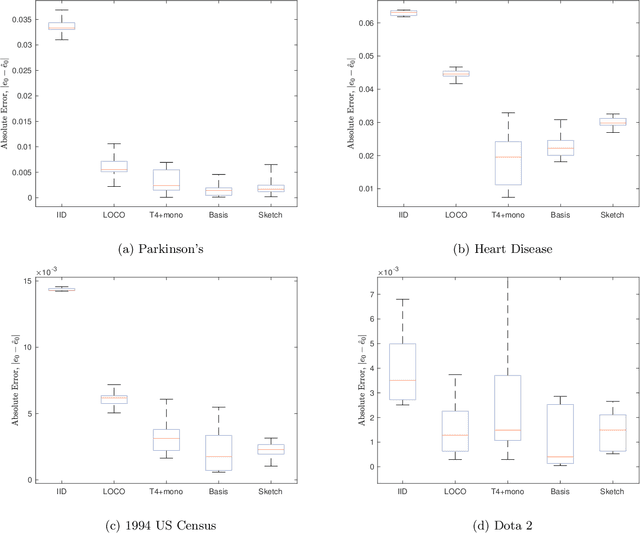
In this paper, we prove the first theoretical results on dependency leakage -- a phenomenon in which learning on noisy clusters biases cross-validation and model selection results. This is a major concern for domains involving human record databases (e.g. medical, census, advertising), which are almost always noisy due to the effects of record linkage and which require special attention to machine learning bias. The proposed theoretical properties justify regularization choices in several existing statistical estimators and allow us to construct the first hypothesis test for cross-validation bias due to dependency leakage. Furthermore, we propose a novel matrix sketching technique which, along with standard function approximation techniques, enables dramatically improving the sample and computational scalability of existing estimators. Empirical results on several benchmark datasets validate our theoretical results and proposed methods.
Performance Bounds for Graphical Record Linkage
Mar 08, 2017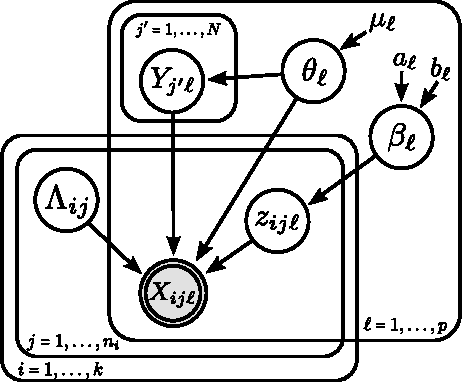

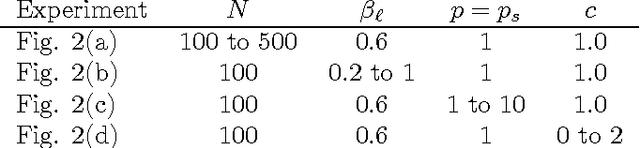

Record linkage involves merging records in large, noisy databases to remove duplicate entities. It has become an important area because of its widespread occurrence in bibliometrics, public health, official statistics production, political science, and beyond. Traditional linkage methods directly linking records to one another are computationally infeasible as the number of records grows. As a result, it is increasingly common for researchers to treat record linkage as a clustering task, in which each latent entity is associated with one or more noisy database records. We critically assess performance bounds using the Kullback-Leibler (KL) divergence under a Bayesian record linkage framework, making connections to Kolchin partition models. We provide an upper bound using the KL divergence and a lower bound on the minimum probability of misclassifying a latent entity. We give insights for when our bounds hold using simulated data and provide practical user guidance.
Clustering on the Edge: Learning Structure in Graphs
May 05, 2016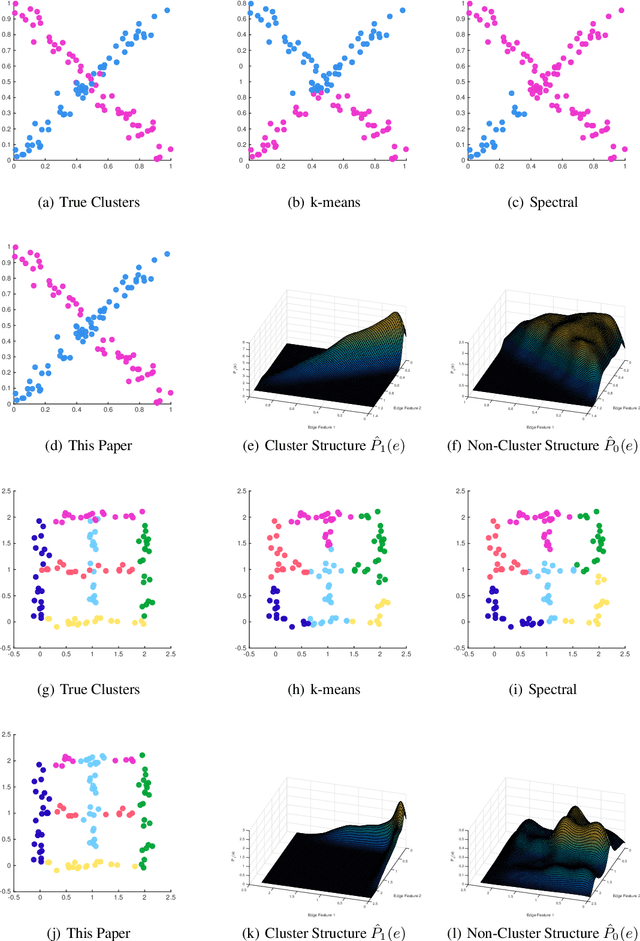
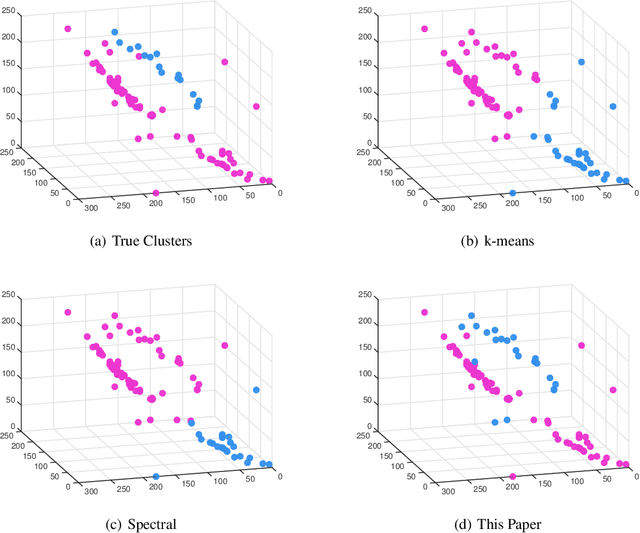
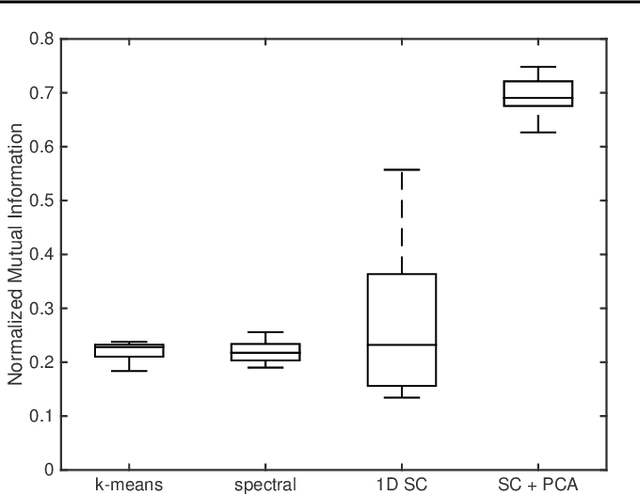
With the recent popularity of graphical clustering methods, there has been an increased focus on the information between samples. We show how learning cluster structure using edge features naturally and simultaneously determines the most likely number of clusters and addresses data scale issues. These results are particularly useful in instances where (a) there are a large number of clusters and (b) we have some labeled edges. Applications in this domain include image segmentation, community discovery and entity resolution. Our model is an extension of the planted partition model and our solution uses results of correlation clustering, which achieves a partition O(log(n))-close to the log-likelihood of the true clustering.