 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDependency Leakage: Analysis and Scalable Estimators
Paper and Code
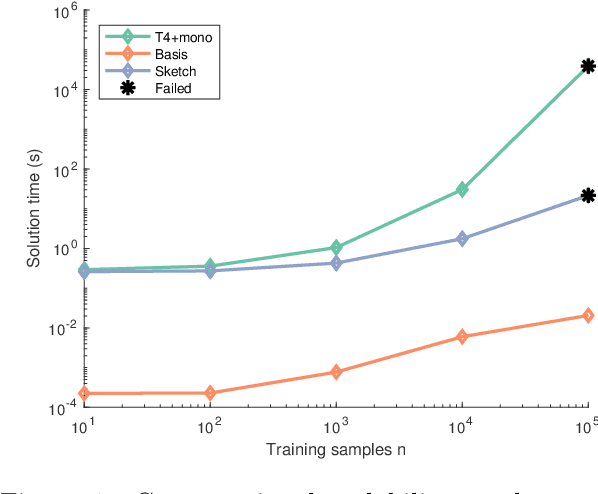
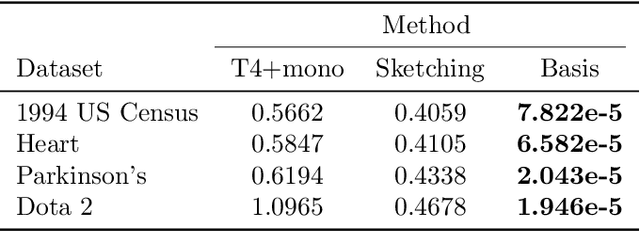
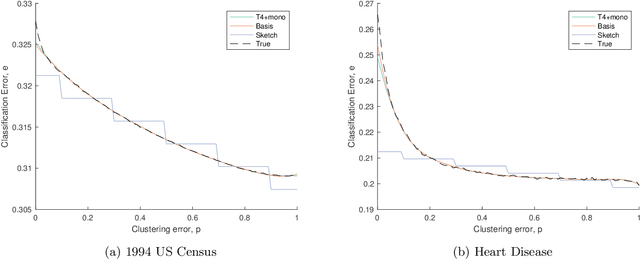
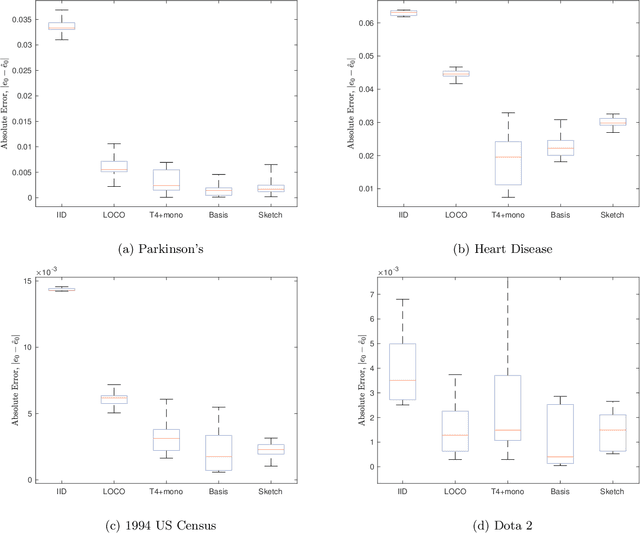
In this paper, we prove the first theoretical results on dependency leakage -- a phenomenon in which learning on noisy clusters biases cross-validation and model selection results. This is a major concern for domains involving human record databases (e.g. medical, census, advertising), which are almost always noisy due to the effects of record linkage and which require special attention to machine learning bias. The proposed theoretical properties justify regularization choices in several existing statistical estimators and allow us to construct the first hypothesis test for cross-validation bias due to dependency leakage. Furthermore, we propose a novel matrix sketching technique which, along with standard function approximation techniques, enables dramatically improving the sample and computational scalability of existing estimators. Empirical results on several benchmark datasets validate our theoretical results and proposed methods.