 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeliberation in Latent Space via Differentiable Cache Augmentation
Dec 23, 2024



Techniques enabling large language models (LLMs) to "think more" by generating and attending to intermediate reasoning steps have shown promise in solving complex problems. However, the standard approaches generate sequences of discrete tokens immediately before responding, and so they can incur significant latency costs and be challenging to optimize. In this work, we demonstrate that a frozen LLM can be augmented with an offline coprocessor that operates on the model's key-value (kv) cache. This coprocessor augments the cache with a set of latent embeddings designed to improve the fidelity of subsequent decoding. We train this coprocessor using the language modeling loss from the decoder on standard pretraining data, while keeping the decoder itself frozen. This approach enables the model to learn, in an end-to-end differentiable fashion, how to distill additional computation into its kv-cache. Because the decoder remains unchanged, the coprocessor can operate offline and asynchronously, and the language model can function normally if the coprocessor is unavailable or if a given cache is deemed not to require extra computation. We show experimentally that when a cache is augmented, the decoder achieves lower perplexity on numerous subsequent tokens. Furthermore, even without any task-specific training, our experiments demonstrate that cache augmentation consistently reduces perplexity and improves performance across a range of reasoning-intensive tasks.
One Communication Round is All It Needs for Federated Fine-Tuning Foundation Models
Dec 05, 2024
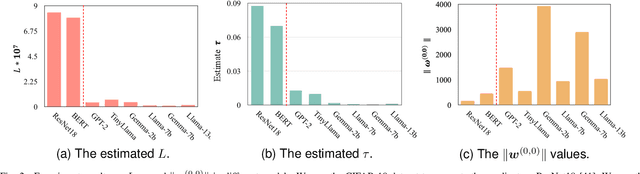

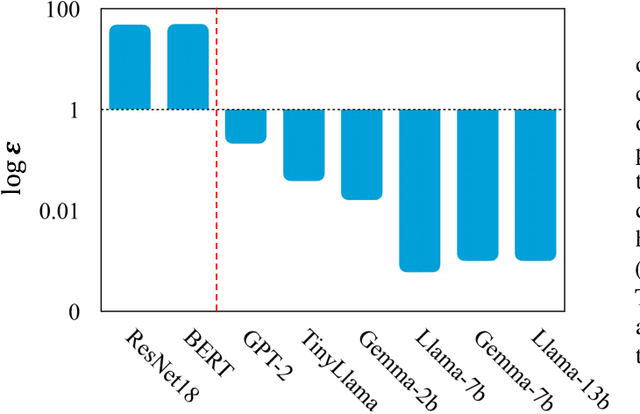
The recent advancement of large foundation models (FMs) has increased the demand for fine-tuning these models on large-scale and cross-domain datasets. To address this, federated fine-tuning has emerged as a solution, allowing models to be fine-tuned on distributed datasets across multiple devices while ensuring data privacy. However, the substantial parameter size of FMs and the multi-round communication required by traditional federated fine-tuning algorithms result in prohibitively high communication costs, challenging the practicality of federated fine-tuning. In this paper, we are the first to reveal, both theoretically and empirically, that the traditional multi-round aggregation algorithms may not be necessary for federated fine-tuning large FMs. Our experiments reveal that a single round of communication (i.e., one-shot federated fine-tuning) yields a global model performance comparable to that achieved through multiple rounds of communication. Through rigorous mathematical and empirical analyses, we demonstrate that large FMs, due to their extensive parameter sizes and pre-training on general tasks, achieve significantly lower training loss in one-shot federated fine-tuning compared to smaller models. Our extensive experiments show that one-shot federated fine-tuning not only reduces communication costs but also enables asynchronous aggregation, enhances privacy, and maintains performance consistency with multi-round federated fine-tuning for models larger than 1 billion parameters, on text generation and text-to-image generation tasks. Our findings have the potential to revolutionize federated fine-tuning in practice, enhancing efficiency, reducing costs, and expanding accessibility for large-scale models. This breakthrough paves the way for broader adoption and application of federated fine-tuning across various domains.
RLPF: Reinforcement Learning from Prediction Feedback for User Summarization with LLMs
Sep 06, 2024



LLM-powered personalization agent systems employ Large Language Models (LLMs) to predict users' behavior from their past activities. However, their effectiveness often hinges on the ability to effectively leverage extensive, long user historical data due to its inherent noise and length of such data. Existing pretrained LLMs may generate summaries that are concise but lack the necessary context for downstream tasks, hindering their utility in personalization systems. To address these challenges, we introduce Reinforcement Learning from Prediction Feedback (RLPF). RLPF fine-tunes LLMs to generate concise, human-readable user summaries that are optimized for downstream task performance. By maximizing the usefulness of the generated summaries, RLPF effectively distills extensive user history data while preserving essential information for downstream tasks. Our empirical evaluation demonstrates significant improvements in both extrinsic downstream task utility and intrinsic summary quality, surpassing baseline methods by up to 22% on downstream task performance and achieving an up to 84.59% win rate on Factuality, Abstractiveness, and Readability. RLPF also achieves a remarkable 74% reduction in context length while improving performance on 16 out of 19 unseen tasks and/or datasets, showcasing its generalizability. This approach offers a promising solution for enhancing LLM personalization by effectively transforming long, noisy user histories into informative and human-readable representations.
UserSumBench: A Benchmark Framework for Evaluating User Summarization Approaches
Aug 30, 2024



Large language models (LLMs) have shown remarkable capabilities in generating user summaries from a long list of raw user activity data. These summaries capture essential user information such as preferences and interests, and therefore are invaluable for LLM-based personalization applications, such as explainable recommender systems. However, the development of new summarization techniques is hindered by the lack of ground-truth labels, the inherent subjectivity of user summaries, and human evaluation which is often costly and time-consuming. To address these challenges, we introduce \UserSumBench, a benchmark framework designed to facilitate iterative development of LLM-based summarization approaches. This framework offers two key components: (1) A reference-free summary quality metric. We show that this metric is effective and aligned with human preferences across three diverse datasets (MovieLens, Yelp and Amazon Review). (2) A novel robust summarization method that leverages time-hierarchical summarizer and self-critique verifier to produce high-quality summaries while eliminating hallucination. This method serves as a strong baseline for further innovation in summarization techniques.
Capabilities of Gemini Models in Medicine
May 01, 2024



Excellence in a wide variety of medical applications poses considerable challenges for AI, requiring advanced reasoning, access to up-to-date medical knowledge and understanding of complex multimodal data. Gemini models, with strong general capabilities in multimodal and long-context reasoning, offer exciting possibilities in medicine. Building on these core strengths of Gemini, we introduce Med-Gemini, a family of highly capable multimodal models that are specialized in medicine with the ability to seamlessly use web search, and that can be efficiently tailored to novel modalities using custom encoders. We evaluate Med-Gemini on 14 medical benchmarks, establishing new state-of-the-art (SoTA) performance on 10 of them, and surpass the GPT-4 model family on every benchmark where a direct comparison is viable, often by a wide margin. On the popular MedQA (USMLE) benchmark, our best-performing Med-Gemini model achieves SoTA performance of 91.1% accuracy, using a novel uncertainty-guided search strategy. On 7 multimodal benchmarks including NEJM Image Challenges and MMMU (health & medicine), Med-Gemini improves over GPT-4V by an average relative margin of 44.5%. We demonstrate the effectiveness of Med-Gemini's long-context capabilities through SoTA performance on a needle-in-a-haystack retrieval task from long de-identified health records and medical video question answering, surpassing prior bespoke methods using only in-context learning. Finally, Med-Gemini's performance suggests real-world utility by surpassing human experts on tasks such as medical text summarization, alongside demonstrations of promising potential for multimodal medical dialogue, medical research and education. Taken together, our results offer compelling evidence for Med-Gemini's potential, although further rigorous evaluation will be crucial before real-world deployment in this safety-critical domain.
Augmentations vs Algorithms: What Works in Self-Supervised Learning
Mar 08, 2024



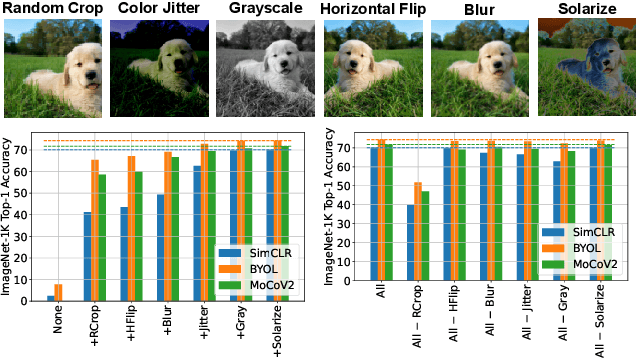
We study the relative effects of data augmentations, pretraining algorithms, and model architectures in Self-Supervised Learning (SSL). While the recent literature in this space leaves the impression that the pretraining algorithm is of critical importance to performance, understanding its effect is complicated by the difficulty in making objective and direct comparisons between methods. We propose a new framework which unifies many seemingly disparate SSL methods into a single shared template. Using this framework, we identify aspects in which methods differ and observe that in addition to changing the pretraining algorithm, many works also use new data augmentations or more powerful model architectures. We compare several popular SSL methods using our framework and find that many algorithmic additions, such as prediction networks or new losses, have a minor impact on downstream task performance (often less than $1\%$), while enhanced augmentation techniques offer more significant performance improvements ($2-4\%$). Our findings challenge the premise that SSL is being driven primarily by algorithmic improvements, and suggest instead a bitter lesson for SSL: that augmentation diversity and data / model scale are more critical contributors to recent advances in self-supervised learning.
User-LLM: Efficient LLM Contextualization with User Embeddings
Feb 21, 2024Large language models (LLMs) have revolutionized natural language processing. However, effectively incorporating complex and potentially noisy user interaction data remains a challenge. To address this, we propose User-LLM, a novel framework that leverages user embeddings to contextualize LLMs. These embeddings, distilled from diverse user interactions using self-supervised pretraining, capture latent user preferences and their evolution over time. We integrate these user embeddings with LLMs through cross-attention and soft-prompting, enabling LLMs to dynamically adapt to user context. Our comprehensive experiments on MovieLens, Amazon Review, and Google Local Review datasets demonstrate significant performance gains across various tasks. Notably, our approach outperforms text-prompt-based contextualization on long sequence tasks and tasks that require deep user understanding while being computationally efficient. We further incorporate Perceiver layers to streamline the integration between user encoders and LLMs, reducing computational demands.
Heterogeneous Low-Rank Approximation for Federated Fine-tuning of On-Device Foundation Models
Jan 12, 2024Large foundation models (FMs) adapt surprisingly well to specific domains or tasks with fine-tuning. Federated learning (FL) further enables private FM fine-tuning using the local data on devices. However, the standard FMs' large size poses challenges for resource-constrained and heterogeneous devices. To address this, we consider FMs with reduced parameter sizes, referred to as on-device FMs (ODFMs). While ODFMs allow on-device inference, computational constraints still hinder efficient federated fine-tuning. We propose a parameter-efficient federated fine-tuning method for ODFMs using heterogeneous low-rank approximations (LoRAs) that addresses system and data heterogeneity. We show that homogeneous LoRA ranks face a trade-off between overfitting and slow convergence, and propose HetLoRA, which employs heterogeneous ranks across clients and eliminates the shortcomings of homogeneous HetLoRA. By applying rank self-pruning locally and sparsity-weighted aggregation at the server, we combine the advantages of high and low-rank LoRAs, which achieves improved convergence speed and final performance compared to homogeneous LoRA. Furthermore, it offers enhanced computation efficiency compared to full fine-tuning, making it suitable for heterogeneous devices while preserving data privacy.
GLOCALFAIR: Jointly Improving Global and Local Group Fairness in Federated Learning
Jan 07, 2024



Federated learning (FL) has emerged as a prospective solution for collaboratively learning a shared model across clients without sacrificing their data privacy. However, the federated learned model tends to be biased against certain demographic groups (e.g., racial and gender groups) due to the inherent FL properties, such as data heterogeneity and party selection. Unlike centralized learning, mitigating bias in FL is particularly challenging as private training datasets and their sensitive attributes are typically not directly accessible. Most prior research in this field only focuses on global fairness while overlooking the local fairness of individual clients. Moreover, existing methods often require sensitive information about the client's local datasets to be shared, which is not desirable. To address these issues, we propose GLOCALFAIR, a client-server co-design fairness framework that can jointly improve global and local group fairness in FL without the need for sensitive statistics about the client's private datasets. Specifically, we utilize constrained optimization to enforce local fairness on the client side and adopt a fairness-aware clustering-based aggregation on the server to further ensure the global model fairness across different sensitive groups while maintaining high utility. Experiments on two image datasets and one tabular dataset with various state-of-the-art fairness baselines show that GLOCALFAIR can achieve enhanced fairness under both global and local data distributions while maintaining a good level of utility and client fairness.
Disentangling the Effects of Data Augmentation and Format Transform in Self-Supervised Learning of Image Representations
Dec 02, 2023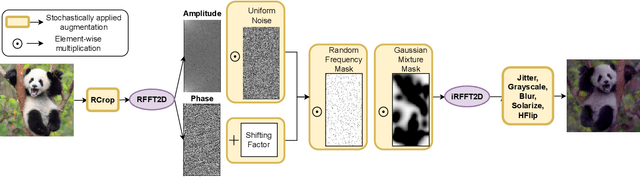

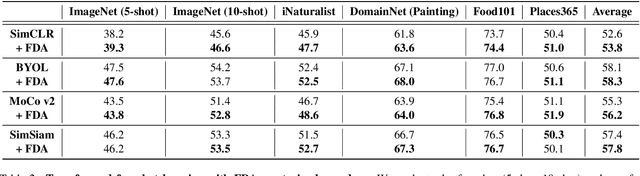
Self-Supervised Learning (SSL) enables training performant models using limited labeled data. One of the pillars underlying vision SSL is the use of data augmentations/perturbations of the input which do not significantly alter its semantic content. For audio and other temporal signals, augmentations are commonly used alongside format transforms such as Fourier transforms or wavelet transforms. Unlike augmentations, format transforms do not change the information contained in the data; rather, they express the same information in different coordinates. In this paper, we study the effects of format transforms and augmentations both separately and together on vision SSL. We define augmentations in frequency space called Fourier Domain Augmentations (FDA) and show that training SSL models on a combination of these and image augmentations can improve the downstream classification accuracy by up to 1.3% on ImageNet-1K. We also show improvements against SSL baselines in few-shot and transfer learning setups using FDA. Surprisingly, we also observe that format transforms can improve the quality of learned representations even without augmentations; however, the combination of the two techniques yields better quality.