 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling the Effects of Data Augmentation and Format Transform in Self-Supervised Learning of Image Representations
Paper and Code
Dec 02, 2023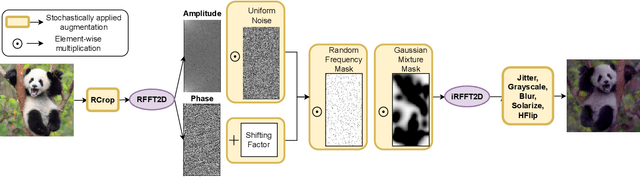

Self-Supervised Learning (SSL) enables training performant models using limited labeled data. One of the pillars underlying vision SSL is the use of data augmentations/perturbations of the input which do not significantly alter its semantic content. For audio and other temporal signals, augmentations are commonly used alongside format transforms such as Fourier transforms or wavelet transforms. Unlike augmentations, format transforms do not change the information contained in the data; rather, they express the same information in different coordinates. In this paper, we study the effects of format transforms and augmentations both separately and together on vision SSL. We define augmentations in frequency space called Fourier Domain Augmentations (FDA) and show that training SSL models on a combination of these and image augmentations can improve the downstream classification accuracy by up to 1.3% on ImageNet-1K. We also show improvements against SSL baselines in few-shot and transfer learning setups using FDA. Surprisingly, we also observe that format transforms can improve the quality of learned representations even without augmentations; however, the combination of the two techniques yields better quality.