 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
AI-based Clinical Decision Support for Primary Care: A Real-World Study
Jul 22, 2025We evaluate the impact of large language model-based clinical decision support in live care. In partnership with Penda Health, a network of primary care clinics in Nairobi, Kenya, we studied AI Consult, a tool that serves as a safety net for clinicians by identifying potential documentation and clinical decision-making errors. AI Consult integrates into clinician workflows, activating only when needed and preserving clinician autonomy. We conducted a quality improvement study, comparing outcomes for 39,849 patient visits performed by clinicians with or without access to AI Consult across 15 clinics. Visits were rated by independent physicians to identify clinical errors. Clinicians with access to AI Consult made relatively fewer errors: 16% fewer diagnostic errors and 13% fewer treatment errors. In absolute terms, the introduction of AI Consult would avert diagnostic errors in 22,000 visits and treatment errors in 29,000 visits annually at Penda alone. In a survey of clinicians with AI Consult, all clinicians said that AI Consult improved the quality of care they delivered, with 75% saying the effect was "substantial". These results required a clinical workflow-aligned AI Consult implementation and active deployment to encourage clinician uptake. We hope this study demonstrates the potential for LLM-based clinical decision support tools to reduce errors in real-world settings and provides a practical framework for advancing responsible adoption.
HealthBench: Evaluating Large Language Models Towards Improved Human Health
May 13, 2025



We present HealthBench, an open-source benchmark measuring the performance and safety of large language models in healthcare. HealthBench consists of 5,000 multi-turn conversations between a model and an individual user or healthcare professional. Responses are evaluated using conversation-specific rubrics created by 262 physicians. Unlike previous multiple-choice or short-answer benchmarks, HealthBench enables realistic, open-ended evaluation through 48,562 unique rubric criteria spanning several health contexts (e.g., emergencies, transforming clinical data, global health) and behavioral dimensions (e.g., accuracy, instruction following, communication). HealthBench performance over the last two years reflects steady initial progress (compare GPT-3.5 Turbo's 16% to GPT-4o's 32%) and more rapid recent improvements (o3 scores 60%). Smaller models have especially improved: GPT-4.1 nano outperforms GPT-4o and is 25 times cheaper. We additionally release two HealthBench variations: HealthBench Consensus, which includes 34 particularly important dimensions of model behavior validated via physician consensus, and HealthBench Hard, where the current top score is 32%. We hope that HealthBench grounds progress towards model development and applications that benefit human health.
Enhancing User Sequence Modeling through Barlow Twins-based Self-Supervised Learning
May 02, 2025
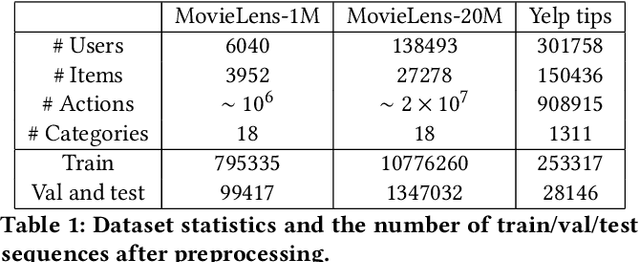


User sequence modeling is crucial for modern large-scale recommendation systems, as it enables the extraction of informative representations of users and items from their historical interactions. These user representations are widely used for a variety of downstream tasks to enhance users' online experience. A key challenge for learning these representations is the lack of labeled training data. While self-supervised learning (SSL) methods have emerged as a promising solution for learning representations from unlabeled data, many existing approaches rely on extensive negative sampling, which can be computationally expensive and may not always be feasible in real-world scenario. In this work, we propose an adaptation of Barlow Twins, a state-of-the-art SSL methods, to user sequence modeling by incorporating suitable augmentation methods. Our approach aims to mitigate the need for large negative sample batches, enabling effective representation learning with smaller batch sizes and limited labeled data. We evaluate our method on the MovieLens-1M, MovieLens-20M, and Yelp datasets, demonstrating that our method consistently outperforms the widely-used dual encoder model across three downstream tasks, achieving an 8%-20% improvement in accuracy. Our findings underscore the effectiveness of our approach in extracting valuable sequence-level information for user modeling, particularly in scenarios where labeled data is scarce and negative examples are limited.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
A Toolbox for Surfacing Health Equity Harms and Biases in Large Language Models
Mar 18, 2024Large language models (LLMs) hold immense promise to serve complex health information needs but also have the potential to introduce harm and exacerbate health disparities. Reliably evaluating equity-related model failures is a critical step toward developing systems that promote health equity. In this work, we present resources and methodologies for surfacing biases with potential to precipitate equity-related harms in long-form, LLM-generated answers to medical questions and then conduct an empirical case study with Med-PaLM 2, resulting in the largest human evaluation study in this area to date. Our contributions include a multifactorial framework for human assessment of LLM-generated answers for biases, and EquityMedQA, a collection of seven newly-released datasets comprising both manually-curated and LLM-generated questions enriched for adversarial queries. Both our human assessment framework and dataset design process are grounded in an iterative participatory approach and review of possible biases in Med-PaLM 2 answers to adversarial queries. Through our empirical study, we find that the use of a collection of datasets curated through a variety of methodologies, coupled with a thorough evaluation protocol that leverages multiple assessment rubric designs and diverse rater groups, surfaces biases that may be missed via narrower evaluation approaches. Our experience underscores the importance of using diverse assessment methodologies and involving raters of varying backgrounds and expertise. We emphasize that while our framework can identify specific forms of bias, it is not sufficient to holistically assess whether the deployment of an AI system promotes equitable health outcomes. We hope the broader community leverages and builds on these tools and methods towards realizing a shared goal of LLMs that promote accessible and equitable healthcare for all.
Augmentations vs Algorithms: What Works in Self-Supervised Learning
Mar 08, 2024



We study the relative effects of data augmentations, pretraining algorithms, and model architectures in Self-Supervised Learning (SSL). While the recent literature in this space leaves the impression that the pretraining algorithm is of critical importance to performance, understanding its effect is complicated by the difficulty in making objective and direct comparisons between methods. We propose a new framework which unifies many seemingly disparate SSL methods into a single shared template. Using this framework, we identify aspects in which methods differ and observe that in addition to changing the pretraining algorithm, many works also use new data augmentations or more powerful model architectures. We compare several popular SSL methods using our framework and find that many algorithmic additions, such as prediction networks or new losses, have a minor impact on downstream task performance (often less than $1\%$), while enhanced augmentation techniques offer more significant performance improvements ($2-4\%$). Our findings challenge the premise that SSL is being driven primarily by algorithmic improvements, and suggest instead a bitter lesson for SSL: that augmentation diversity and data / model scale are more critical contributors to recent advances in self-supervised learning.
Towards Conversational Diagnostic AI
Jan 11, 2024At the heart of medicine lies the physician-patient dialogue, where skillful history-taking paves the way for accurate diagnosis, effective management, and enduring trust. Artificial Intelligence (AI) systems capable of diagnostic dialogue could increase accessibility, consistency, and quality of care. However, approximating clinicians' expertise is an outstanding grand challenge. Here, we introduce AMIE (Articulate Medical Intelligence Explorer), a Large Language Model (LLM) based AI system optimized for diagnostic dialogue. AMIE uses a novel self-play based simulated environment with automated feedback mechanisms for scaling learning across diverse disease conditions, specialties, and contexts. We designed a framework for evaluating clinically-meaningful axes of performance including history-taking, diagnostic accuracy, management reasoning, communication skills, and empathy. We compared AMIE's performance to that of primary care physicians (PCPs) in a randomized, double-blind crossover study of text-based consultations with validated patient actors in the style of an Objective Structured Clinical Examination (OSCE). The study included 149 case scenarios from clinical providers in Canada, the UK, and India, 20 PCPs for comparison with AMIE, and evaluations by specialist physicians and patient actors. AMIE demonstrated greater diagnostic accuracy and superior performance on 28 of 32 axes according to specialist physicians and 24 of 26 axes according to patient actors. Our research has several limitations and should be interpreted with appropriate caution. Clinicians were limited to unfamiliar synchronous text-chat which permits large-scale LLM-patient interactions but is not representative of usual clinical practice. While further research is required before AMIE could be translated to real-world settings, the results represent a milestone towards conversational diagnostic AI.
Consensus, dissensus and synergy between clinicians and specialist foundation models in radiology report generation
Dec 06, 2023
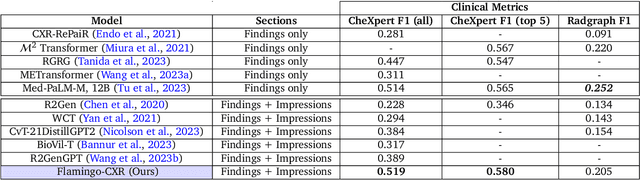
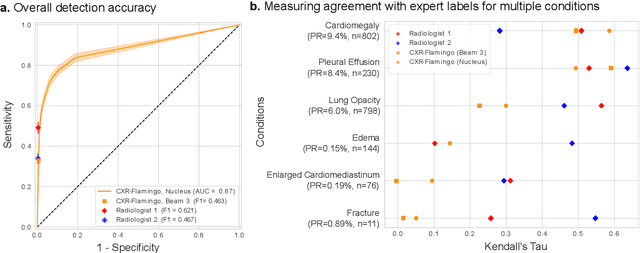
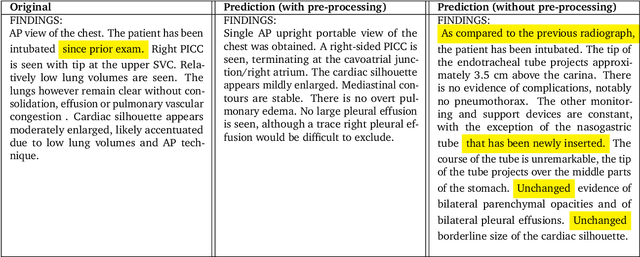
Radiology reports are an instrumental part of modern medicine, informing key clinical decisions such as diagnosis and treatment. The worldwide shortage of radiologists, however, restricts access to expert care and imposes heavy workloads, contributing to avoidable errors and delays in report delivery. While recent progress in automated report generation with vision-language models offer clear potential in ameliorating the situation, the path to real-world adoption has been stymied by the challenge of evaluating the clinical quality of AI-generated reports. In this study, we build a state-of-the-art report generation system for chest radiographs, \textit{Flamingo-CXR}, by fine-tuning a well-known vision-language foundation model on radiology data. To evaluate the quality of the AI-generated reports, a group of 16 certified radiologists provide detailed evaluations of AI-generated and human written reports for chest X-rays from an intensive care setting in the United States and an inpatient setting in India. At least one radiologist (out of two per case) preferred the AI report to the ground truth report in over 60$\%$ of cases for both datasets. Amongst the subset of AI-generated reports that contain errors, the most frequently cited reasons were related to the location and finding, whereas for human written reports, most mistakes were related to severity and finding. This disparity suggested potential complementarity between our AI system and human experts, prompting us to develop an assistive scenario in which \textit{Flamingo-CXR} generates a first-draft report, which is subsequently revised by a clinician. This is the first demonstration of clinician-AI collaboration for report writing, and the resultant reports are assessed to be equivalent or preferred by at least one radiologist to reports written by experts alone in 80$\%$ of in-patient cases and 60$\%$ of intensive care cases.