 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling laws in wearable human activity recognition
Feb 05, 2025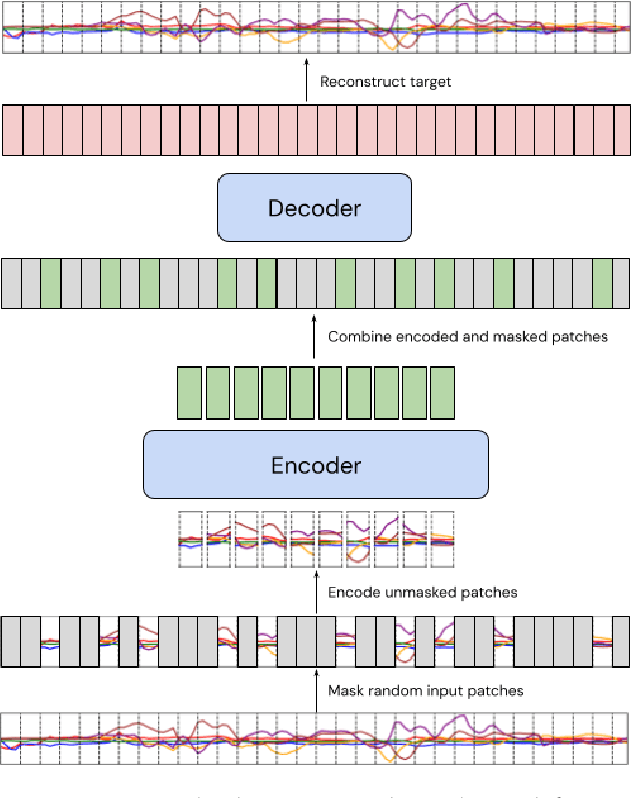
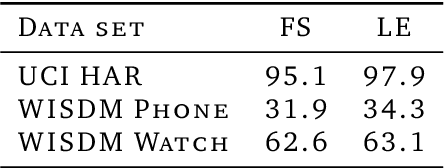
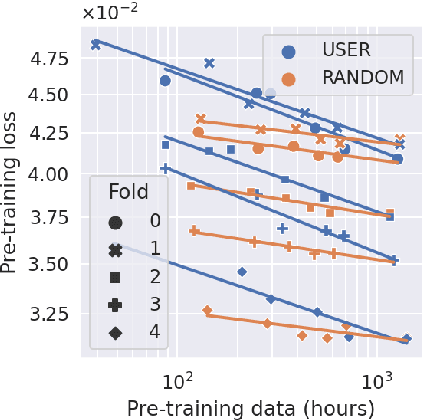
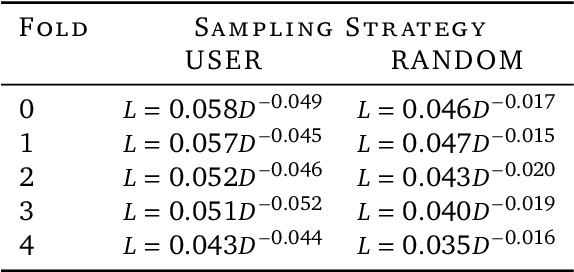
Many deep architectures and self-supervised pre-training techniques have been proposed for human activity recognition (HAR) from wearable multimodal sensors. Scaling laws have the potential to help move towards more principled design by linking model capacity with pre-training data volume. Yet, scaling laws have not been established for HAR to the same extent as in language and vision. By conducting an exhaustive grid search on both amount of pre-training data and Transformer architectures, we establish the first known scaling laws for HAR. We show that pre-training loss scales with a power law relationship to amount of data and parameter count and that increasing the number of users in a dataset results in a steeper improvement in performance than increasing data per user, indicating that diversity of pre-training data is important, which contrasts to some previously reported findings in self-supervised HAR. We show that these scaling laws translate to downstream performance improvements on three HAR benchmark datasets of postures, modes of locomotion and activities of daily living: UCI HAR and WISDM Phone and WISDM Watch. Finally, we suggest some previously published works should be revisited in light of these scaling laws with more adequate model capacities.
Augmentations vs Algorithms: What Works in Self-Supervised Learning
Mar 08, 2024



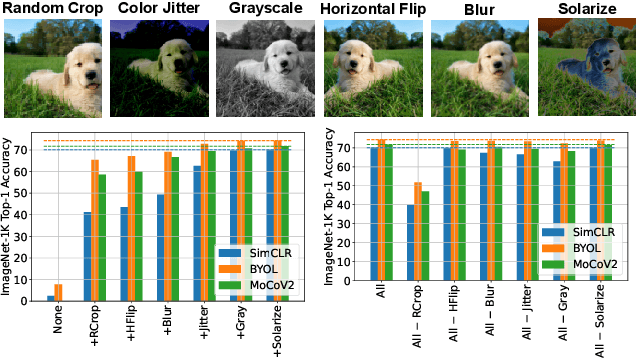
We study the relative effects of data augmentations, pretraining algorithms, and model architectures in Self-Supervised Learning (SSL). While the recent literature in this space leaves the impression that the pretraining algorithm is of critical importance to performance, understanding its effect is complicated by the difficulty in making objective and direct comparisons between methods. We propose a new framework which unifies many seemingly disparate SSL methods into a single shared template. Using this framework, we identify aspects in which methods differ and observe that in addition to changing the pretraining algorithm, many works also use new data augmentations or more powerful model architectures. We compare several popular SSL methods using our framework and find that many algorithmic additions, such as prediction networks or new losses, have a minor impact on downstream task performance (often less than $1\%$), while enhanced augmentation techniques offer more significant performance improvements ($2-4\%$). Our findings challenge the premise that SSL is being driven primarily by algorithmic improvements, and suggest instead a bitter lesson for SSL: that augmentation diversity and data / model scale are more critical contributors to recent advances in self-supervised learning.
SASSL: Enhancing Self-Supervised Learning via Neural Style Transfer
Dec 02, 2023



Self-supervised learning relies heavily on data augmentation to extract meaningful representations from unlabeled images. While existing state-of-the-art augmentation pipelines incorporate a wide range of primitive transformations, these often disregard natural image structure. Thus, augmented samples can exhibit degraded semantic information and low stylistic diversity, affecting downstream performance of self-supervised representations. To overcome this, we propose SASSL: Style Augmentations for Self Supervised Learning, a novel augmentation technique based on Neural Style Transfer. The method decouples semantic and stylistic attributes in images and applies transformations exclusively to the style while preserving content, generating diverse augmented samples that better retain their semantic properties. Experimental results show our technique achieves a top-1 classification performance improvement of more than 2% on ImageNet compared to the well-established MoCo v2. We also measure transfer learning performance across five diverse datasets, observing significant improvements of up to 3.75%. Our experiments indicate that decoupling style from content information and transferring style across datasets to diversify augmentations can significantly improve downstream performance of self-supervised representations.
Disentangling the Effects of Data Augmentation and Format Transform in Self-Supervised Learning of Image Representations
Dec 02, 2023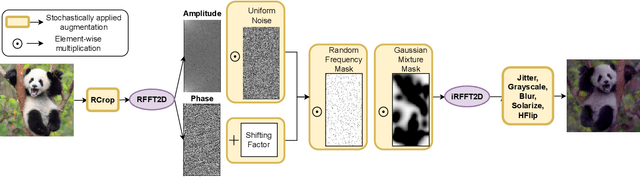

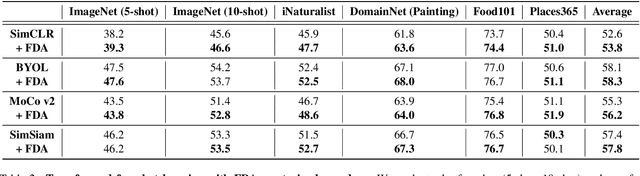
Self-Supervised Learning (SSL) enables training performant models using limited labeled data. One of the pillars underlying vision SSL is the use of data augmentations/perturbations of the input which do not significantly alter its semantic content. For audio and other temporal signals, augmentations are commonly used alongside format transforms such as Fourier transforms or wavelet transforms. Unlike augmentations, format transforms do not change the information contained in the data; rather, they express the same information in different coordinates. In this paper, we study the effects of format transforms and augmentations both separately and together on vision SSL. We define augmentations in frequency space called Fourier Domain Augmentations (FDA) and show that training SSL models on a combination of these and image augmentations can improve the downstream classification accuracy by up to 1.3% on ImageNet-1K. We also show improvements against SSL baselines in few-shot and transfer learning setups using FDA. Surprisingly, we also observe that format transforms can improve the quality of learned representations even without augmentations; however, the combination of the two techniques yields better quality.