 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting and Controlling Model Behavior via Constitutions for Atomic Concept Edits
Jan 23, 2026We introduce a black-box interpretability framework that learns a verifiable constitution: a natural language summary of how changes to a prompt affect a model's specific behavior, such as its alignment, correctness, or adherence to constraints. Our method leverages atomic concept edits (ACEs), which are targeted operations that add, remove, or replace an interpretable concept in the input prompt. By systematically applying ACEs and observing the resulting effects on model behavior across various tasks, our framework learns a causal mapping from edits to predictable outcomes. This learned constitution provides deep, generalizable insights into the model. Empirically, we validate our approach across diverse tasks, including mathematical reasoning and text-to-image alignment, for controlling and understanding model behavior. We found that for text-to-image generation, GPT-Image tends to focus on grammatical adherence, while Imagen 4 prioritizes atmospheric coherence. In mathematical reasoning, distractor variables confuse GPT-5 but leave Gemini 2.5 models and o4-mini largely unaffected. Moreover, our results show that the learned constitutions are highly effective for controlling model behavior, achieving an average of 1.86 times boost in success rate over methods that do not use constitutions.
Understanding the Effect of using Semantically Meaningful Tokens for Visual Representation Learning
May 26, 2024



Vision transformers have established a precedent of patchifying images into uniformly-sized chunks before processing. We hypothesize that this design choice may limit models in learning comprehensive and compositional representations from visual data. This paper explores the notion of providing semantically-meaningful visual tokens to transformer encoders within a vision-language pre-training framework. Leveraging off-the-shelf segmentation and scene-graph models, we extract representations of instance segmentation masks (referred to as tangible tokens) and relationships and actions (referred to as intangible tokens). Subsequently, we pre-train a vision-side transformer by incorporating these newly extracted tokens and aligning the resultant embeddings with caption embeddings from a text-side encoder. To capture the structural and semantic relationships among visual tokens, we introduce additive attention weights, which are used to compute self-attention scores. Our experiments on COCO demonstrate notable improvements over ViTs in learned representation quality across text-to-image (+47%) and image-to-text retrieval (+44%) tasks. Furthermore, we showcase the advantages on compositionality benchmarks such as ARO (+18%) and Winoground (+10%).
Augmentations vs Algorithms: What Works in Self-Supervised Learning
Mar 08, 2024



We study the relative effects of data augmentations, pretraining algorithms, and model architectures in Self-Supervised Learning (SSL). While the recent literature in this space leaves the impression that the pretraining algorithm is of critical importance to performance, understanding its effect is complicated by the difficulty in making objective and direct comparisons between methods. We propose a new framework which unifies many seemingly disparate SSL methods into a single shared template. Using this framework, we identify aspects in which methods differ and observe that in addition to changing the pretraining algorithm, many works also use new data augmentations or more powerful model architectures. We compare several popular SSL methods using our framework and find that many algorithmic additions, such as prediction networks or new losses, have a minor impact on downstream task performance (often less than $1\%$), while enhanced augmentation techniques offer more significant performance improvements ($2-4\%$). Our findings challenge the premise that SSL is being driven primarily by algorithmic improvements, and suggest instead a bitter lesson for SSL: that augmentation diversity and data / model scale are more critical contributors to recent advances in self-supervised learning.
Disentangling the Effects of Data Augmentation and Format Transform in Self-Supervised Learning of Image Representations
Dec 02, 2023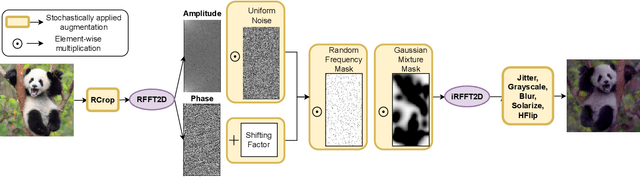

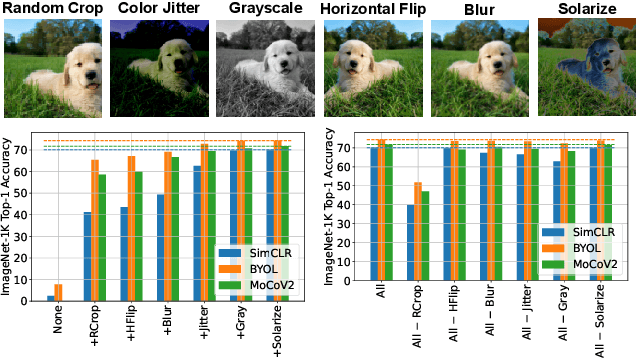
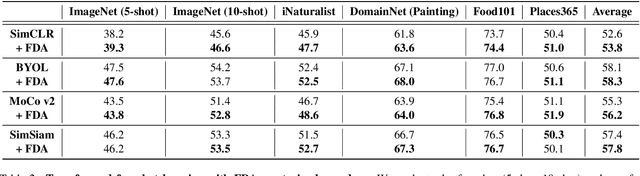
Self-Supervised Learning (SSL) enables training performant models using limited labeled data. One of the pillars underlying vision SSL is the use of data augmentations/perturbations of the input which do not significantly alter its semantic content. For audio and other temporal signals, augmentations are commonly used alongside format transforms such as Fourier transforms or wavelet transforms. Unlike augmentations, format transforms do not change the information contained in the data; rather, they express the same information in different coordinates. In this paper, we study the effects of format transforms and augmentations both separately and together on vision SSL. We define augmentations in frequency space called Fourier Domain Augmentations (FDA) and show that training SSL models on a combination of these and image augmentations can improve the downstream classification accuracy by up to 1.3% on ImageNet-1K. We also show improvements against SSL baselines in few-shot and transfer learning setups using FDA. Surprisingly, we also observe that format transforms can improve the quality of learned representations even without augmentations; however, the combination of the two techniques yields better quality.
Adapting Self-Supervised Representations to Multi-Domain Setups
Sep 07, 2023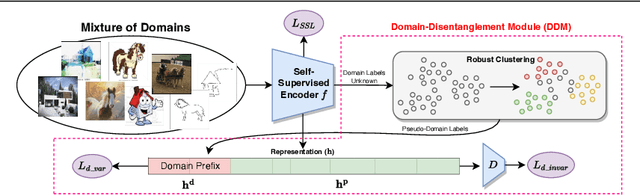
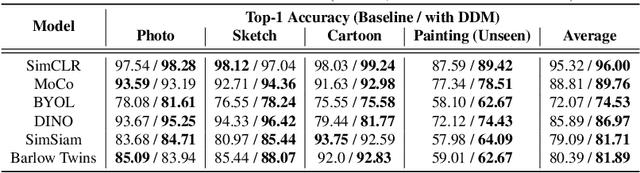
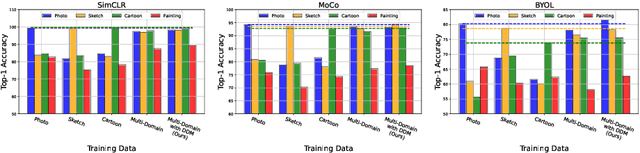

Current state-of-the-art self-supervised approaches, are effective when trained on individual domains but show limited generalization on unseen domains. We observe that these models poorly generalize even when trained on a mixture of domains, making them unsuitable to be deployed under diverse real-world setups. We therefore propose a general-purpose, lightweight Domain Disentanglement Module (DDM) that can be plugged into any self-supervised encoder to effectively perform representation learning on multiple, diverse domains with or without shared classes. During pre-training according to a self-supervised loss, DDM enforces a disentanglement in the representation space by splitting it into a domain-variant and a domain-invariant portion. When domain labels are not available, DDM uses a robust clustering approach to discover pseudo-domains. We show that pre-training with DDM can show up to 3.5% improvement in linear probing accuracy on state-of-the-art self-supervised models including SimCLR, MoCo, BYOL, DINO, SimSiam and Barlow Twins on multi-domain benchmarks including PACS, DomainNet and WILDS. Models trained with DDM show significantly improved generalization (7.4%) to unseen domains compared to baselines. Therefore, DDM can efficiently adapt self-supervised encoders to provide high-quality, generalizable representations for diverse multi-domain data.
Identifying Interpretable Subspaces in Image Representations
Jul 20, 2023We propose Automatic Feature Explanation using Contrasting Concepts (FALCON), an interpretability framework to explain features of image representations. For a target feature, FALCON captions its highly activating cropped images using a large captioning dataset (like LAION-400m) and a pre-trained vision-language model like CLIP. Each word among the captions is scored and ranked leading to a small number of shared, human-understandable concepts that closely describe the target feature. FALCON also applies contrastive interpretation using lowly activating (counterfactual) images, to eliminate spurious concepts. Although many existing approaches interpret features independently, we observe in state-of-the-art self-supervised and supervised models, that less than 20% of the representation space can be explained by individual features. We show that features in larger spaces become more interpretable when studied in groups and can be explained with high-order scoring concepts through FALCON. We discuss how extracted concepts can be used to explain and debug failures in downstream tasks. Finally, we present a technique to transfer concepts from one (explainable) representation space to another unseen representation space by learning a simple linear transformation.