 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Self-Supervised Representations to Multi-Domain Setups
Sep 07, 2023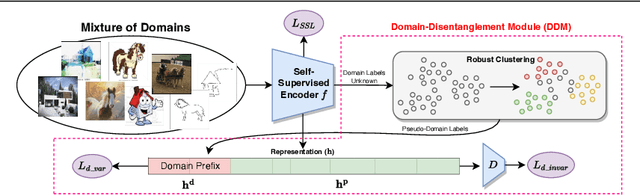
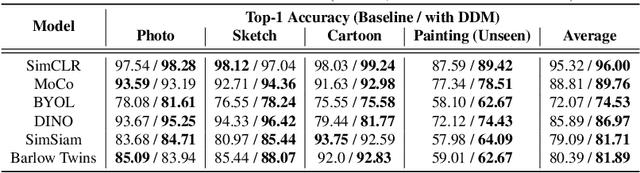
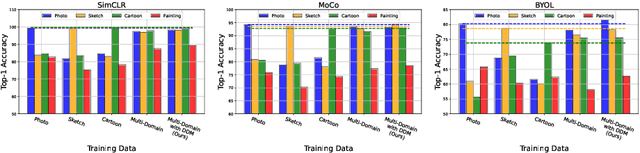

Current state-of-the-art self-supervised approaches, are effective when trained on individual domains but show limited generalization on unseen domains. We observe that these models poorly generalize even when trained on a mixture of domains, making them unsuitable to be deployed under diverse real-world setups. We therefore propose a general-purpose, lightweight Domain Disentanglement Module (DDM) that can be plugged into any self-supervised encoder to effectively perform representation learning on multiple, diverse domains with or without shared classes. During pre-training according to a self-supervised loss, DDM enforces a disentanglement in the representation space by splitting it into a domain-variant and a domain-invariant portion. When domain labels are not available, DDM uses a robust clustering approach to discover pseudo-domains. We show that pre-training with DDM can show up to 3.5% improvement in linear probing accuracy on state-of-the-art self-supervised models including SimCLR, MoCo, BYOL, DINO, SimSiam and Barlow Twins on multi-domain benchmarks including PACS, DomainNet and WILDS. Models trained with DDM show significantly improved generalization (7.4%) to unseen domains compared to baselines. Therefore, DDM can efficiently adapt self-supervised encoders to provide high-quality, generalizable representations for diverse multi-domain data.
Sensitive Data Detection with High-Throughput Neural Network Models for Financial Institutions
Dec 17, 2020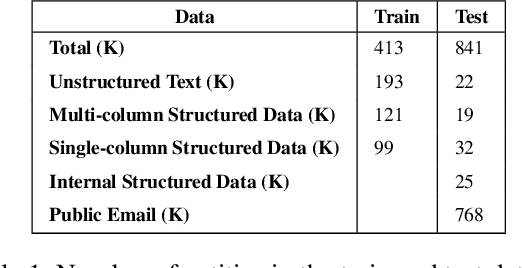
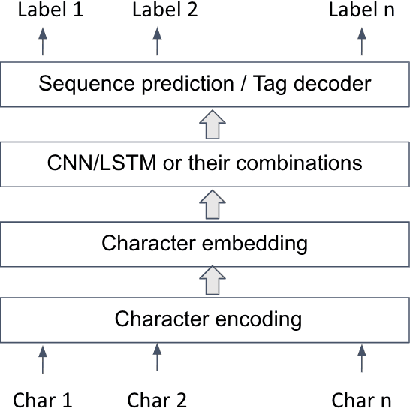
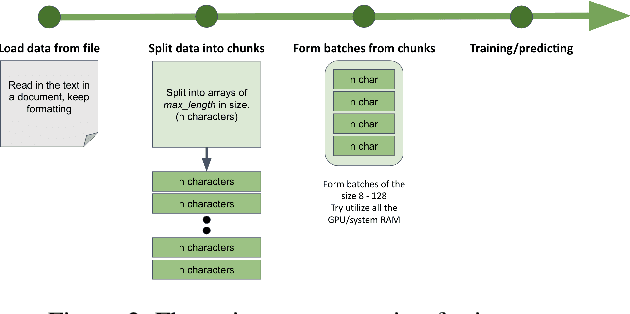
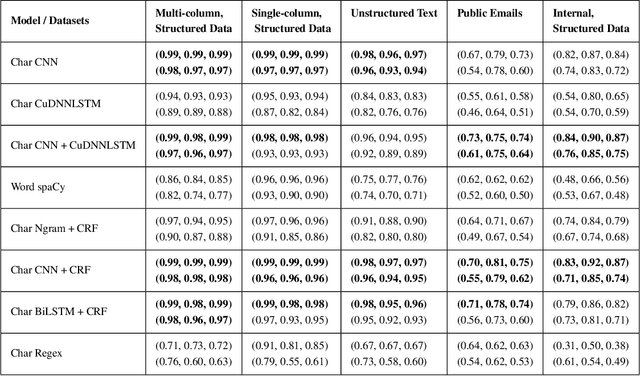
Named Entity Recognition has been extensively investigated in many fields. However, the application of sensitive entity detection for production systems in financial institutions has not been well explored due to the lack of publicly available, labeled datasets. In this paper, we use internal and synthetic datasets to evaluate various methods of detecting NPI (Nonpublic Personally Identifiable) information commonly found within financial institutions, in both unstructured and structured data formats. Character-level neural network models including CNN, LSTM, BiLSTM-CRF, and CNN-CRF are investigated on two prediction tasks: (i) entity detection on multiple data formats, and (ii) column-wise entity prediction on tabular datasets. We compare these models with other standard approaches on both real and synthetic data, with respect to F1-score, precision, recall, and throughput. The real datasets include internal structured data and public email data with manually tagged labels. Our experimental results show that the CNN model is simple yet effective with respect to accuracy and throughput and thus, is the most suitable candidate model to be deployed in the production environment(s). Finally, we provide several lessons learned on data limitations, data labelling and the intrinsic overlap of data entities.
Towards Automated Machine Learning: Evaluation and Comparison of AutoML Approaches and Tools
Sep 03, 2019


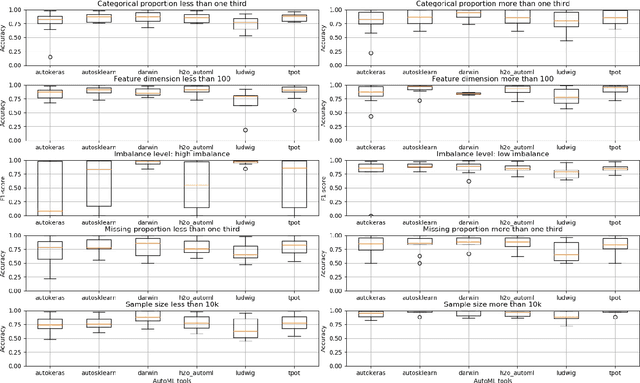
There has been considerable growth and interest in industrial applications of machine learning (ML) in recent years. ML engineers, as a consequence, are in high demand across the industry, yet improving the efficiency of ML engineers remains a fundamental challenge. Automated machine learning (AutoML) has emerged as a way to save time and effort on repetitive tasks in ML pipelines, such as data pre-processing, feature engineering, model selection, hyperparameter optimization, and prediction result analysis. In this paper, we investigate the current state of AutoML tools aiming to automate these tasks. We conduct various evaluations of the tools on many datasets, in different data segments, to examine their performance, and compare their advantages and disadvantages on different test cases.