 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensitive Data Detection with High-Throughput Neural Network Models for Financial Institutions
Paper and Code
Dec 17, 2020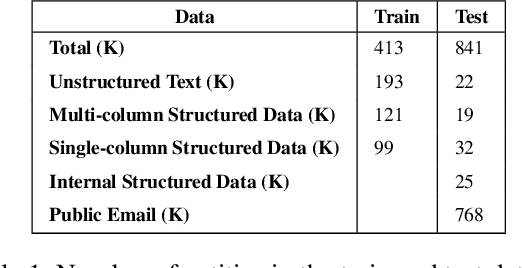
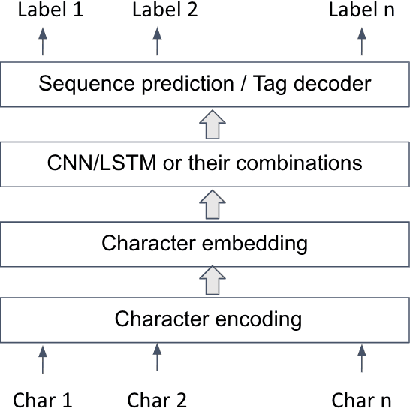
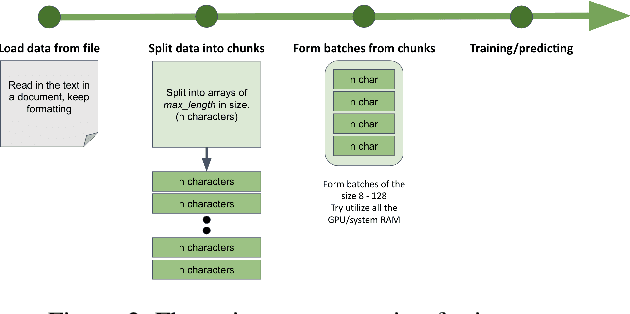
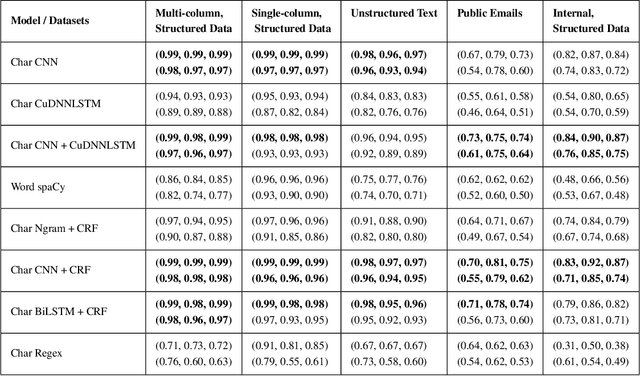
Named Entity Recognition has been extensively investigated in many fields. However, the application of sensitive entity detection for production systems in financial institutions has not been well explored due to the lack of publicly available, labeled datasets. In this paper, we use internal and synthetic datasets to evaluate various methods of detecting NPI (Nonpublic Personally Identifiable) information commonly found within financial institutions, in both unstructured and structured data formats. Character-level neural network models including CNN, LSTM, BiLSTM-CRF, and CNN-CRF are investigated on two prediction tasks: (i) entity detection on multiple data formats, and (ii) column-wise entity prediction on tabular datasets. We compare these models with other standard approaches on both real and synthetic data, with respect to F1-score, precision, recall, and throughput. The real datasets include internal structured data and public email data with manually tagged labels. Our experimental results show that the CNN model is simple yet effective with respect to accuracy and throughput and thus, is the most suitable candidate model to be deployed in the production environment(s). Finally, we provide several lessons learned on data limitations, data labelling and the intrinsic overlap of data entities.