 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIST: Towards Photorealistic Style Transfer via Multiscale Geometric Representations
Dec 03, 2024



State-of-the-art Style Transfer methods often leverage pre-trained encoders optimized for discriminative tasks, which may not be ideal for image synthesis. This can result in significant artifacts and loss of photorealism. Motivated by the ability of multiscale geometric image representations to capture fine-grained details and global structure, we propose GIST: Geometric-based Image Style Transfer, a novel Style Transfer technique that exploits the geometric properties of content and style images. GIST replaces the standard Neural Style Transfer autoencoding framework with a multiscale image expansion, preserving scene details without the need for post-processing or training. Our method matches multiresolution and multidirectional representations such as Wavelets and Contourlets by solving an optimal transport problem, leading to an efficient texture transferring. Experiments show that GIST is on-par or outperforms recent photorealistic Style Transfer approaches while significantly reducing the processing time with no model training.
SASSL: Enhancing Self-Supervised Learning via Neural Style Transfer
Dec 02, 2023



Self-supervised learning relies heavily on data augmentation to extract meaningful representations from unlabeled images. While existing state-of-the-art augmentation pipelines incorporate a wide range of primitive transformations, these often disregard natural image structure. Thus, augmented samples can exhibit degraded semantic information and low stylistic diversity, affecting downstream performance of self-supervised representations. To overcome this, we propose SASSL: Style Augmentations for Self Supervised Learning, a novel augmentation technique based on Neural Style Transfer. The method decouples semantic and stylistic attributes in images and applies transformations exclusively to the style while preserving content, generating diverse augmented samples that better retain their semantic properties. Experimental results show our technique achieves a top-1 classification performance improvement of more than 2% on ImageNet compared to the well-established MoCo v2. We also measure transfer learning performance across five diverse datasets, observing significant improvements of up to 3.75%. Our experiments indicate that decoupling style from content information and transferring style across datasets to diversify augmentations can significantly improve downstream performance of self-supervised representations.
Making Vision Transformers Truly Shift-Equivariant
May 25, 2023



For computer vision tasks, Vision Transformers (ViTs) have become one of the go-to deep net architectures. Despite being inspired by Convolutional Neural Networks (CNNs), ViTs remain sensitive to small shifts in the input image. To address this, we introduce novel designs for each of the modules in ViTs, such as tokenization, self-attention, patch merging, and positional encoding. With our proposed modules, we achieve truly shift-equivariant ViTs on four well-established models, namely, Swin, SwinV2, MViTv2, and CvT, both in theory and practice. Empirically, we tested these models on image classification and semantic segmentation, achieving competitive performance across three different datasets while maintaining 100% shift consistency.
Learnable Polyphase Sampling for Shift Invariant and Equivariant Convolutional Networks
Oct 14, 2022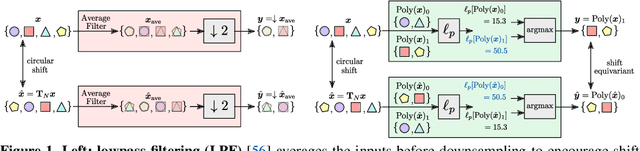
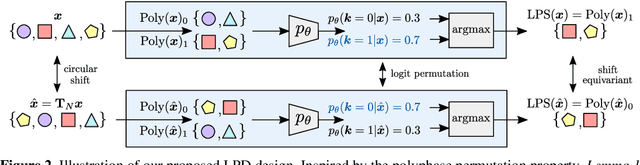
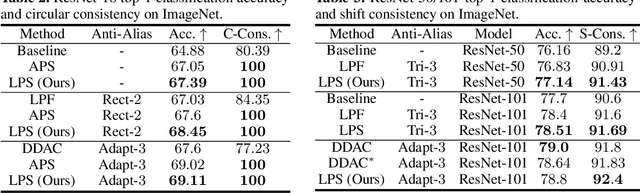
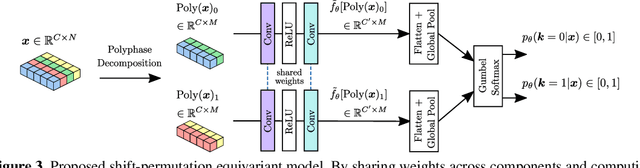
We propose learnable polyphase sampling (LPS), a pair of learnable down/upsampling layers that enable truly shift-invariant and equivariant convolutional networks. LPS can be trained end-to-end from data and generalizes existing handcrafted downsampling layers. It is widely applicable as it can be integrated into any convolutional network by replacing down/upsampling layers. We evaluate LPS on image classification and semantic segmentation. Experiments show that LPS is on-par with or outperforms existing methods in both performance and shift consistency. For the first time, we achieve true shift-equivariance on semantic segmentation (PASCAL VOC), i.e., 100% shift consistency, outperforming baselines by an absolute 3.3%.
Inverting Adversarially Robust Networks for Image Synthesis
Jun 13, 2021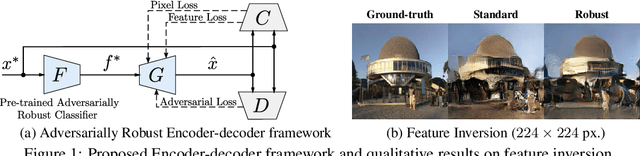
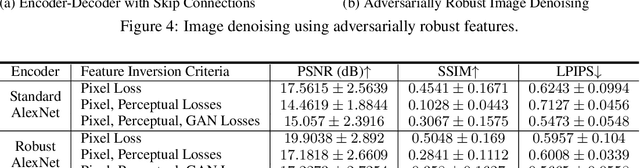
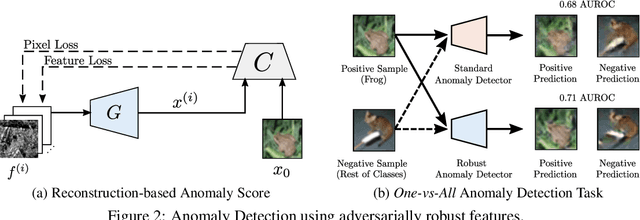
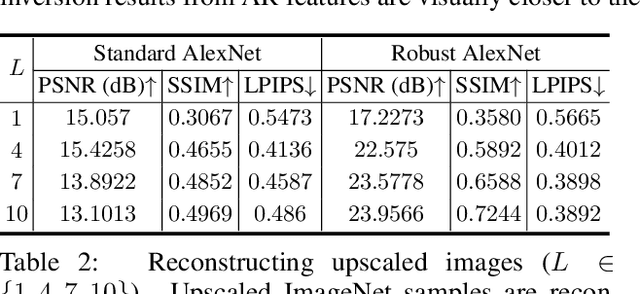
Recent research in adversarially robust classifiers suggests their representations tend to be aligned with human perception, which makes them attractive for image synthesis and restoration applications. Despite favorable empirical results on a few downstream tasks, their advantages are limited to slow and sensitive optimization-based techniques. Moreover, their use on generative models remains unexplored. This work proposes the use of robust representations as a perceptual primitive for feature inversion models, and show its benefits with respect to standard non-robust image features. We empirically show that adopting robust representations as an image prior significantly improves the reconstruction accuracy of CNN-based feature inversion models. Furthermore, it allows reconstructing images at multiple scales out-of-the-box. Following these findings, we propose an encoding-decoding network based on robust representations and show its advantages for applications such as anomaly detection, style transfer and image denoising.