 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing User Sequence Modeling through Barlow Twins-based Self-Supervised Learning
May 02, 2025


User sequence modeling is crucial for modern large-scale recommendation systems, as it enables the extraction of informative representations of users and items from their historical interactions. These user representations are widely used for a variety of downstream tasks to enhance users' online experience. A key challenge for learning these representations is the lack of labeled training data. While self-supervised learning (SSL) methods have emerged as a promising solution for learning representations from unlabeled data, many existing approaches rely on extensive negative sampling, which can be computationally expensive and may not always be feasible in real-world scenario. In this work, we propose an adaptation of Barlow Twins, a state-of-the-art SSL methods, to user sequence modeling by incorporating suitable augmentation methods. Our approach aims to mitigate the need for large negative sample batches, enabling effective representation learning with smaller batch sizes and limited labeled data. We evaluate our method on the MovieLens-1M, MovieLens-20M, and Yelp datasets, demonstrating that our method consistently outperforms the widely-used dual encoder model across three downstream tasks, achieving an 8%-20% improvement in accuracy. Our findings underscore the effectiveness of our approach in extracting valuable sequence-level information for user modeling, particularly in scenarios where labeled data is scarce and negative examples are limited.
SASSL: Enhancing Self-Supervised Learning via Neural Style Transfer
Dec 02, 2023



Self-supervised learning relies heavily on data augmentation to extract meaningful representations from unlabeled images. While existing state-of-the-art augmentation pipelines incorporate a wide range of primitive transformations, these often disregard natural image structure. Thus, augmented samples can exhibit degraded semantic information and low stylistic diversity, affecting downstream performance of self-supervised representations. To overcome this, we propose SASSL: Style Augmentations for Self Supervised Learning, a novel augmentation technique based on Neural Style Transfer. The method decouples semantic and stylistic attributes in images and applies transformations exclusively to the style while preserving content, generating diverse augmented samples that better retain their semantic properties. Experimental results show our technique achieves a top-1 classification performance improvement of more than 2% on ImageNet compared to the well-established MoCo v2. We also measure transfer learning performance across five diverse datasets, observing significant improvements of up to 3.75%. Our experiments indicate that decoupling style from content information and transferring style across datasets to diversify augmentations can significantly improve downstream performance of self-supervised representations.
Random Field Augmentations for Self-Supervised Representation Learning
Nov 07, 2023Self-supervised representation learning is heavily dependent on data augmentations to specify the invariances encoded in representations. Previous work has shown that applying diverse data augmentations is crucial to downstream performance, but augmentation techniques remain under-explored. In this work, we propose a new family of local transformations based on Gaussian random fields to generate image augmentations for self-supervised representation learning. These transformations generalize the well-established affine and color transformations (translation, rotation, color jitter, etc.) and greatly increase the space of augmentations by allowing transformation parameter values to vary from pixel to pixel. The parameters are treated as continuous functions of spatial coordinates, and modeled as independent Gaussian random fields. Empirical results show the effectiveness of the new transformations for self-supervised representation learning. Specifically, we achieve a 1.7% top-1 accuracy improvement over baseline on ImageNet downstream classification, and a 3.6% improvement on out-of-distribution iNaturalist downstream classification. However, due to the flexibility of the new transformations, learned representations are sensitive to hyperparameters. While mild transformations improve representations, we observe that strong transformations can degrade the structure of an image, indicating that balancing the diversity and strength of augmentations is important for improving generalization of learned representations.
Towards Federated Learning Under Resource Constraints via Layer-wise Training and Depth Dropout
Sep 11, 2023



Large machine learning models trained on diverse data have recently seen unprecedented success. Federated learning enables training on private data that may otherwise be inaccessible, such as domain-specific datasets decentralized across many clients. However, federated learning can be difficult to scale to large models when clients have limited resources. This challenge often results in a trade-off between model size and access to diverse data. To mitigate this issue and facilitate training of large models on edge devices, we introduce a simple yet effective strategy, Federated Layer-wise Learning, to simultaneously reduce per-client memory, computation, and communication costs. Clients train just a single layer each round, reducing resource costs considerably with minimal performance degradation. We also introduce Federated Depth Dropout, a complementary technique that randomly drops frozen layers during training, to further reduce resource usage. Coupling these two techniques enables us to effectively train significantly larger models on edge devices. Specifically, we reduce training memory usage by 5x or more in federated self-supervised representation learning and demonstrate that performance in downstream tasks is comparable to conventional federated self-supervised learning.
Federated Variational Inference: Towards Improved Personalization and Generalization
May 25, 2023



Conventional federated learning algorithms train a single global model by leveraging all participating clients' data. However, due to heterogeneity in client generative distributions and predictive models, these approaches may not appropriately approximate the predictive process, converge to an optimal state, or generalize to new clients. We study personalization and generalization in stateless cross-device federated learning setups assuming heterogeneity in client data distributions and predictive models. We first propose a hierarchical generative model and formalize it using Bayesian Inference. We then approximate this process using Variational Inference to train our model efficiently. We call this algorithm Federated Variational Inference (FedVI). We use PAC-Bayes analysis to provide generalization bounds for FedVI. We evaluate our model on FEMNIST and CIFAR-100 image classification and show that FedVI beats the state-of-the-art on both tasks.
Federated Training of Dual Encoding Models on Small Non-IID Client Datasets
Sep 30, 2022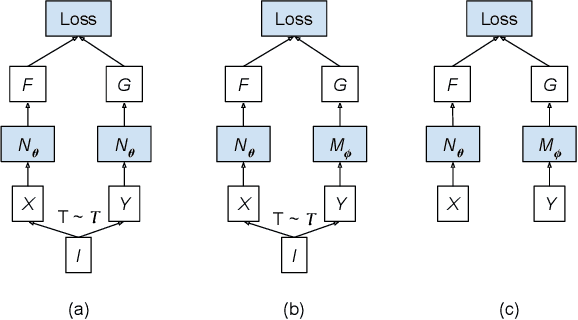


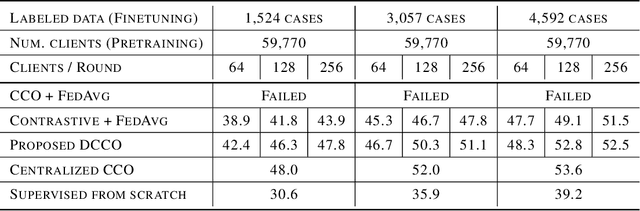
Dual encoding models that encode a pair of inputs are widely used for representation learning. Many approaches train dual encoding models by maximizing agreement between pairs of encodings on centralized training data. However, in many scenarios, datasets are inherently decentralized across many clients (user devices or organizations) due to privacy concerns, motivating federated learning. In this work, we focus on federated training of dual encoding models on decentralized data composed of many small, non-IID (independent and identically distributed) client datasets. We show that existing approaches that work well in centralized settings perform poorly when naively adapted to this setting using federated averaging. We observe that, we can simulate large-batch loss computation on individual clients for loss functions that are based on encoding statistics. Based on this insight, we propose a novel federated training approach, Distributed Cross Correlation Optimization (DCCO), which trains dual encoding models using encoding statistics aggregated across clients, without sharing individual data samples. Our experimental results on two datasets demonstrate that the proposed DCCO approach outperforms federated variants of existing approaches by a large margin.
Camera View Adjustment Prediction for Improving Image Composition
Apr 15, 2021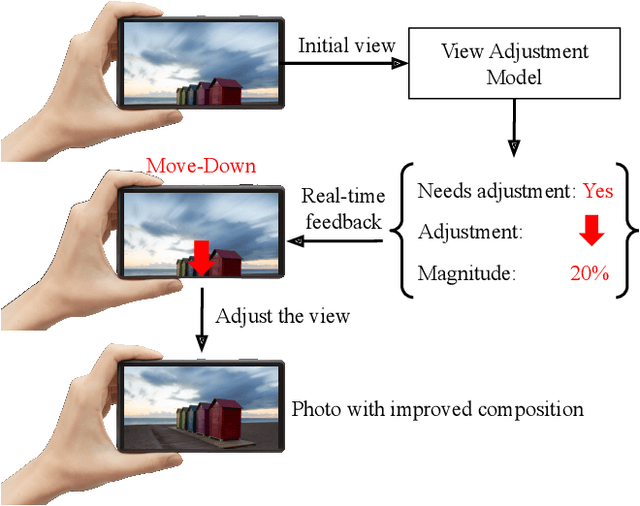
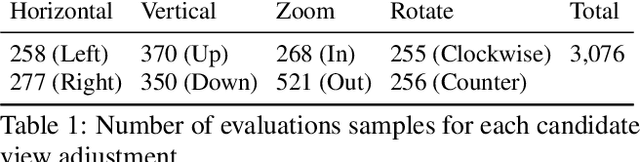


Image composition plays an important role in the quality of a photo. However, not every camera user possesses the knowledge and expertise required for capturing well-composed photos. While post-capture cropping can improve the composition sometimes, it does not work in many common scenarios in which the photographer needs to adjust the camera view to capture the best shot. To address this issue, we propose a deep learning-based approach that provides suggestions to the photographer on how to adjust the camera view before capturing. By optimizing the composition before a photo is captured, our system helps photographers to capture better photos. As there is no publicly-available dataset for this task, we create a view adjustment dataset by repurposing existing image cropping datasets. Furthermore, we propose a two-stage semi-supervised approach that utilizes both labeled and unlabeled images for training a view adjustment model. Experiment results show that the proposed semi-supervised approach outperforms the corresponding supervised alternatives, and our user study results show that the suggested view adjustment improves image composition 79% of the time.
Speaker Diarization with LSTM
Jan 31, 2018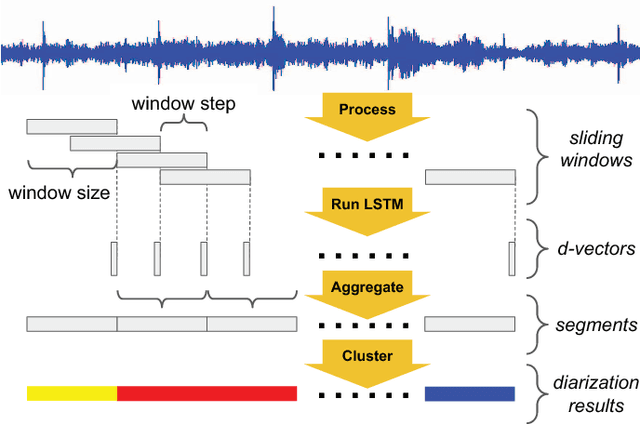
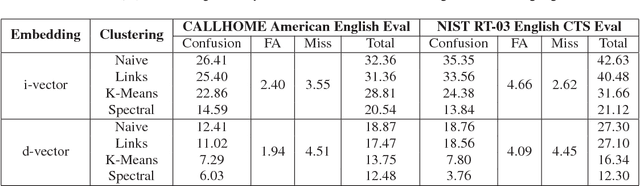

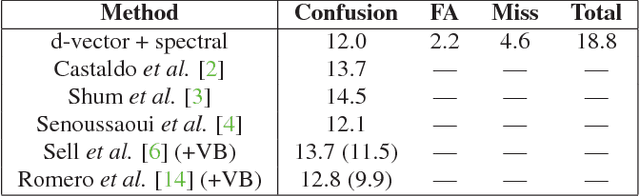
For many years, i-vector based audio embedding techniques were the dominant approach for speaker verification and speaker diarization applications. However, mirroring the rise of deep learning in various domains, neural network based audio embeddings, also known as d-vectors, have consistently demonstrated superior speaker verification performance. In this paper, we build on the success of d-vector based speaker verification systems to develop a new d-vector based approach to speaker diarization. Specifically, we combine LSTM-based d-vector audio embeddings with recent work in non-parametric clustering to obtain a state-of-the-art speaker diarization system. Our system is evaluated on three standard public datasets, suggesting that d-vector based diarization systems offer significant advantages over traditional i-vector based systems. We achieved a 12.0% diarization error rate on NIST SRE 2000 CALLHOME, while our model is trained with out-of-domain data from voice search logs.
Links: A High-Dimensional Online Clustering Method
Jan 30, 2018We present a novel algorithm, called Links, designed to perform online clustering on unit vectors in a high-dimensional Euclidean space. The algorithm is appropriate when it is necessary to cluster data efficiently as it streams in, and is to be contrasted with traditional batch clustering algorithms that have access to all data at once. For example, Links has been successfully applied to embedding vectors generated from face images or voice recordings for the purpose of recognizing people, thereby providing real-time identification during video or audio capture.