 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskINT: Video Editing via Interpolative Non-autoregressive Masked Transformers
Dec 19, 2023



Recent advances in generative AI have significantly enhanced image and video editing, particularly in the context of text prompt control. State-of-the-art approaches predominantly rely on diffusion models to accomplish these tasks. However, the computational demands of diffusion-based methods are substantial, often necessitating large-scale paired datasets for training, and therefore challenging the deployment in practical applications. This study addresses this challenge by breaking down the text-based video editing process into two separate stages. In the first stage, we leverage an existing text-to-image diffusion model to simultaneously edit a few keyframes without additional fine-tuning. In the second stage, we introduce an efficient model called MaskINT, which is built on non-autoregressive masked generative transformers and specializes in frame interpolation between the keyframes, benefiting from structural guidance provided by intermediate frames. Our comprehensive set of experiments illustrates the efficacy and efficiency of MaskINT when compared to other diffusion-based methodologies. This research offers a practical solution for text-based video editing and showcases the potential of non-autoregressive masked generative transformers in this domain.
2.5D Visual Relationship Detection
Apr 26, 2021
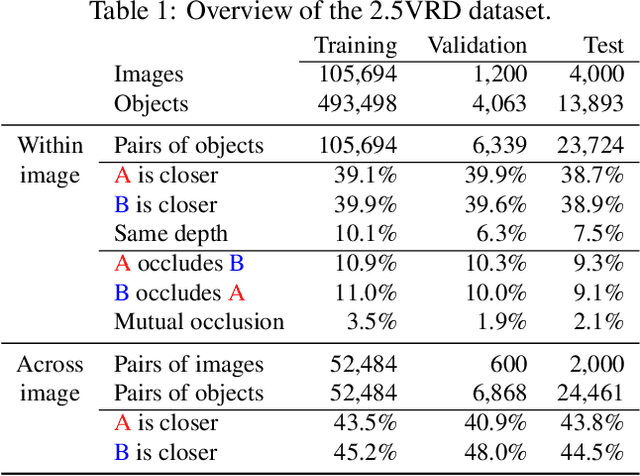
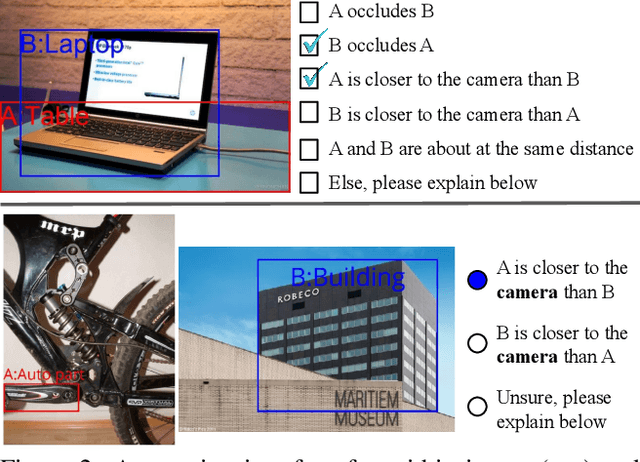

Visual 2.5D perception involves understanding the semantics and geometry of a scene through reasoning about object relationships with respect to the viewer in an environment. However, existing works in visual recognition primarily focus on the semantics. To bridge this gap, we study 2.5D visual relationship detection (2.5VRD), in which the goal is to jointly detect objects and predict their relative depth and occlusion relationships. Unlike general VRD, 2.5VRD is egocentric, using the camera's viewpoint as a common reference for all 2.5D relationships. Unlike depth estimation, 2.5VRD is object-centric and not only focuses on depth. To enable progress on this task, we create a new dataset consisting of 220k human-annotated 2.5D relationships among 512K objects from 11K images. We analyze this dataset and conduct extensive experiments including benchmarking multiple state-of-the-art VRD models on this task. Our results show that existing models largely rely on semantic cues and simple heuristics to solve 2.5VRD, motivating further research on models for 2.5D perception. The new dataset is available at https://github.com/google-research-datasets/2.5vrd.
Camera View Adjustment Prediction for Improving Image Composition
Apr 15, 2021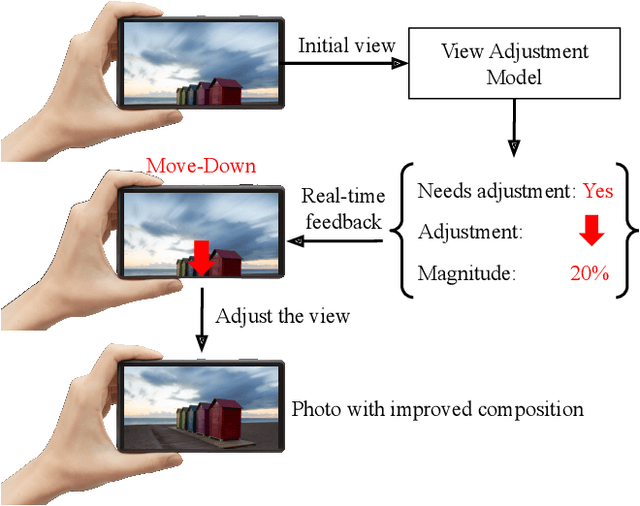
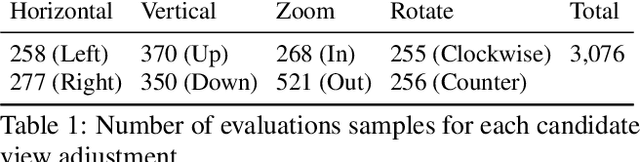


Image composition plays an important role in the quality of a photo. However, not every camera user possesses the knowledge and expertise required for capturing well-composed photos. While post-capture cropping can improve the composition sometimes, it does not work in many common scenarios in which the photographer needs to adjust the camera view to capture the best shot. To address this issue, we propose a deep learning-based approach that provides suggestions to the photographer on how to adjust the camera view before capturing. By optimizing the composition before a photo is captured, our system helps photographers to capture better photos. As there is no publicly-available dataset for this task, we create a view adjustment dataset by repurposing existing image cropping datasets. Furthermore, we propose a two-stage semi-supervised approach that utilizes both labeled and unlabeled images for training a view adjustment model. Experiment results show that the proposed semi-supervised approach outperforms the corresponding supervised alternatives, and our user study results show that the suggested view adjustment improves image composition 79% of the time.
Contrastive Learning for Label-Efficient Semantic Segmentation
Dec 23, 2020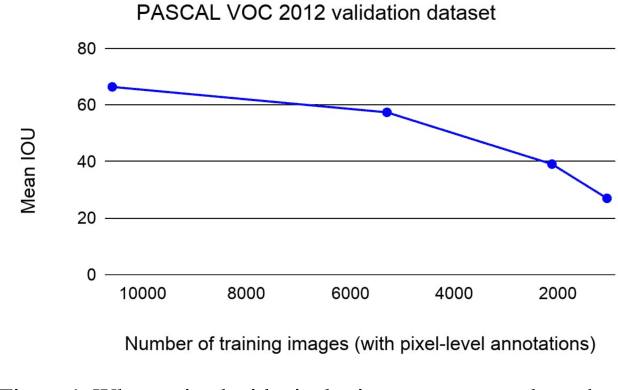


Collecting labeled data for the task of semantic segmentation is expensive and time-consuming, as it requires dense pixel-level annotations. While recent Convolutional Neural Network (CNN) based semantic segmentation approaches have achieved impressive results by using large amounts of labeled training data, their performance drops significantly as the amount of labeled data decreases. This happens because deep CNNs trained with the de facto cross-entropy loss can easily overfit to small amounts of labeled data. To address this issue, we propose a simple and effective contrastive learning-based training strategy in which we first pretrain the network using a pixel-wise class label-based contrastive loss, and then fine-tune it using the cross-entropy loss. This approach increases intra-class compactness and inter-class separability thereby resulting in a better pixel classifier. We demonstrate the effectiveness of the proposed training strategy in both fully-supervised and semi-supervised settings using the Cityscapes and PASCAL VOC 2012 segmentation datasets. Our results show that pretraining with label-based contrastive loss results in large performance gains (more than 20% absolute improvement in some settings) when the amount of labeled data is limited.
ASIST: Automatic Semantically Invariant Scene Transformation
Dec 04, 2015
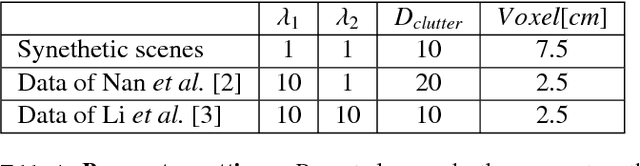
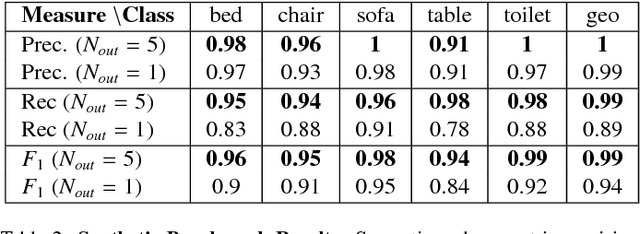
We present ASIST, a technique for transforming point clouds by replacing objects with their semantically equivalent counterparts. Transformations of this kind have applications in virtual reality, repair of fused scans, and robotics. ASIST is based on a unified formulation of semantic labeling and object replacement; both result from minimizing a single objective. We present numerical tools for the efficient solution of this optimization problem. The method is experimentally assessed on new datasets of both synthetic and real point clouds, and is additionally compared to two recent works on object replacement on data from the corresponding papers.