 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Why Does Sharpness-Aware Minimization Generalize Better Than SGD?
Oct 11, 2023



The challenge of overfitting, in which the model memorizes the training data and fails to generalize to test data, has become increasingly significant in the training of large neural networks. To tackle this challenge, Sharpness-Aware Minimization (SAM) has emerged as a promising training method, which can improve the generalization of neural networks even in the presence of label noise. However, a deep understanding of how SAM works, especially in the setting of nonlinear neural networks and classification tasks, remains largely missing. This paper fills this gap by demonstrating why SAM generalizes better than Stochastic Gradient Descent (SGD) for a certain data model and two-layer convolutional ReLU networks. The loss landscape of our studied problem is nonsmooth, thus current explanations for the success of SAM based on the Hessian information are insufficient. Our result explains the benefits of SAM, particularly its ability to prevent noise learning in the early stages, thereby facilitating more effective learning of features. Experiments on both synthetic and real data corroborate our theory.
Red Teaming Language Model Detectors with Language Models
May 31, 2023The prevalence and high capacity of large language models (LLMs) present significant safety and ethical risks when malicious users exploit them for automated content generation. To prevent the potentially deceptive usage of LLMs, recent works have proposed several algorithms to detect machine-generated text. In this paper, we systematically test the reliability of the existing detectors, by designing two types of attack strategies to fool the detectors: 1) replacing words with their synonyms based on the context; 2) altering the writing style of generated text. These strategies are implemented by instructing LLMs to generate synonymous word substitutions or writing directives that modify the style without human involvement, and the LLMs leveraged in the attack can also be protected by detectors. Our research reveals that our attacks effectively compromise the performance of all tested detectors, thereby underscoring the urgent need for the development of more robust machine-generated text detection systems.
Symbol tuning improves in-context learning in language models
May 15, 2023



We present symbol tuning - finetuning language models on in-context input-label pairs where natural language labels (e.g., "positive/negative sentiment") are replaced with arbitrary symbols (e.g., "foo/bar"). Symbol tuning leverages the intuition that when a model cannot use instructions or natural language labels to figure out a task, it must instead do so by learning the input-label mappings. We experiment with symbol tuning across Flan-PaLM models up to 540B parameters and observe benefits across various settings. First, symbol tuning boosts performance on unseen in-context learning tasks and is much more robust to underspecified prompts, such as those without instructions or without natural language labels. Second, symbol-tuned models are much stronger at algorithmic reasoning tasks, with up to 18.2% better performance on the List Functions benchmark and up to 15.3% better performance on the Simple Turing Concepts benchmark. Finally, symbol-tuned models show large improvements in following flipped-labels presented in-context, meaning that they are more capable of using in-context information to override prior semantic knowledge.
Symbolic Discovery of Optimization Algorithms
Feb 17, 2023



We present a method to formulate algorithm discovery as program search, and apply it to discover optimization algorithms for deep neural network training. We leverage efficient search techniques to explore an infinite and sparse program space. To bridge the large generalization gap between proxy and target tasks, we also introduce program selection and simplification strategies. Our method discovers a simple and effective optimization algorithm, $\textbf{Lion}$ ($\textit{Evo$\textbf{L}$ved S$\textbf{i}$gn M$\textbf{o}$me$\textbf{n}$tum}$). It is more memory-efficient than Adam as it only keeps track of the momentum. Different from adaptive optimizers, its update has the same magnitude for each parameter calculated through the sign operation. We compare Lion with widely used optimizers, such as Adam and Adafactor, for training a variety of models on different tasks. On image classification, Lion boosts the accuracy of ViT by up to 2% on ImageNet and saves up to 5x the pre-training compute on JFT. On vision-language contrastive learning, we achieve 88.3% $\textit{zero-shot}$ and 91.1% $\textit{fine-tuning}$ accuracy on ImageNet, surpassing the previous best results by 2% and 0.1%, respectively. On diffusion models, Lion outperforms Adam by achieving a better FID score and reducing the training compute by up to 2.3x. For autoregressive, masked language modeling, and fine-tuning, Lion exhibits a similar or better performance compared to Adam. Our analysis of Lion reveals that its performance gain grows with the training batch size. It also requires a smaller learning rate than Adam due to the larger norm of the update produced by the sign function. Additionally, we examine the limitations of Lion and identify scenarios where its improvements are small or not statistically significant. The implementation of Lion is publicly available.
Towards Efficient and Scalable Sharpness-Aware Minimization
Mar 05, 2022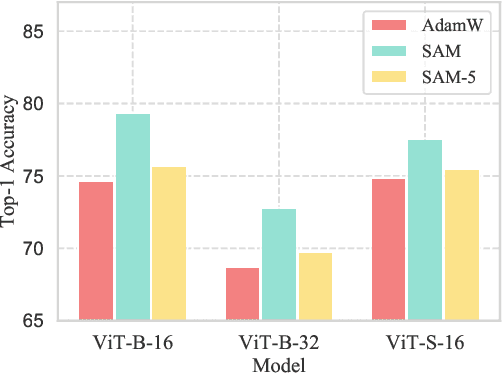

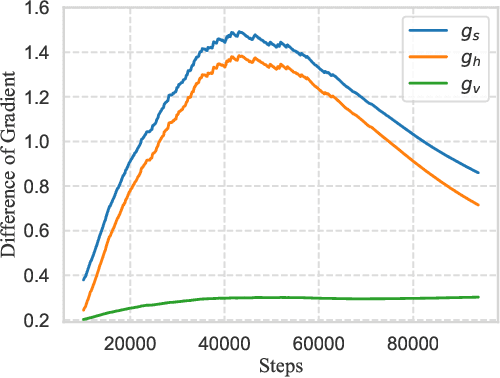

Recently, Sharpness-Aware Minimization (SAM), which connects the geometry of the loss landscape and generalization, has demonstrated significant performance boosts on training large-scale models such as vision transformers. However, the update rule of SAM requires two sequential (non-parallelizable) gradient computations at each step, which can double the computational overhead. In this paper, we propose a novel algorithm LookSAM - that only periodically calculates the inner gradient ascent, to significantly reduce the additional training cost of SAM. The empirical results illustrate that LookSAM achieves similar accuracy gains to SAM while being tremendously faster - it enjoys comparable computational complexity with first-order optimizers such as SGD or Adam. To further evaluate the performance and scalability of LookSAM, we incorporate a layer-wise modification and perform experiments in the large-batch training scenario, which is more prone to converge to sharp local minima. We are the first to successfully scale up the batch size when training Vision Transformers (ViTs). With a 64k batch size, we are able to train ViTs from scratch in minutes while maintaining competitive performance.
Can Vision Transformers Perform Convolution?
Nov 03, 2021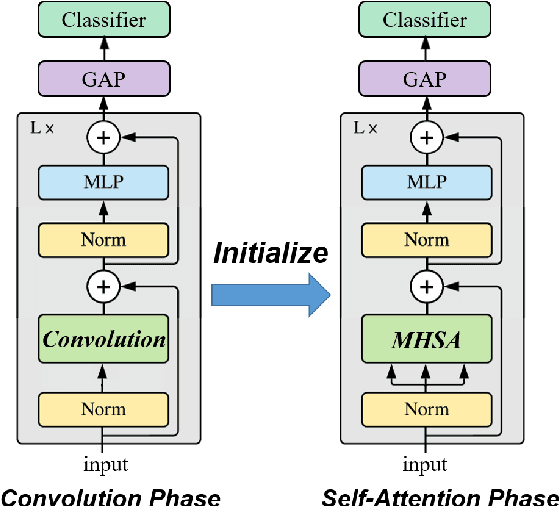
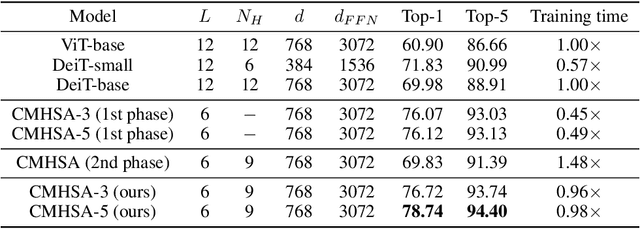
Several recent studies have demonstrated that attention-based networks, such as Vision Transformer (ViT), can outperform Convolutional Neural Networks (CNNs) on several computer vision tasks without using convolutional layers. This naturally leads to the following questions: Can a self-attention layer of ViT express any convolution operation? In this work, we prove that a single ViT layer with image patches as the input can perform any convolution operation constructively, where the multi-head attention mechanism and the relative positional encoding play essential roles. We further provide a lower bound on the number of heads for Vision Transformers to express CNNs. Corresponding with our analysis, experimental results show that the construction in our proof can help inject convolutional bias into Transformers and significantly improve the performance of ViT in low data regimes.
RANK-NOSH: Efficient Predictor-Based Architecture Search via Non-Uniform Successive Halving
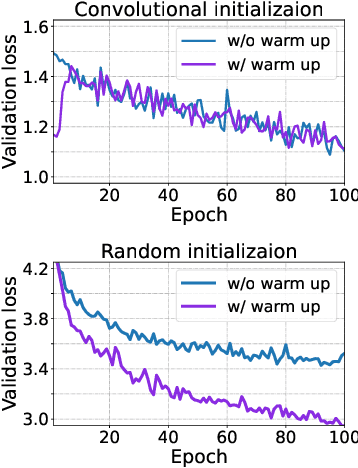
Aug 18, 2021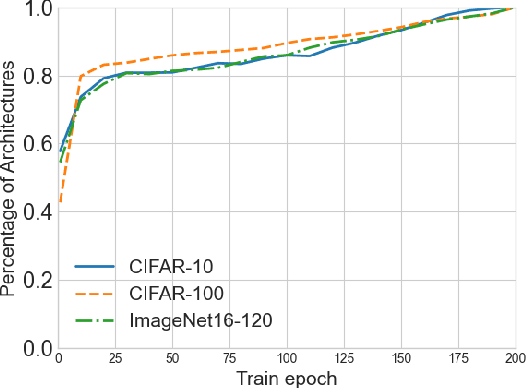
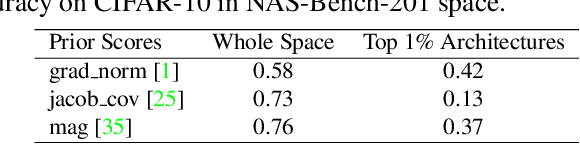
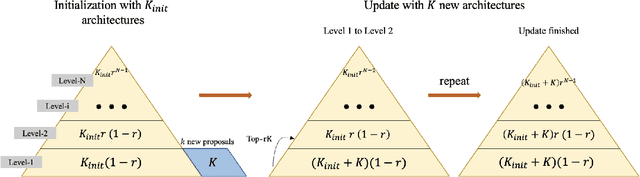
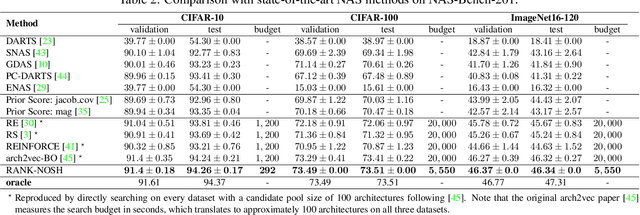
Predictor-based algorithms have achieved remarkable performance in the Neural Architecture Search (NAS) tasks. However, these methods suffer from high computation costs, as training the performance predictor usually requires training and evaluating hundreds of architectures from scratch. Previous works along this line mainly focus on reducing the number of architectures required to fit the predictor. In this work, we tackle this challenge from a different perspective - improve search efficiency by cutting down the computation budget of architecture training. We propose NOn-uniform Successive Halving (NOSH), a hierarchical scheduling algorithm that terminates the training of underperforming architectures early to avoid wasting budget. To effectively leverage the non-uniform supervision signals produced by NOSH, we formulate predictor-based architecture search as learning to rank with pairwise comparisons. The resulting method - RANK-NOSH, reduces the search budget by ~5x while achieving competitive or even better performance than previous state-of-the-art predictor-based methods on various spaces and datasets.
Rethinking Architecture Selection in Differentiable NAS
Aug 10, 2021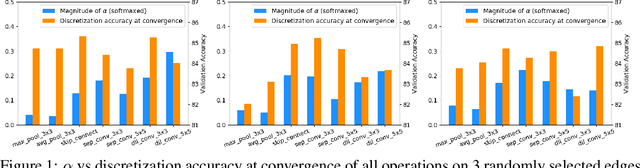
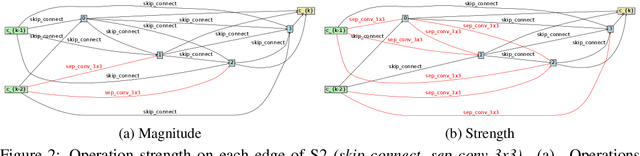
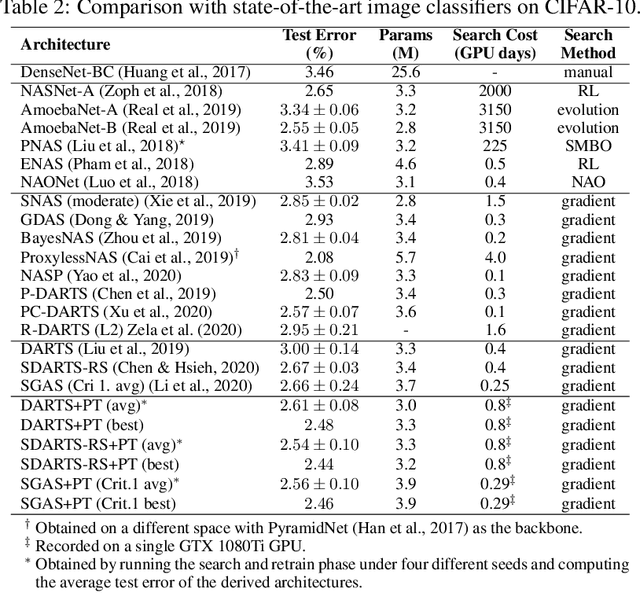

Differentiable Neural Architecture Search is one of the most popular Neural Architecture Search (NAS) methods for its search efficiency and simplicity, accomplished by jointly optimizing the model weight and architecture parameters in a weight-sharing supernet via gradient-based algorithms. At the end of the search phase, the operations with the largest architecture parameters will be selected to form the final architecture, with the implicit assumption that the values of architecture parameters reflect the operation strength. While much has been discussed about the supernet's optimization, the architecture selection process has received little attention. We provide empirical and theoretical analysis to show that the magnitude of architecture parameters does not necessarily indicate how much the operation contributes to the supernet's performance. We propose an alternative perturbation-based architecture selection that directly measures each operation's influence on the supernet. We re-evaluate several differentiable NAS methods with the proposed architecture selection and find that it is able to extract significantly improved architectures from the underlying supernets consistently. Furthermore, we find that several failure modes of DARTS can be greatly alleviated with the proposed selection method, indicating that much of the poor generalization observed in DARTS can be attributed to the failure of magnitude-based architecture selection rather than entirely the optimization of its supernet.
When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations
Jun 03, 2021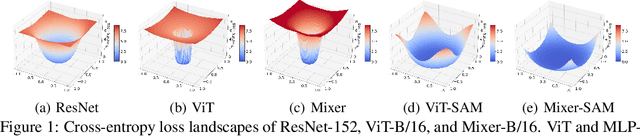
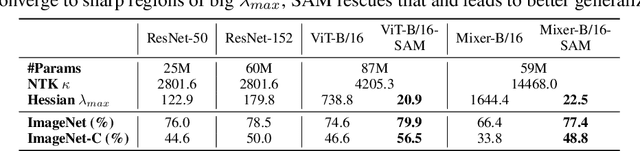
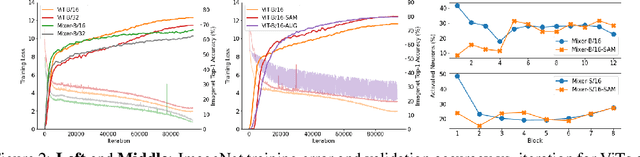
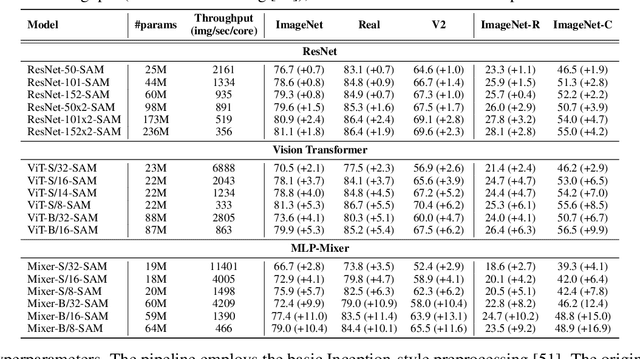
Vision Transformers (ViTs) and MLPs signal further efforts on replacing hand-wired features or inductive biases with general-purpose neural architectures. Existing works empower the models by massive data, such as large-scale pretraining and/or repeated strong data augmentations, and still report optimization-related problems (e.g., sensitivity to initialization and learning rate). Hence, this paper investigates ViTs and MLP-Mixers from the lens of loss geometry, intending to improve the models' data efficiency at training and generalization at inference. Visualization and Hessian reveal extremely sharp local minima of converged models. By promoting smoothness with a recently proposed sharpness-aware optimizer, we substantially improve the accuracy and robustness of ViTs and MLP-Mixers on various tasks spanning supervised, adversarial, contrastive, and transfer learning (e.g., +5.3\% and +11.0\% top-1 accuracy on ImageNet for ViT-B/16 and Mixer-B/16, respectively, with the simple Inception-style preprocessing). We show that the improved smoothness attributes to sparser active neurons in the first few layers. The resultant ViTs outperform ResNets of similar size and throughput when trained from scratch on ImageNet without large-scale pretraining or strong data augmentations. They also possess more perceptive attention maps.