 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Autonomous Mathematics Discovery with Gemini: A Case Study on the Erdős Problems
Jan 29, 2026We present a case study in semi-autonomous mathematics discovery, using Gemini to systematically evaluate 700 conjectures labeled 'Open' in Bloom's Erdős Problems database. We employ a hybrid methodology: AI-driven natural language verification to narrow the search space, followed by human expert evaluation to gauge correctness and novelty. We address 13 problems that were marked 'Open' in the database: 5 through seemingly novel autonomous solutions, and 8 through identification of previous solutions in the existing literature. Our findings suggest that the 'Open' status of the problems was through obscurity rather than difficulty. We also identify and discuss issues arising in applying AI to math conjectures at scale, highlighting the difficulty of literature identification and the risk of ''subconscious plagiarism'' by AI. We reflect on the takeaways from AI-assisted efforts on the Erdős Problems.
Gold-medalist Performance in Solving Olympiad Geometry with AlphaGeometry2
Feb 05, 2025We present AlphaGeometry2, a significantly improved version of AlphaGeometry introduced in Trinh et al. (2024), which has now surpassed an average gold medalist in solving Olympiad geometry problems. To achieve this, we first extend the original AlphaGeometry language to tackle harder problems involving movements of objects, and problems containing linear equations of angles, ratios, and distances. This, together with other additions, has markedly improved the coverage rate of the AlphaGeometry language on International Math Olympiads (IMO) 2000-2024 geometry problems from 66% to 88%. The search process of AlphaGeometry2 has also been greatly improved through the use of Gemini architecture for better language modeling, and a novel knowledge-sharing mechanism that combines multiple search trees. Together with further enhancements to the symbolic engine and synthetic data generation, we have significantly boosted the overall solving rate of AlphaGeometry2 to 84% for $\textit{all}$ geometry problems over the last 25 years, compared to 54% previously. AlphaGeometry2 was also part of the system that achieved silver-medal standard at IMO 2024 https://dpmd.ai/imo-silver. Last but not least, we report progress towards using AlphaGeometry2 as a part of a fully automated system that reliably solves geometry problems directly from natural language input.
HaloQuest: A Visual Hallucination Dataset for Advancing Multimodal Reasoning
Jul 22, 2024

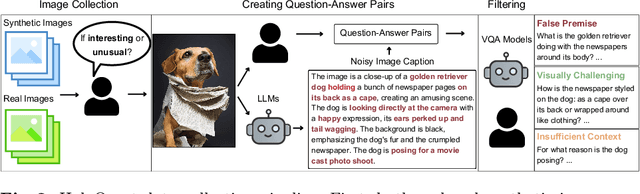
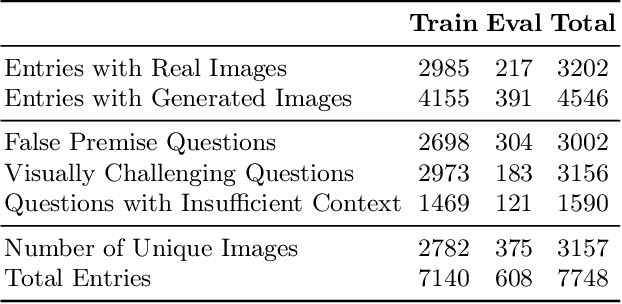
Hallucination has been a major problem for large language models and remains a critical challenge when it comes to multimodality in which vision-language models (VLMs) have to deal with not just textual but also visual inputs. Despite rapid progress in VLMs, resources for evaluating and addressing multimodal hallucination are limited and mostly focused on evaluation. This work introduces HaloQuest, a novel visual question answering dataset that captures various aspects of multimodal hallucination such as false premises, insufficient contexts, and visual challenges. A novel idea from HaloQuest is to leverage synthetic images, apart from real ones, to enable dataset creation at scale. With over 7.7K examples spanning across a wide variety of categories, HaloQuest was designed to be both a challenging benchmark for VLMs and a fine-tuning dataset for advancing multimodal reasoning. Our experiments reveal that current models struggle with HaloQuest, with all open-source VLMs achieving below 36% accuracy. On the other hand, fine-tuning on HaloQuest significantly reduces hallucination rates while preserving performance on standard reasoning tasks. Our results discover that benchmarking with generated images is highly correlated (r=0.97) with real images. Last but not least, we propose a novel Auto-Eval mechanism that is highly correlated with human raters (r=0.99) for evaluating VLMs. In sum, this work makes concrete strides towards understanding, evaluating, and mitigating hallucination in VLMs, serving as an important step towards more reliable multimodal AI systems in the future.
FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation
Oct 05, 2023



Most large language models (LLMs) are trained once and never updated; thus, they lack the ability to dynamically adapt to our ever-changing world. In this work, we perform a detailed study of the factuality of LLM-generated text in the context of answering questions that test current world knowledge. Specifically, we introduce FreshQA, a novel dynamic QA benchmark encompassing a diverse range of question and answer types, including questions that require fast-changing world knowledge as well as questions with false premises that need to be debunked. We benchmark a diverse array of both closed and open-source LLMs under a two-mode evaluation procedure that allows us to measure both correctness and hallucination. Through human evaluations involving more than 50K judgments, we shed light on limitations of these models and demonstrate significant room for improvement: for instance, all models (regardless of model size) struggle on questions that involve fast-changing knowledge and false premises. Motivated by these results, we present FreshPrompt, a simple few-shot prompting method that substantially boosts the performance of an LLM on FreshQA by incorporating relevant and up-to-date information retrieved from a search engine into the prompt. Our experiments show that FreshPrompt outperforms both competing search engine-augmented prompting methods such as Self-Ask (Press et al., 2022) as well as commercial systems such as Perplexity.AI. Further analysis of FreshPrompt reveals that both the number of retrieved evidences and their order play a key role in influencing the correctness of LLM-generated answers. Additionally, instructing the LLM to generate concise and direct answers helps reduce hallucination compared to encouraging more verbose answers. To facilitate future work, we release FreshQA at github.com/freshllms/freshqa and commit to updating it at regular intervals.
Symbolic Discovery of Optimization Algorithms
Feb 17, 2023



We present a method to formulate algorithm discovery as program search, and apply it to discover optimization algorithms for deep neural network training. We leverage efficient search techniques to explore an infinite and sparse program space. To bridge the large generalization gap between proxy and target tasks, we also introduce program selection and simplification strategies. Our method discovers a simple and effective optimization algorithm, $\textbf{Lion}$ ($\textit{Evo$\textbf{L}$ved S$\textbf{i}$gn M$\textbf{o}$me$\textbf{n}$tum}$). It is more memory-efficient than Adam as it only keeps track of the momentum. Different from adaptive optimizers, its update has the same magnitude for each parameter calculated through the sign operation. We compare Lion with widely used optimizers, such as Adam and Adafactor, for training a variety of models on different tasks. On image classification, Lion boosts the accuracy of ViT by up to 2% on ImageNet and saves up to 5x the pre-training compute on JFT. On vision-language contrastive learning, we achieve 88.3% $\textit{zero-shot}$ and 91.1% $\textit{fine-tuning}$ accuracy on ImageNet, surpassing the previous best results by 2% and 0.1%, respectively. On diffusion models, Lion outperforms Adam by achieving a better FID score and reducing the training compute by up to 2.3x. For autoregressive, masked language modeling, and fine-tuning, Lion exhibits a similar or better performance compared to Adam. Our analysis of Lion reveals that its performance gain grows with the training batch size. It also requires a smaller learning rate than Adam due to the larger norm of the update produced by the sign function. Additionally, we examine the limitations of Lion and identify scenarios where its improvements are small or not statistically significant. The implementation of Lion is publicly available.
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Jun 22, 2022


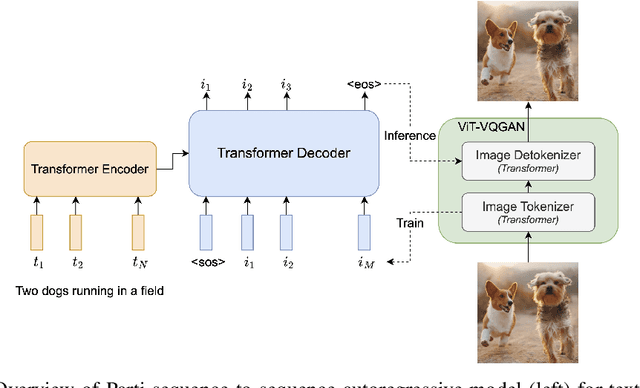
We present the Pathways Autoregressive Text-to-Image (Parti) model, which generates high-fidelity photorealistic images and supports content-rich synthesis involving complex compositions and world knowledge. Parti treats text-to-image generation as a sequence-to-sequence modeling problem, akin to machine translation, with sequences of image tokens as the target outputs rather than text tokens in another language. This strategy can naturally tap into the rich body of prior work on large language models, which have seen continued advances in capabilities and performance through scaling data and model sizes. Our approach is simple: First, Parti uses a Transformer-based image tokenizer, ViT-VQGAN, to encode images as sequences of discrete tokens. Second, we achieve consistent quality improvements by scaling the encoder-decoder Transformer model up to 20B parameters, with a new state-of-the-art zero-shot FID score of 7.23 and finetuned FID score of 3.22 on MS-COCO. Our detailed analysis on Localized Narratives as well as PartiPrompts (P2), a new holistic benchmark of over 1600 English prompts, demonstrate the effectiveness of Parti across a wide variety of categories and difficulty aspects. We also explore and highlight limitations of our models in order to define and exemplify key areas of focus for further improvements. See https://parti.research.google/ for high-resolution images.
Just Pick a Sign: Optimizing Deep Multitask Models with Gradient Sign Dropout
Oct 14, 2020



The vast majority of deep models use multiple gradient signals, typically corresponding to a sum of multiple loss terms, to update a shared set of trainable weights. However, these multiple updates can impede optimal training by pulling the model in conflicting directions. We present Gradient Sign Dropout (GradDrop), a probabilistic masking procedure which samples gradients at an activation layer based on their level of consistency. GradDrop is implemented as a simple deep layer that can be used in any deep net and synergizes with other gradient balancing approaches. We show that GradDrop outperforms the state-of-the-art multiloss methods within traditional multitask and transfer learning settings, and we discuss how GradDrop reveals links between optimal multiloss training and gradient stochasticity.