 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATEB: Evaluating and Improving Advanced NLP Tasks for Text Embedding Models
Feb 24, 2025
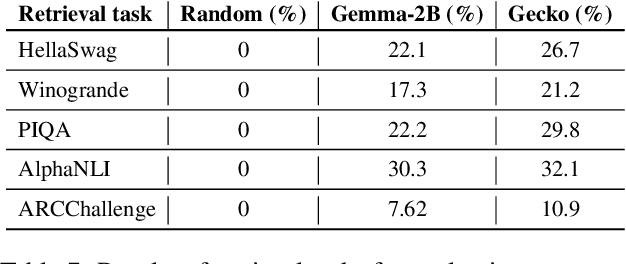
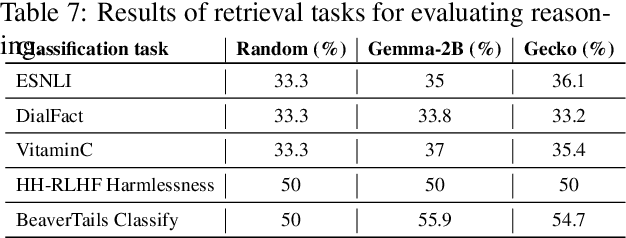

Traditional text embedding benchmarks primarily evaluate embedding models' capabilities to capture semantic similarity. However, more advanced NLP tasks require a deeper understanding of text, such as safety and factuality. These tasks demand an ability to comprehend and process complex information, often involving the handling of sensitive content, or the verification of factual statements against reliable sources. We introduce a new benchmark designed to assess and highlight the limitations of embedding models trained on existing information retrieval data mixtures on advanced capabilities, which include factuality, safety, instruction following, reasoning and document-level understanding. This benchmark includes a diverse set of tasks that simulate real-world scenarios where these capabilities are critical and leads to identification of the gaps of the currently advanced embedding models. Furthermore, we propose a novel method that reformulates these various tasks as retrieval tasks. By framing tasks like safety or factuality classification as retrieval problems, we leverage the strengths of retrieval models in capturing semantic relationships while also pushing them to develop a deeper understanding of context and content. Using this approach with single-task fine-tuning, we achieved performance gains of 8\% on factuality classification and 13\% on safety classification. Our code and data will be publicly available.
Foundational Autoraters: Taming Large Language Models for Better Automatic Evaluation
Jul 15, 2024As large language models (LLMs) advance, it becomes more challenging to reliably evaluate their output due to the high costs of human evaluation. To make progress towards better LLM autoraters, we introduce FLAMe, a family of Foundational Large Autorater Models. FLAMe is trained on our large and diverse collection of 100+ quality assessment tasks comprising 5M+ human judgments, curated and standardized using publicly released human evaluations from previous research. FLAMe significantly improves generalization to a wide variety of held-out tasks, outperforming LLMs trained on proprietary data like GPT-4 and Claude-3 on many tasks. We show that FLAMe can also serve as a powerful starting point for further downstream fine-tuning, using reward modeling evaluation as a case study (FLAMe-RM). Notably, on RewardBench, our FLAMe-RM-24B model (with an accuracy of 87.8%) is the top-performing generative model trained exclusively on permissively licensed data, outperforming both GPT-4-0125 (85.9%) and GPT-4o (84.7%). Additionally, we explore a more computationally efficient approach using a novel tail-patch fine-tuning strategy to optimize our FLAMe multitask mixture for reward modeling evaluation (FLAMe-Opt-RM), offering competitive RewardBench performance while requiring approximately 25x less training datapoints. Overall, our FLAMe variants outperform all popular proprietary LLM-as-a-Judge models we consider across 8 out of 12 autorater evaluation benchmarks, encompassing 53 quality assessment tasks, including RewardBench and LLM-AggreFact. Finally, our analysis reveals that FLAMe is significantly less biased than these LLM-as-a-Judge models on the CoBBLEr autorater bias benchmark, while effectively identifying high-quality responses for code generation.
FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation
Oct 05, 2023



Most large language models (LLMs) are trained once and never updated; thus, they lack the ability to dynamically adapt to our ever-changing world. In this work, we perform a detailed study of the factuality of LLM-generated text in the context of answering questions that test current world knowledge. Specifically, we introduce FreshQA, a novel dynamic QA benchmark encompassing a diverse range of question and answer types, including questions that require fast-changing world knowledge as well as questions with false premises that need to be debunked. We benchmark a diverse array of both closed and open-source LLMs under a two-mode evaluation procedure that allows us to measure both correctness and hallucination. Through human evaluations involving more than 50K judgments, we shed light on limitations of these models and demonstrate significant room for improvement: for instance, all models (regardless of model size) struggle on questions that involve fast-changing knowledge and false premises. Motivated by these results, we present FreshPrompt, a simple few-shot prompting method that substantially boosts the performance of an LLM on FreshQA by incorporating relevant and up-to-date information retrieved from a search engine into the prompt. Our experiments show that FreshPrompt outperforms both competing search engine-augmented prompting methods such as Self-Ask (Press et al., 2022) as well as commercial systems such as Perplexity.AI. Further analysis of FreshPrompt reveals that both the number of retrieved evidences and their order play a key role in influencing the correctness of LLM-generated answers. Additionally, instructing the LLM to generate concise and direct answers helps reduce hallucination compared to encouraging more verbose answers. To facilitate future work, we release FreshQA at github.com/freshllms/freshqa and commit to updating it at regular intervals.
PAWS-X: A Cross-lingual Adversarial Dataset for Paraphrase Identification
Aug 30, 2019



Most existing work on adversarial data generation focuses on English. For example, PAWS (Paraphrase Adversaries from Word Scrambling) consists of challenging English paraphrase identification pairs from Wikipedia and Quora. We remedy this gap with PAWS-X, a new dataset of 23,659 human translated PAWS evaluation pairs in six typologically distinct languages: French, Spanish, German, Chinese, Japanese, and Korean. We provide baseline numbers for three models with different capacity to capture non-local context and sentence structure, and using different multilingual training and evaluation regimes. Multilingual BERT fine-tuned on PAWS English plus machine-translated data performs the best, with a range of 83.1-90.8 accuracy across the non-English languages and an average accuracy gain of 23% over the next best model. PAWS-X shows the effectiveness of deep, multilingual pre-training while also leaving considerable headroom as a new challenge to drive multilingual research that better captures structure and contextual information.
Multilingual Universal Sentence Encoder for Semantic Retrieval
Jul 09, 2019We introduce two pre-trained retrieval focused multilingual sentence encoding models, respectively based on the Transformer and CNN model architectures. The models embed text from 16 languages into a single semantic space using a multi-task trained dual-encoder that learns tied representations using translation based bridge tasks (Chidambaram al., 2018). The models provide performance that is competitive with the state-of-the-art on: semantic retrieval (SR), translation pair bitext retrieval (BR) and retrieval question answering (ReQA). On English transfer learning tasks, our sentence-level embeddings approach, and in some cases exceed, the performance of monolingual, English only, sentence embedding models. Our models are made available for download on TensorFlow Hub.
Predicting Annotation Difficulty to Improve Task Routing and Model Performance for Biomedical Information Extraction
May 19, 2019
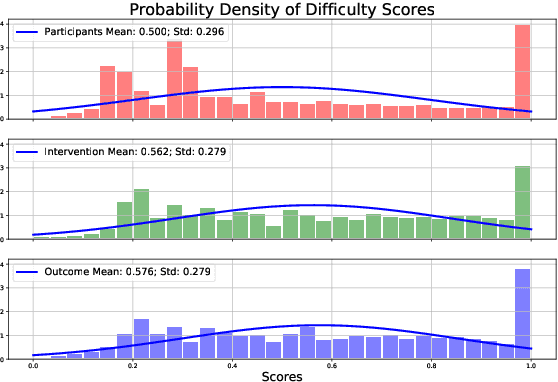
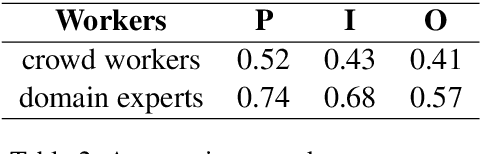

Modern NLP systems require high-quality annotated data. In specialized domains, expert annotations may be prohibitively expensive. An alternative is to rely on crowdsourcing to reduce costs at the risk of introducing noise. In this paper we demonstrate that directly modeling instance difficulty can be used to improve model performance, and to route instances to appropriate annotators. Our difficulty prediction model combines two learned representations: a `universal' encoder trained on out-of-domain data, and a task-specific encoder. Experiments on a complex biomedical information extraction task using expert and lay annotators show that: (i) simply excluding from the training data instances predicted to be difficult yields a small boost in performance; (ii) using difficulty scores to weight instances during training provides further, consistent gains; (iii) assigning instances predicted to be difficult to domain experts is an effective strategy for task routing. Our experiments confirm the expectation that for specialized tasks expert annotations are higher quality than crowd labels, and hence preferable to obtain if practical. Moreover, augmenting small amounts of expert data with a larger set of lay annotations leads to further improvements in model performance.
Universal Sentence Encoder
Apr 12, 2018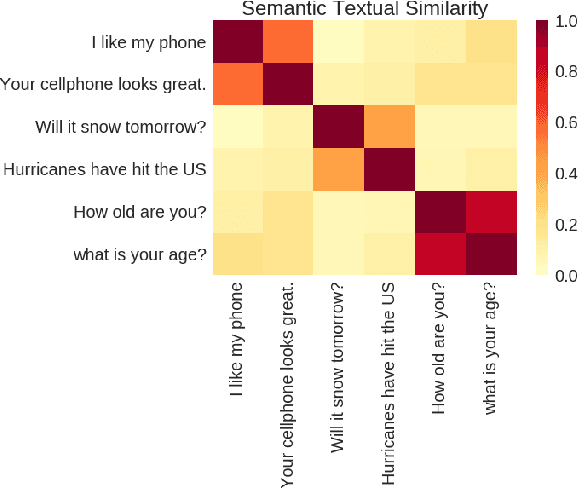
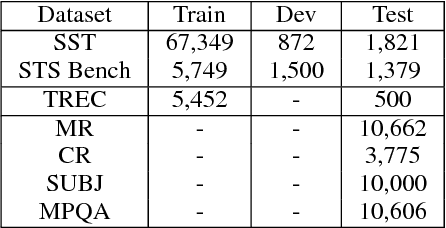
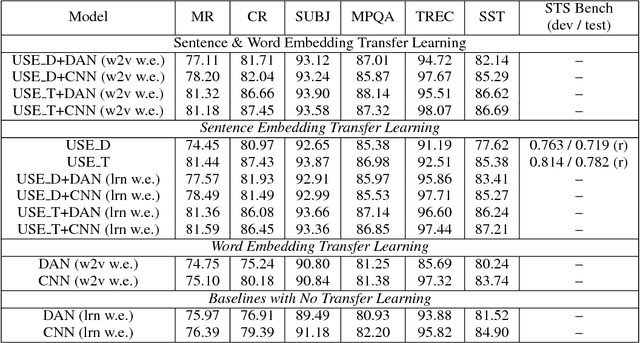
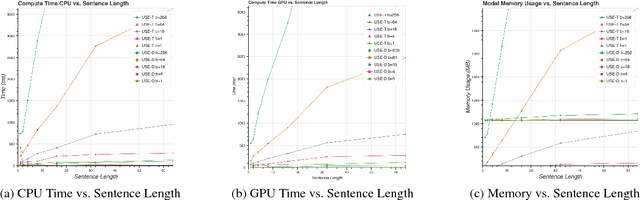
We present models for encoding sentences into embedding vectors that specifically target transfer learning to other NLP tasks. The models are efficient and result in accurate performance on diverse transfer tasks. Two variants of the encoding models allow for trade-offs between accuracy and compute resources. For both variants, we investigate and report the relationship between model complexity, resource consumption, the availability of transfer task training data, and task performance. Comparisons are made with baselines that use word level transfer learning via pretrained word embeddings as well as baselines do not use any transfer learning. We find that transfer learning using sentence embeddings tends to outperform word level transfer. With transfer learning via sentence embeddings, we observe surprisingly good performance with minimal amounts of supervised training data for a transfer task. We obtain encouraging results on Word Embedding Association Tests (WEAT) targeted at detecting model bias. Our pre-trained sentence encoding models are made freely available for download and on TF Hub.
A Growing Long-term Episodic & Semantic Memory
Oct 20, 2016
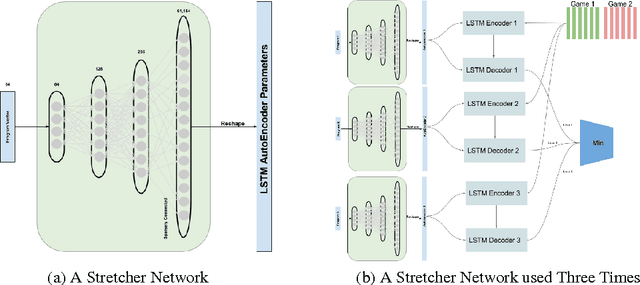
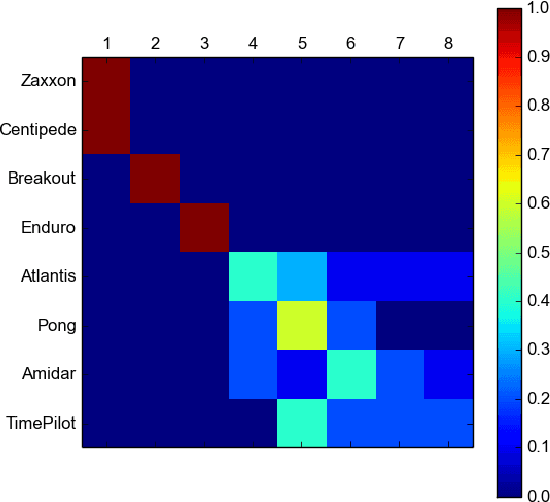
The long-term memory of most connectionist systems lies entirely in the weights of the system. Since the number of weights is typically fixed, this bounds the total amount of knowledge that can be learned and stored. Though this is not normally a problem for a neural network designed for a specific task, such a bound is undesirable for a system that continually learns over an open range of domains. To address this, we describe a lifelong learning system that leverages a fast, though non-differentiable, content-addressable memory which can be exploited to encode both a long history of sequential episodic knowledge and semantic knowledge over many episodes for an unbounded number of domains. This opens the door for investigation into transfer learning, and leveraging prior knowledge that has been learned over a lifetime of experiences to new domains.